






Ollama本地部署 Win11 intel arc 显卡GPU加速
环境
- 支持c++开发
- 存在conda(miniconda, anaconda)都可
- 已部署ollama (没有的话可以先 部署本地Ollama)
步骤
- 管理员身份运行anaconda prompt
开个llm环境
conda create -n llm python=3.11 libuv
激活环境
conda activate llm
安装 dpcpp-cpp-rt, mkl-dpcpp, 和 onednn 这些特定版本的包
pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
安装 Intel 的 ipex-llm 包及其 XPU 支持的预发布版本
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/
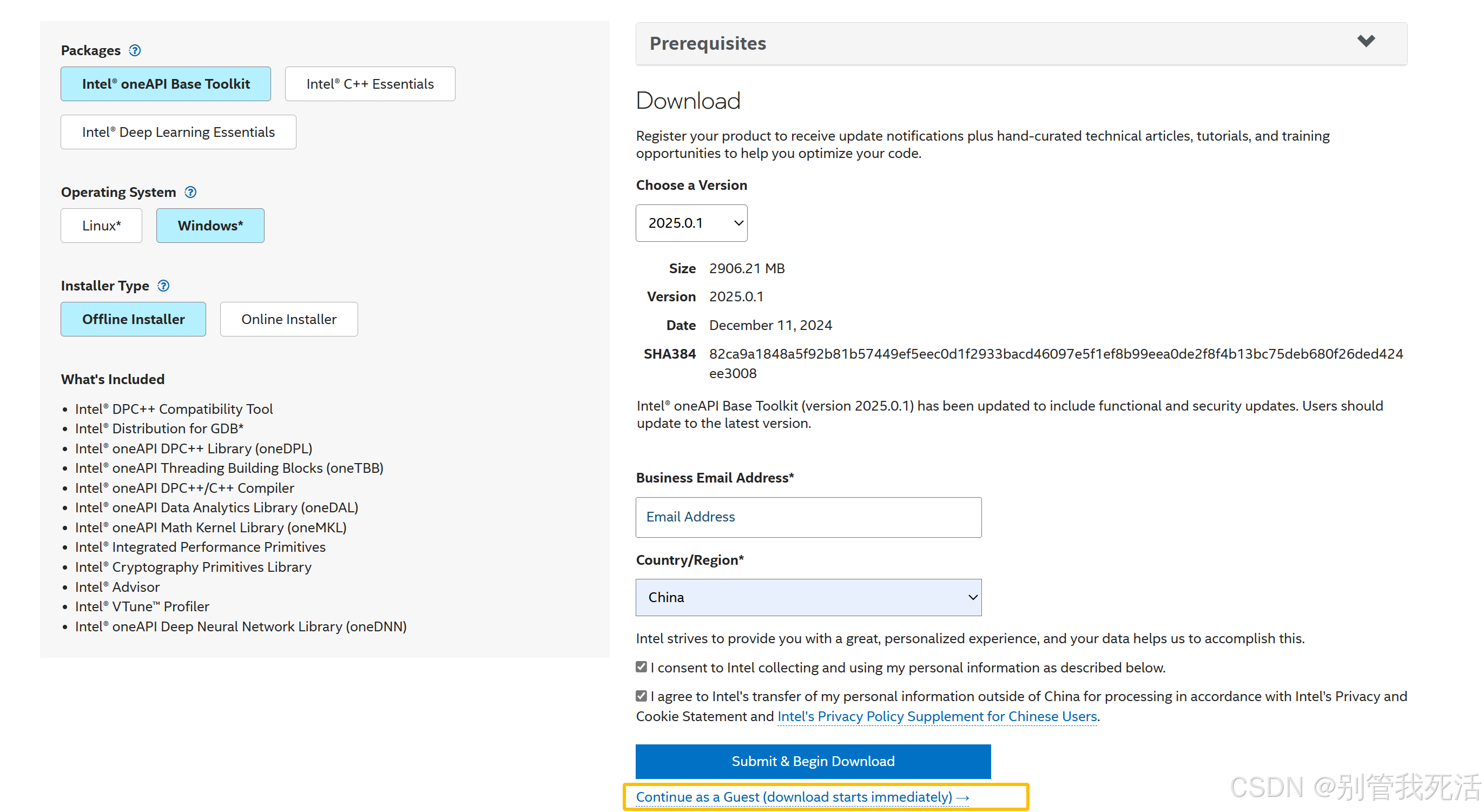
- 下载IntelOneApi
Get the Intel® oneAPI Base Toolkit
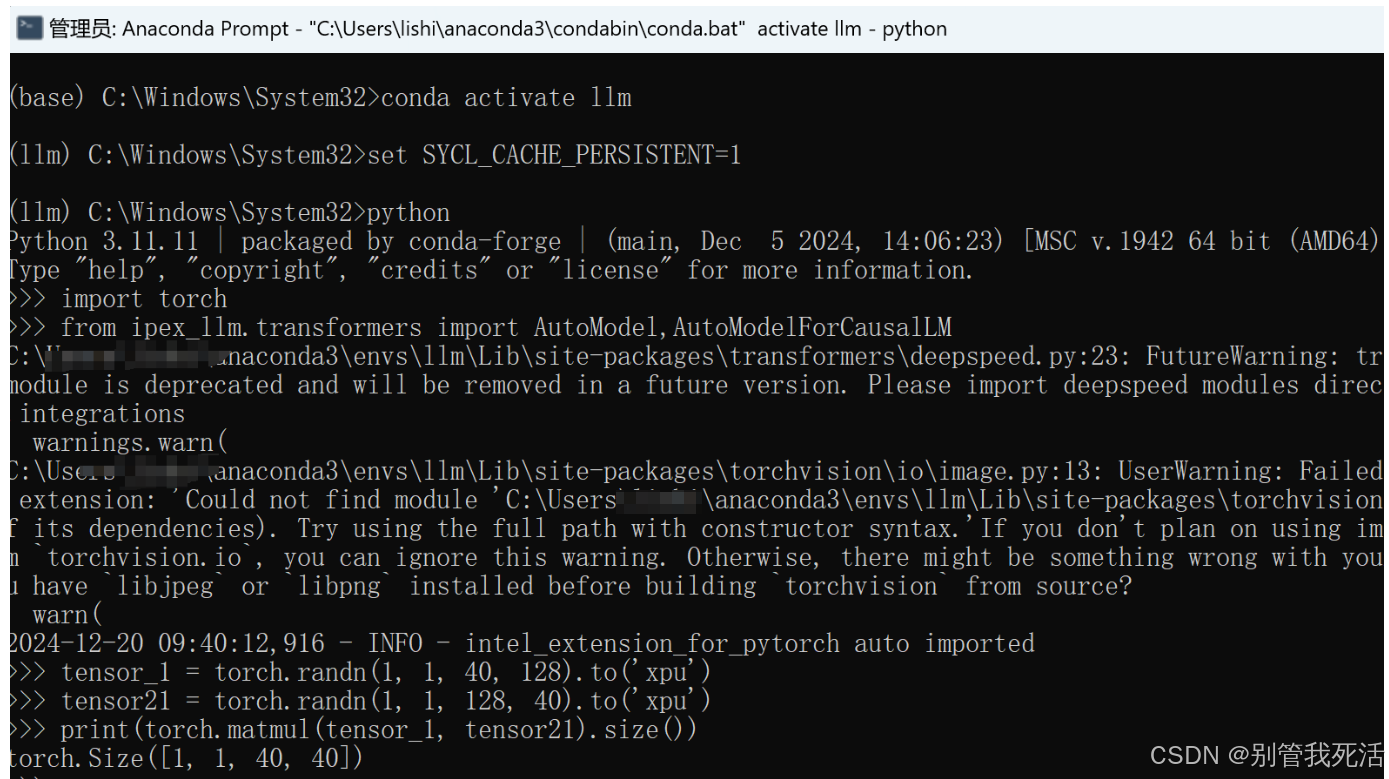
3.验证安装
>>> conda activate llm
>>> set SYCL_CACHE_PERSISTENT=1
>>> python
>>>import torch
from ipex_llm.transformers import AutoModel,AutoModelForCausalLM
tensor_1 = torch.randn(1, 1, 40, 128).to('xpu')
tensor_2 = torch.randn(1, 1, 128, 40).to('xpu')
print(torch.matmul(tensor_1, tensor_2).size())
成功的话结果如下:
>>> torch.Size([1, 1, 40, 40])
4.创造llm-cpp环境 配置并运行IPEX-LLM for llama.cpp
>>> conda create -n llm-cpp python=3.11
>>> conda activate llm-cpp
>>> pip install --pre --upgrade ipex-llm[cpp]
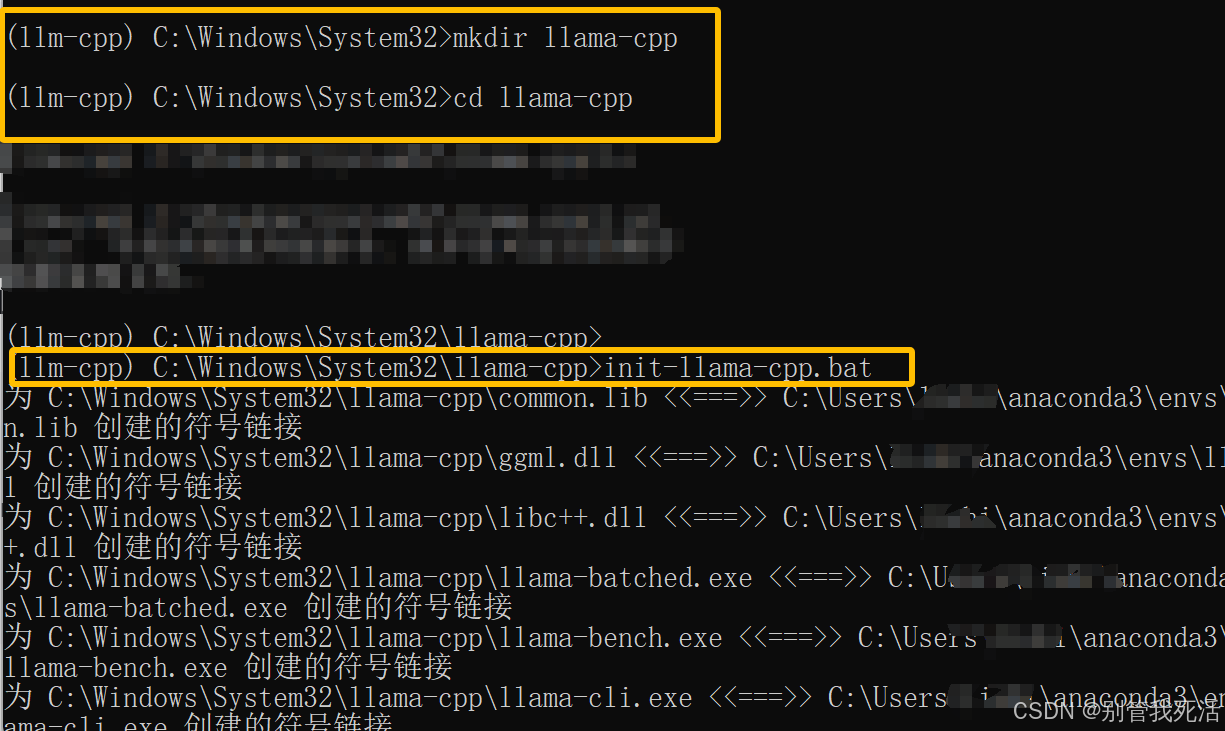
>>> mkdir llama-cpp
>>> cd llama-cpp
初始化 llama.cpp with IPEX-LLM
init-llama-cpp.bat
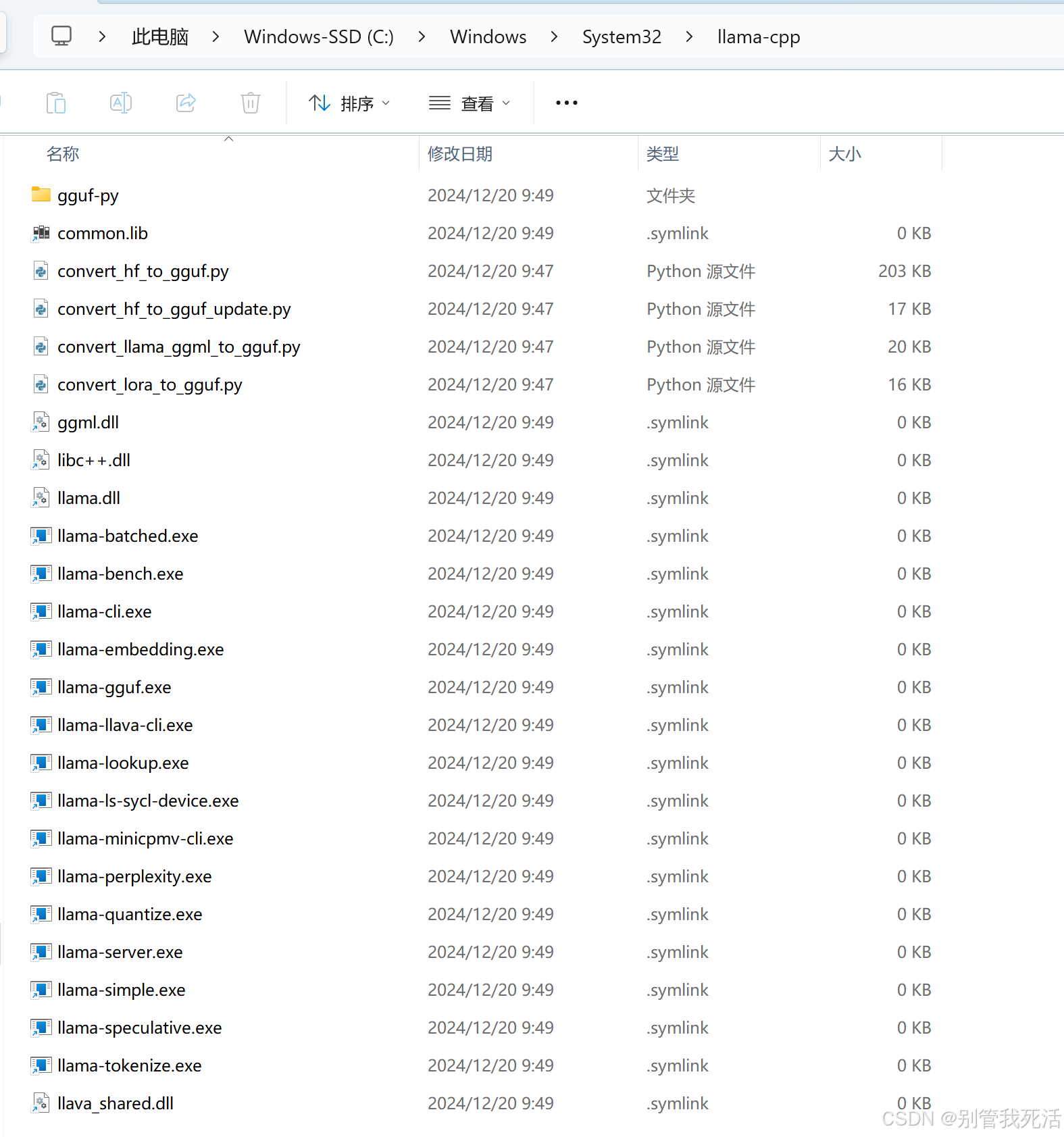
出现复制一堆软链接文件,到该目录下会看到
以上完成后,可以到对应的目录下面看到一堆软连接。
>>> init-ollama.bat
>>> set OLLAMA_NUM_GPU=999
>>> set no_proxy=localhost,127.0.0.1
>>> set ZES_ENABLE_SYSMAN=1
>>> set OLLAMA_HOST=0.0.0.0
>>> ollama serve
运行后该窗口不要关闭!!!!
新开一个anaconda窗口
ollama run llama3
开启问答模式,速度比之前快了一些
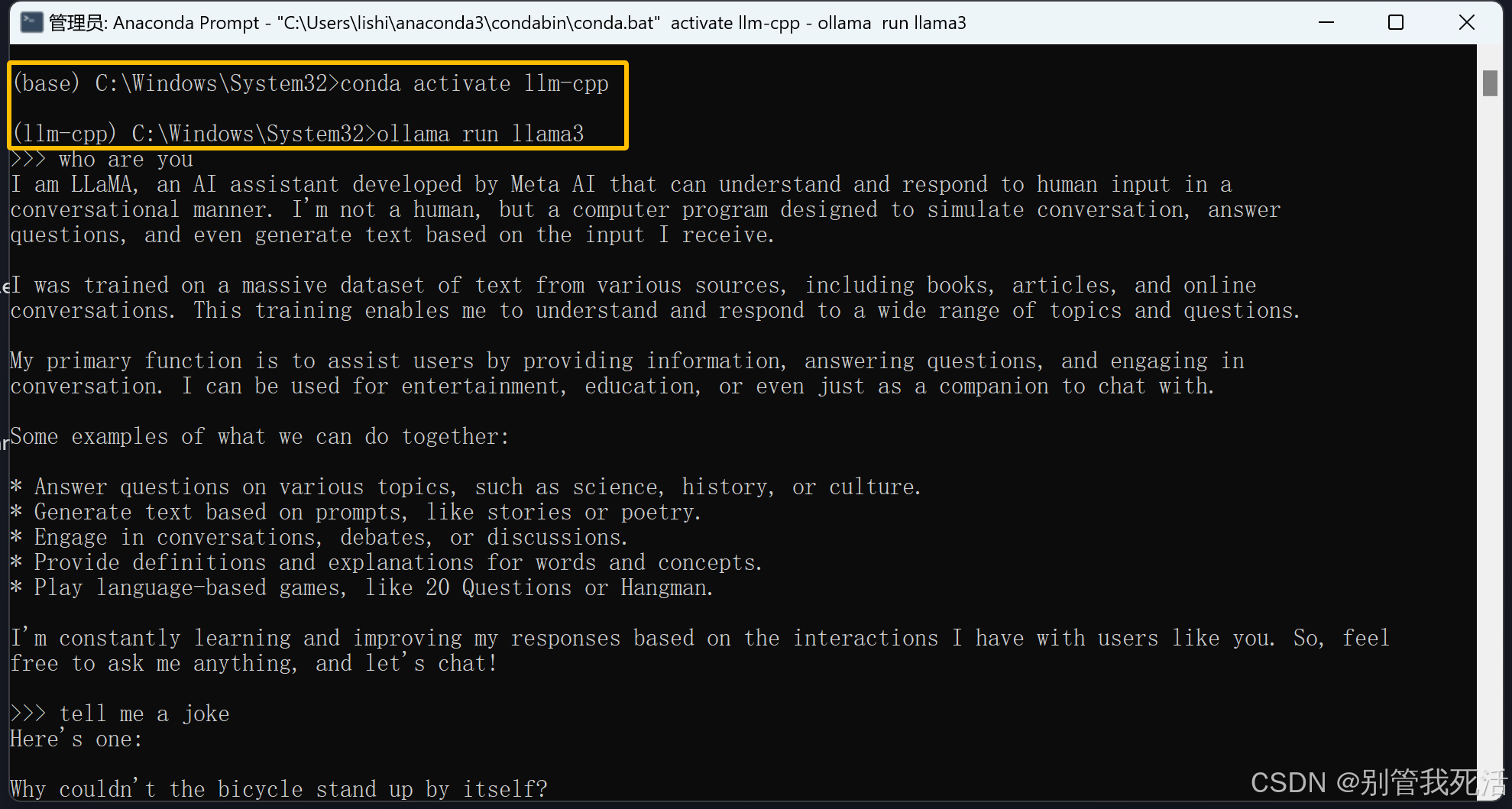
搬运来源:https://zhuanlan.zhihu.com/p/694516502
参考资料:https://test-bigdl-llm.readthedocs.io/en/main/doc/LLM/Quickstart/ollama_quickstart.html

















 2292
2292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









