







rank 是模型中隐语义因子的个数。
iterations 是迭代的次数。
lambda 是ALS的正则化参数。
implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准;
Mlib 中的explicit 和implicit
在实际的应用场景中,我们一般能获取的数据很少是客户显性偏好(客户对商品的评分),在通常的场景中我们可能可以获取的数据用隐形客户偏好(比如点击,浏览,购买数,分享);实际上推荐通常使用的就是这些代表用户倾向的隐性特征;关于此知识点可以参考http://blog.csdn.net/lingerlanlan/article/details/46917601
为了更好的了解协同过滤系统中使用的算法原理,我们先了解一下ASL;
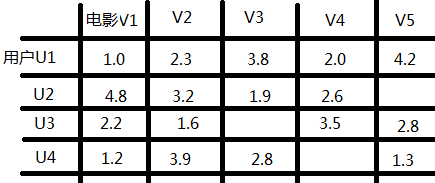
ALS是alternating least squares的缩写 , 意为交替最小二乘法;而ALS-WR是alternating-least-squares with weighted-λ -regularization的缩写,意为加权正则化交替最小二乘法。该方法常用于基于矩阵分解的推荐系统中;比如在用户对商品的评分矩阵,可以分解为一个用户对隐含特征偏好的矩阵,一个是商品所包含的隐含特征的矩阵;对于R(m×n)的矩阵,ALS旨在找到两个低维矩阵X(m×k)和矩阵Y(n×k),来近似逼近R(m×n),在这过程中把用户评分缺失项填上,并根据这个分数给用户推荐;即公式如下
把一个高维矩阵写成两个低位矩阵的相识乘积,比如上图用户对商品的打分矩阵,矩阵Y可以理解为把电影映射到低维的特征上,比如科幻、爱情、武侠、恐怖;
为了尽可以找到逼近的X,Y矩阵,下面就是优化平方误差公式:

其中rui表示用户u对商品i的评分,xu(1×k)表示示用户u的偏好的隐含特征向量,yi(1×k)表示商品i包含的隐含特征向量, 向量x和yi的内积xuTyi是用户u对商品i评分的近似。
损失函数一般需要加入正则化项来避免过拟合等问题,我们使用L2正则化,所以上面的公式改造为:
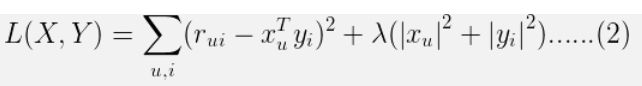
这样,协同过滤就转化为优化问题了,上面式子因为X和Y耦合在一起很难解。这就要引入交替二乘法,其主旨就是先固定X,求Y,迭代至收敛;然后固定Y求X;

ALS-WR
上文提到的模型适用于解决有明确评分矩阵的应用场景,然而很多情况下,用户没有明确反馈对商品的偏好,也就是没有直接打分,我们只能通过用户的某些行为来推断他对商品的偏好。比如,在电视节目推荐的问题中,对电视节目收看的次数或者时长,这时我们可以推测次数越多,看得时间越长,用户的偏好程度越高,但是对于没有收看的节目,可能是由于用户不知道有该节目,或者没有途径获取该节目,我们不能确定的推测用户不喜欢该节目。ALS-WR通过置信度权重来解决这些问题:对于更确信用户偏好的项赋以较大的权重,对于没有反馈的项,赋以较小的权重。ALS-WR模型的形式化说明如下:
- ALS-WR的目标函数:

其中α是置信度系数。
- 求解方式还是最小二乘法:
 其中Cu是n×n的对角矩阵,Ci是m×m的对角矩阵;Cuii = cui, Ciii = cii。
其中Cu是n×n的对角矩阵,Ci是m×m的对角矩阵;Cuii = cui, Ciii = cii。
然后按ALS求解步骤求解就可以了;
下面就使用sparkmlib实现一个推荐系统,直接上代码:
训练集数据样本样式:
第一个字段为用户ID,第二个字段为电影ID,第三个地段为评分,第四个字段为
0::2::3::1424380312
0::3::1::1424380312
0::5::2::1424380312
0::9::4::1424380312
0::11::1::1424380312
0::12::2::1424380312
0::15::1::1424380312
0::17::1::1424380312
1::2::2::1424380312
1::3::1::1424380312
1::4::2::1424380312
1::6::1::1424380312
1::9::3::1424380312
1::12::1::1424380312
1::13::1::1424380312
public class MovieBean implements Serializable {
private static final long serialVersionUID = 1L;
private int userId;
private int movieId;
private float rating;
private long timestamp;
public int getUserId() {
return userId;
}
public void setUserId(int userId) {
this.userId = userId;
}
public int getMovieId() {
return movieId;
}
public void setMovieId(int movieId) {
this.movieId = movieId;
}
public float getRating() {
return rating;
}
public void setRating(float rating) {
this.rating = rating;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
@Override
public String toString() {
return "MovieBean [userId=" + userId + ", movieId=" + movieId + ", rating=" + rating + ", timestamp="
+ timestamp + "]";
}
public MovieBean(int userId, int movieId, float rating, long timestamp) {
super();
this.userId = userId;
this.movieId = movieId;
this.rating = rating;
this.timestamp = timestamp;
}
public MovieBean(int userId, int movieId) {
super();
this.userId = userId;
this.movieId = movieId;
}
}模型实现如下:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession
.builder()
.appName("als").master("local[1]")
.getOrCreate();
JavaRDD<MovieBean> movieData = sparkSession.read()
.textFile("E:/sparkMlib/sparkMlib/src/mllib/als/sample_movielens_ratings.txt")
.javaRDD()
.map(new Function<String,MovieBean>(){
public MovieBean call(String line) throws Exception {
String[]fields = line.split("::");
if(fields.length !=4){
throw new Exception();
}
int userId = Integer.parseInt(fields[0]);
int movieId = Integer.parseInt(fields[1]);
float rating = Float.parseFloat(fields[2]);
long timestamp = Long.parseLong(fields[3]);
return new MovieBean(userId,movieId,rating,timestamp);
}});
Dataset<Row> ratingData = sparkSession.createDataFrame(movieData, MovieBean.class);
//把数据集话分为训练集和测试集
Dataset<Row>[] splits = ratingData.randomSplit(new double[]{0.8, 0.2});
Dataset<Row> training = splits[0];
Dataset<Row> test = splits[1];
// Build the recommendation model using ALS on the training data
ALS als =new ALS()
.setMaxIter(2)//设置迭代次数
.setRank(10)//设置隐形特征个
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating");
ALSModel model = als.fit(training);//训练模型
// Evaluate the model by computing the RMSE on the test data
Dataset<Row> predictions = model.transform(test);
System.out.println(predictions.schema());
for(Row r:predictions.select("userId", "movieId", "rating", "prediction").sort("prediction").collectAsList()){
System.out.println(r.get(0)+":"+r.get(1)+":"+r.get(2)+":"+r.get(3));
}
RegressionEvaluator evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction");
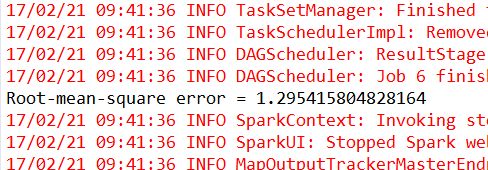
Double rmse = evaluator.evaluate(predictions);
System.out.println("Root-mean-square error = " + rmse);
} 
借鉴 https://github.com/ceys/jdml/wiki/ALS















 6465
6465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









