







首先申明:引用此博客为学习记录用,中间引用了Andrew NG的视频内容和Z老师的授课内容,因个人能力有限若有不足的地方,欢迎大家提出一起研究学习;
第一我们先给予逻辑回归的定义:逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。
对于初学者一般很难分清线性回归和逻辑回归区别和联系;虽然逻辑回归和线性回归名字中带有回归二字,但逻辑回归很少用来作为预测,更多的是作为分类用;当然线性回归一般都用来做预测,几乎不用来做分类用;但话说回来,线性回归也可以作为分类;比如Andrew NG在视频举了下面一个例子:
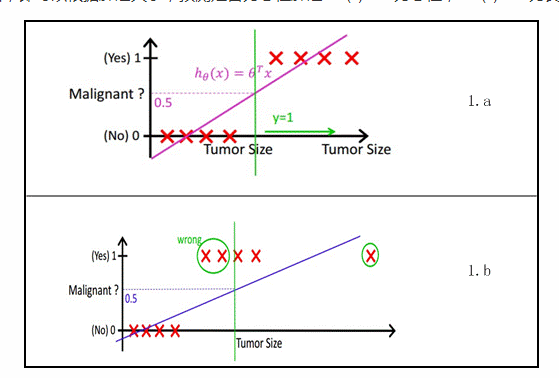
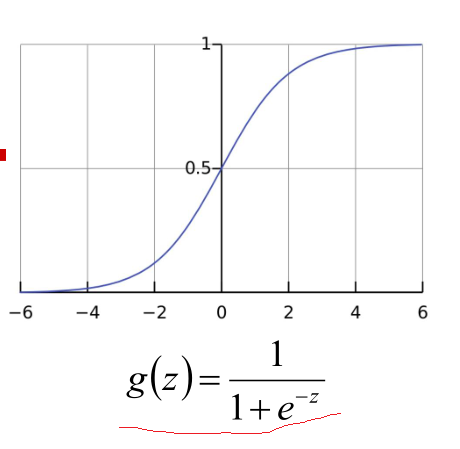
例子中:x轴为肿瘤的大小,y轴为肿瘤为恶性的概率;当如1.b图中按0.5的概率划分的时候,会把单独绿色圈的大尺寸的肿瘤化为良性的,就会出现严重的误诊情况;由上可以知道线性回归的鲁棒性很差,例如在图1.b的数据集上建立回归,因最右边噪点的存在,使回归模型在训练集上表现都很差。这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型;其回归曲线用Sigmoid 函数:
并且此函数有个有趣的现象,就是对此函数求导后,你会发现,导数就是:
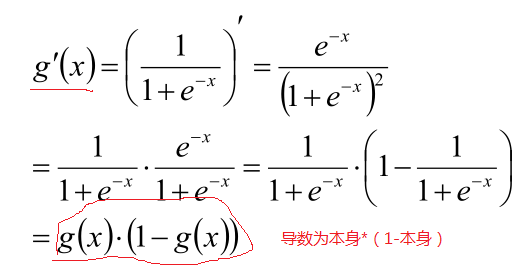
现在假定:
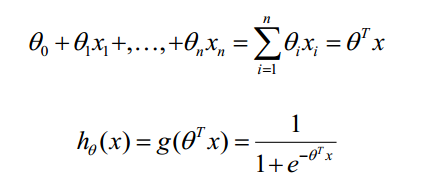

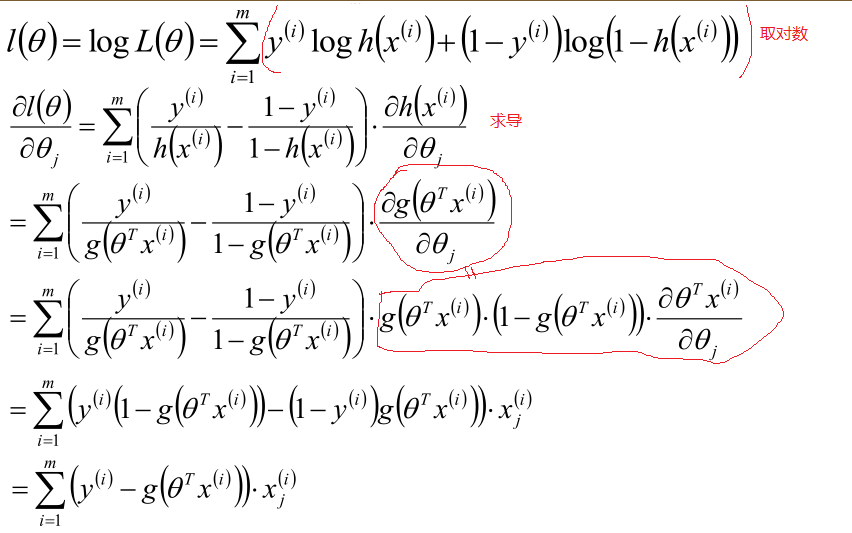
以上就求出每个参数θ的梯度方向,下面就可以使用梯度下降方法优化
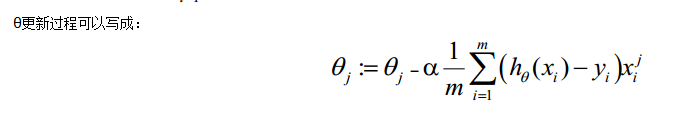
对于逻辑回归我们可以说它是个广义的线性模型,或者是对数线性模型:下面我们就对此说法进行说明:
一个事件的几率 odds:就是该事件发生的概率和不发生概率的比值;

以上就对逻辑分类原理简单介绍一下;下面直接上个代码看看效果:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler,PolynomialFeatures
import matplotlib as mpl
import matplotlib.patches as mpatches
import matplotlib.pyplot as plt
if __name__ == "__main__":
path = 'iris.data' # 数据文件路径
data = pd.read_csv(path,header=None)
data[4] = pd.Categorical(data[4]).codes
x, y = np.split(data.values, (4,), axis=1)
np.set_printoptions(suppress=True)
x = x[:,:2]
logicR = Pipeline([
('sc',StandardScaler()),
('poly',PolynomialFeatures(degree=2)),
('clf',LogisticRegression())
])
logicR.fit(x,y.ravel())
y_hat = logicR.predict(x)
y_hat_prob = logicR.predict_proba(x)
print 'y_hat = \n',y_hat
print 'y_hat_prob = \n',y_hat_prob
N ,M =500,500
x1_min,x1_max = x[:,0].min(),x[:,0].max()
x2_min,x2_max = x[:,1].min(),x[:,1].max()
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1)
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = logicR.predict(x_test)
y_hat = y_hat.reshape(x1.shape)
plt.figure(facecolor='w')
plt.pcolormesh(x1,x2,y_hat,cmap =cm_light)
plt.scatter(x[:,0],x[:,1],c =y,edgecolors='k',s =50,cmap=cm_dark)
plt.xlabel(u'花萼长度', fontsize=14)
plt.ylabel(u'花萼宽度', fontsize=14)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
patchs = [mpatches.Patch(color='#77E0A0', label='Iris-setosa'),
mpatches.Patch(color='#FF8080', label='Iris-versicolor'),
mpatches.Patch(color='#A0A0FF', label='Iris-virginica')]
plt.legend(handles=patchs, fancybox=True, framealpha=0.8)
plt.title(u'鸢尾花Logistic回归分类效果 - 标准化', fontsize=17)
plt.show()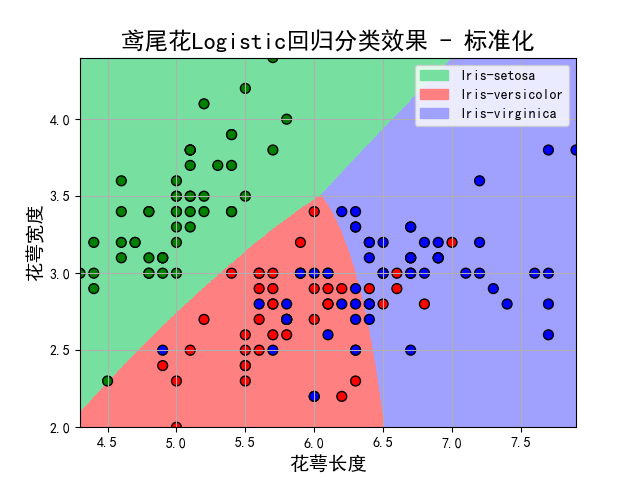















 1910
1910











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









