







频繁模式:是频繁得出现在数据集中的模式;频繁项集导致发现大型事物或者数据集之间有趣的关联或相关性,频繁项集挖掘的一个典型案例是购物篮分析,该过程通过发现顾客放入他们的购物篮中的商品之间的关系,分析客户的购物习惯;
下面了解频繁模式中的相关概念
频繁数据集:购物篮数据
频繁模式:频繁地出现在数据集中的模式,例如项集,子结构
关联规则:反应商品频繁关系;例如 牛奶=>鸡蛋【支持度=2%,置信度=60%】
支持度:频繁数据集中支持这个关联关系的比例,上例支持度=2%:频繁数据集中牛奶和鸡蛋同时出现的比例为2%;
置信度:买牛奶中有60%买了鸡蛋;反映数据的确定性;
支持度和置信度总结如下:
A=>B【支持度=a,置信度=b】
支持度(A=>B)=P(A+B)的概率
置信度 (A=>B)=P(B|A)的概率
最小支持度阈值和最小置信度阀值(可以是百分比也可以个整数);
项集:项(商品)的集合,一个购物中的商品可以随机组成项集;
K-项集:由K个项组成的项集,及K个商品组成的项集;
频繁项集:满足最小支持度和项集
强关联规则:满足最小支持度和最小置信度的规则
Apriori算法:
步骤:
一:找出所有的频繁项集;
二:由频繁项集产生强关联关系(这些规则必须满足最小支持度和置信度)
下面就以一下例子说明:
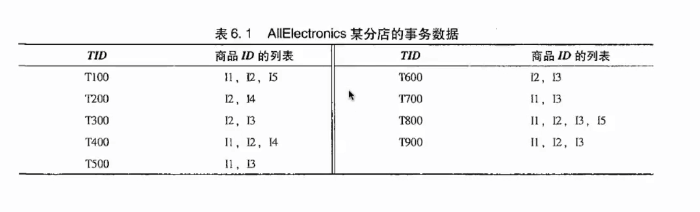
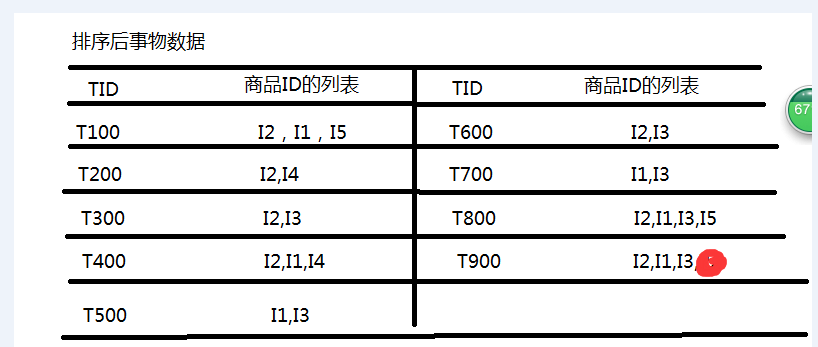
以上TID代表事物ID,数据事物数为9;并设置支持度为2;
备注:1:一个频繁项集它的子项集一定是频繁项集
2:若一个子集不是频繁项集那它的父集一定不是频繁项集
下面就对频繁项集进行描述:
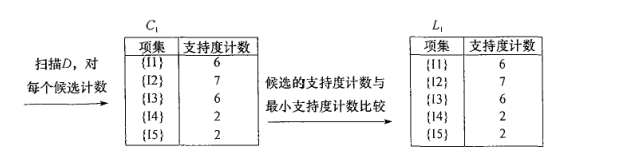
第一次扫描如下图:得到频繁1项的集合为L1,并支持度都是大于2的
第二次通过连接算出频繁2项的集合(连接条件:两个K项集合必须保证他们前k-1项相同才能连接,比如L2=[I2,I3],另外一个L2=[I2,I5],那边这两个项集可以连接成频繁3项集为L3=【I2,I3,I5】)如下图:
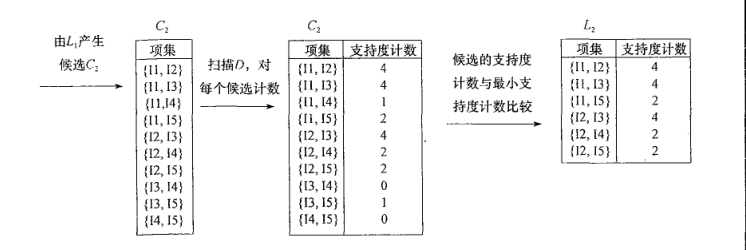
由L1产生C2备选集合,然后扫描所有事物数据算出支持度,然后剪枝掉支持度小于2的项集,剩下L2频繁项集;两项频繁项集可以作为输出了;
第三次输出3项频繁集,如下:按照连接也会出现[I1,I3,I5],但[I3,I5] 不是频繁项集,根据备注2原则,被删除,故三项频繁项集就是L3;

以上步骤就求出了频繁项集,提取关联规则

随着上面的步骤可以看出,越往后计算越少,但每次计算后都要重新扫描一下数据集计算候选集的支持度,效率不高;下面就介绍一个高效的FP-growth算法,此算法基于FP-tree算法;
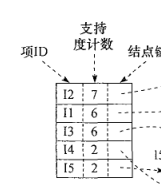
此算法第一步,算出每个商品的支持度:如下图
第二步然后把所有的事物数据按支持度进行排序,排序后的数据篮子如下图:
第二步建立FP-TREE树;建立规则如下
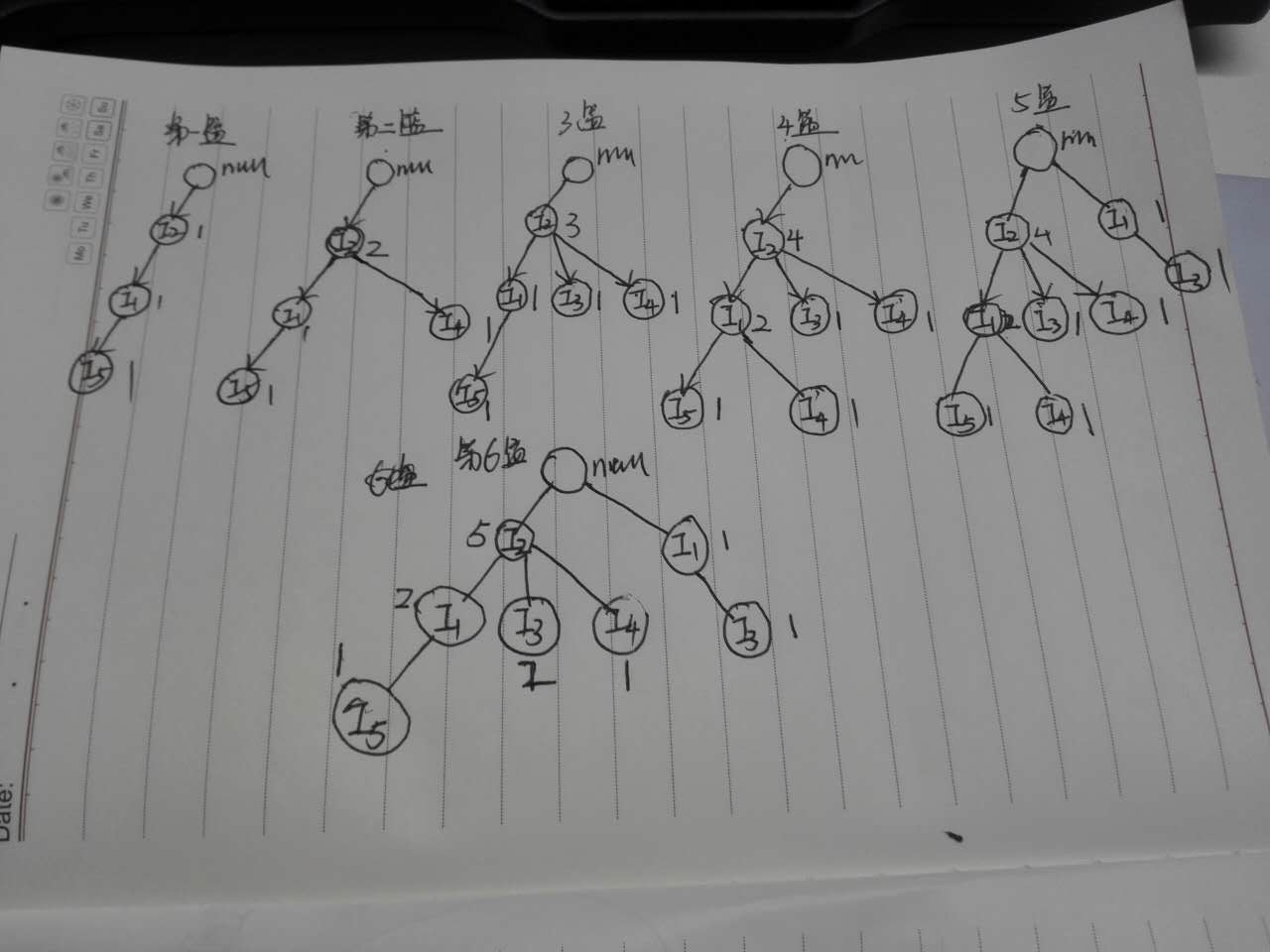
把排序后指针指向FP树,如下图显示
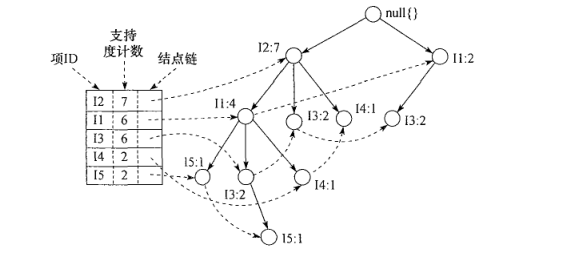
FP数的挖掘过程:
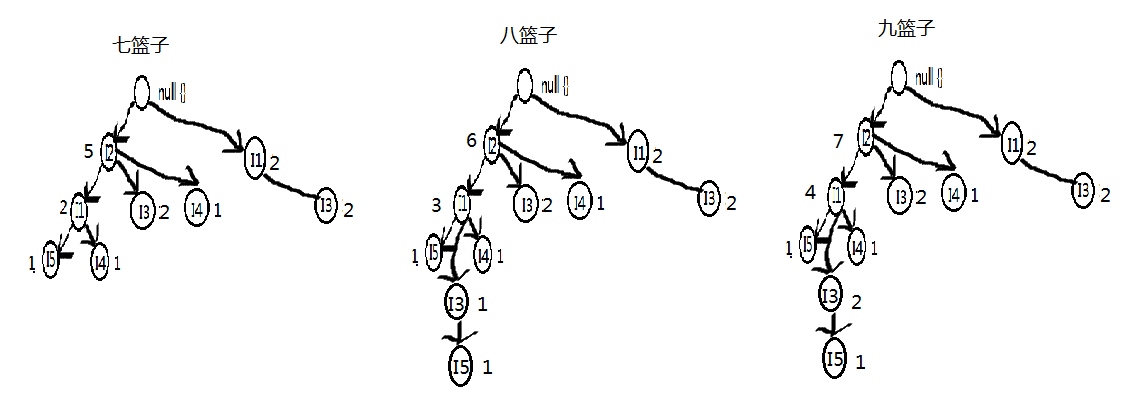
1:从1项集排序的最后一个项集开始遍历,比如I5的支持度为2,排序在最后,就由I5开始;首先获取I5条件模式基;
获取I5的条件模式基的方法,首先从I5开始往根部节点遍历,可以获取两个频繁项集;一个是【I2,I1,I5】出现次数为1;一个是【I2,I1,I3,I5】出现的次数为1;故I5的条件模式基为【I2,I1 : 1】(1代表出现频次)和【I2,I1,I3 : 1】;再由条件模式基获取条件FP树,由下图生成:
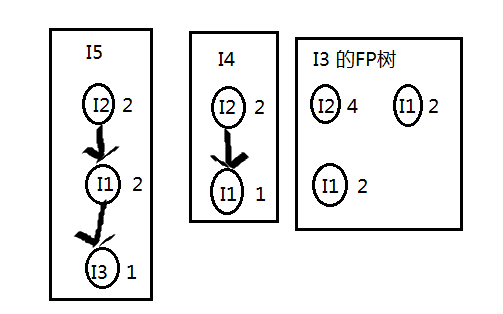
删除支持度小于2的商品,最后频繁模式如下:
















 3710
3710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









