






1、简述
在本文中,我们将介绍如何使用Docker快速、简便地安装RediSearch,Redis的全文搜索模块。RediSearch提供了高效的全文搜索功能,通过Docker安装,可以轻松地在任何环境中部署和管理RediSearch。
官网地址:https://github.com/RediSearch/RediSearch.git
2、性能
RediSearch是Redis的一个模块,用于实现全文搜索功能。它建立在Redis之上,利用其高性能和灵活性,为用户提供了快速、实时的搜索能力。RediSearch支持各种搜索功能,包括全文搜索、模糊搜索、排序、过滤等,适用于各种场景,如搜索引擎、内容管理系统、电子商务平台等。
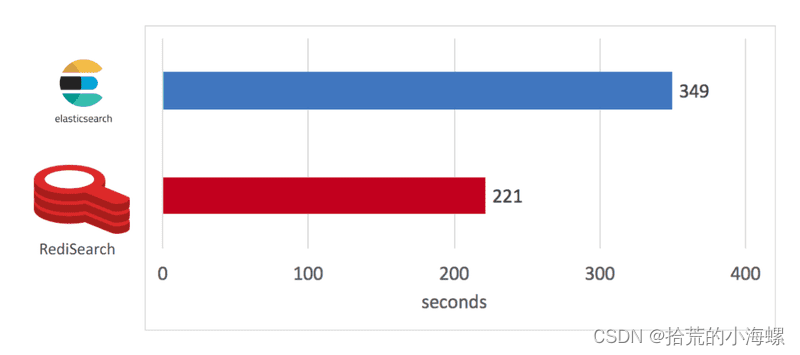
- 索引构建
在索引构建测试中,RediSearch 用221秒的速度超过了 Elasticsearch的349秒,领先58%。
- 查询性能
数据集建立索引后,我们使用运行在专用负载生成器服务器上的 32 个客户端启动了两个词的搜索查询。如下图所示,RediSearch 的吞吐量达到了 12.5K ops/sec,而 Elasticsearch 的吞吐量达到了 3.1K ops/sec,快了 4 倍。此外,RediSearch 的延迟稍好一些,平均为 8 毫秒,而 Elasticsearch 为 10 毫秒。
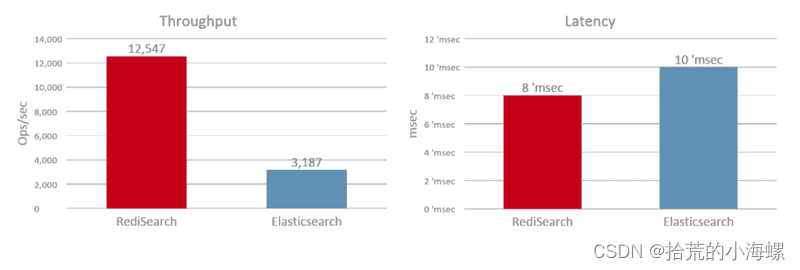
由此可见,RediSearch 在性能上对比 Elasticsearch 有比较大的优势。
3、安装
首先,确保您已经安装了Docker。然后,我们将通过Docker Hub上的官方RediSearch镜像来安装RediSearch。
打开终端或命令行界面,在其中运行以下命令来拉取RediSearch镜像:
docker pull redislabs/redisearch:latest
运行以下命令启动RediSearch容器:
docker run --name redis-search --restart=always -p 6379:6379 -d redislabs/redisearch:latest
或者
docker run -d --name redis-stack-server --restart=always -p 6379:6379 redis/redis-stack-server:latest
这条命令会从Docker Hub拉取最新版本的RediSearch镜像并在名为redis-search的容器中运行它。参数-p 6379:6379将容器内的6379端口映射到主机的6379端口上。
通过docker exec指令确认当前RediSearch安装是否成功:
[root@localhost ~]# docker exec -it redis-search /bin/bash
root@fb0aa7b3b11b:/data# redis-cli
127.0.0.1:6379> module list
1) 1) "name"
2) "search" # 查看是否包含search模块
3) "ver"
4) (integer) 20015
4、指令
RediSearch模块提供了一系列用于操作全文搜索索引的指令,以下是这些指令的详细解释及示例:
- FT.CREATE:创建一个新的全文搜索索引。
FT.CREATE index_name SCHEMA field1 type [field2 type ...]
示例:
FT.CREATE idx:goods on hash prefix 1 "goods:" language chinese schema goodsName text sortable
FT.CREATE 创建索引命令
idx:goods 索引名称
on hash 索引数据基于hash类型源数据构建
prefix 1 "goods:" 表示要创建索引的源数据前缀匹配规则
language chinese 表示支持中文语言分词
schema 表示字段定义,goodsName元数据属性名 text字段类型 sortable自持排序
- FT.ADD:向索引中添加一个新文档。
FT.ADD index_name document_id score [NOSAVE] [REPLACE] [LANGUAGE lang] [PAYLOAD payload]FIELDS field1 value1 [field2 value2 ...]
示例:
FT.ADD idx:goods doc1 1.0 FIELDS title "RedisSearch Introduction" body "RedisSearch is a full-text search engine built on top of Redis"
docId: 这里说是id并不代表只能说数字,可以是字符串。作为document的唯一标识。
score: 评分,类似于zset里的score,范围从0~1,如果不知道打多少可以默认打1。
NOSAVE:如果开启该选项我们不会在索引时保存真正的document。
REPLACE:更新或者插入,删除原本的document
PARTIAL (only applicable with REPLACE):在replace的时候指定对应的列
FIELDS: 字段对应create index时的schema
PAYLOAD {payload}: 在查询的时候使用,还不是太理解。。。
IF {condition}: 配合replace使用,对判断语句进行判断后决定是否生效replace e.g. FT.ADD idx doc 1 REPLACE IF "@timestamp < 23323234234".
LANGUAGE language: 指定语言,可以是中文:chinese
- FT.SEARCH:在索引中执行全文搜索。
FT.SEARCH index_name query [NOCONTENT] [VERBATIM] [NOSTOPWORDS] [WITHSCORES] [WITHSORTKEYS] [FILTER field value [field value ...]]
[GEOFILTER field lon lat radius m|km|mi|ft] [INKEYS num_keys key [key ...]] [INFIELDS num_fields field [field ...]]
[RETURN num_docs [ASC|DESC]] [SUMMARIZE [FIELDS num_fields field [field ...]] LEN len FRAGS frags]
[HIGHLIGHT [FIELDS num_fields field [field ...]] [TAGS open close] [FRAGS frags] [LEN len] [SEPARATOR sep] [MAXLEN len] [ELIPSIS ellipsis]]
[SLOP slop] [INORDER] [LANGUAGE lang] [EXPANDER expander] [SCORER scorer] [PAYLOAD]
示例:
FT.SEARCH idx:goods "RedisSearch"
- FT.AGGREGATE:在索引中执行聚合操作。
FT.AGGREGATE index_name query [LOAD [NUM num] [TERMS term [..]] [PROPERTIES prop [..]] [GROUPBY field [..]] [REDUCE reduce_function | REDUCER reduce_function]] [APPLY function [..]] [FILTER filter [..]] [SORTBY field [asc|desc] | MAX num [BY field [asc|desc]] [MAXTERMS num] [WITHCURSOR] [WITHFILTER] [WITHSORTKEYS]
示例:
FT.AGGREGATE idx:goods "*" GROUPBY 1 @title REDUCE COUNT 0 AS num_docs
- FT.INFO:获取索引的信息。
FT.INFO index_name
示例:
FT.INFO idx:goods
- FT.DROPINDEX:删除指定的索引。
FT.DROPINDEX index_name [DD]
示例:
FT.DROPINDEX idx:goods
以上是RediSearch模块中常用的指令及其详细解释和示例。通过这些指令,您可以在Redis中轻松构建和管理全文搜索索引,并执行各种搜索和聚合操作。
5、应用
接下来,我们将展示如何使用Java来连接到RediSearch并进行查询。我们将使用Jedis作为Redis的Java客户端库,确保您已经将其添加到项目依赖中:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
//jedis 4.0以上版本就默认支持RediSearch
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.0</version>
</dependency>
以下是一个简单的Java类,演示了如何连接到RediSearch并执行一个简单的全文搜索查询:
package com.example.lkfy.example;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.springframework.beans.factory.annotation.Autowired;
import redis.clients.jedis.*;
import redis.clients.jedis.search.*;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class RedisSearchExample {
public static final String GOODS_IDX_PREFIX = "idx:goods:";
@Autowired
private UnifiedJedis client;
public RedisSearchExample() {
GenericObjectPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxWaitMillis(3000);
jedisPoolConfig.setJmxEnabled(false);
client = new JedisPooled(jedisPoolConfig, "192.168.157.128", 6379, 1000, "123456",0);
}
/**
* 新增索引数据
*/
private void hset(String keyPrefix, Map<String, String> hash) {
// 支持中文
hash.put("_language", "chinese");
client.hset(keyPrefix, hash);
}
/**
* 查询索引列表
*/
public Set<String> listIndex() {
return client.ftList();
}
/**
* 创建索引
*
* @param idxName 索引名称
* @param prefix 要索引的数据前缀
* @param schema 索引字段配置
*/
public void createIndex(String idxName, String prefix, Schema schema) {
IndexDefinition rule = new IndexDefinition(IndexDefinition.Type.HASH)
.setPrefixes(prefix)
.setLanguage("chinese");
client.ftCreate(idxName,
IndexOptions.defaultOptions().setDefinition(rule),
schema);
}
/**
* 查询
*
* @param idxName 索引名称
* @param search 查询key
* @param sort 排序字段
* @return searchResult
*/
public SearchResult query(String idxName, String search, String sort) {
Query q = new Query(search);
if (StringUtils.isNotBlank(sort)) {
q.setSortBy(sort, false);
}
q.setLanguage("chinese");
q.limit(0, 10);
return client.ftSearch(idxName, q);
}
public static void main(String[] args) {
RedisSearchExample example = new RedisSearchExample();
String id ="1";
Map<String, String> hash = new HashMap<>();
hash.put("id",id);
hash.put("goodsName","你好hello");
example.hset("idx:goods" , hash );
SearchResult searchResult = example.query("idx:goods","*", null);
System.out.println(searchResult.toString());
}
}
6、优点和场景
RediSearch是Redis的全文搜索模块,具有以下优点和适用场景:
6.1 优点
- 快速高效: RediSearch基于倒排索引实现,具有高效的全文搜索能力,能够快速地处理大量文本数据。
- 与Redis集成: RediSearch是作为Redis模块而不是单独的软件包提供的,因此可以与现有的Redis部署集成,无需额外的基础设施或管理开销。
- 分布式支持: RediSearch支持分布式部署,可以水平扩展以处理大量的搜索请求。
- 丰富的搜索功能: 提供了丰富的搜索功能,包括全文搜索、模糊搜索、排序、过滤等,能够满足各种搜索需求。
- 实时索引更新: 支持实时索引更新,可以在数据变更时立即更新索引,保持搜索结果的实时性。
- 轻量级: RediSearch是一个轻量级的模块,易于安装、部署和管理。
6.2 应用场景:
- 实时搜索引擎: 适用于构建实时搜索引擎,能够快速地处理用户的搜索请求,并返回相关的搜索结果。
- 内容管理系统: 可以用于构建内容管理系统,支持对大量文本数据进行全文搜索、过滤和排序。
- 电子商务平台: 用于构建电子商务平台的搜索功能,支持商品搜索、过滤和排序,提供更好的用户搜索体验。
- 社交网络: 适用于构建社交网络平台,支持用户搜索、内容搜索等功能。
- 日志分析: 可以用于实时分析和搜索日志数据,支持日志检索、过滤和分析。
- 实时推荐系统: 用于构建实时推荐系统,支持对用户喜好进行实时搜索和推荐。
总的来说,RediSearch具有高效、快速、易于集成和扩展的特点,适用于各种需要全文搜索功能的应用场景。
7、总结
通过本文,您学习了如何使用Docker快速、简便地安装RediSearch。RediSearch是Redis的全文搜索模块,提供了高效、实时的全文搜索功能,适用于各种场景。使用Docker安装RediSearch可以轻松地在任何环境中部署和管理RediSearch,为您的应用程序提供强大的全文搜索能力。希望本文对您有所帮助!

















 3560
3560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











