







AttGAN:Facial Attribute Editing by Only Changing What You Want(2017 CVPR)
文章简介
本文研究面部属性编辑任务,其目的是通过操作单个或多个感兴趣的属性(如头发颜色、表情、胡须和年龄)来编辑面部图像。
Dataset: CeleA
Contribution:
- 移除了严格的attribute-independent约束,仅需要通过attribute classification来保证正确地修改属性
- 整合了attribute classification constraint、reconstruction learning、adversarial learning,使得结果生成效果非常好
- 可以直接控制属性强度,从而可以自然地完成风格变换
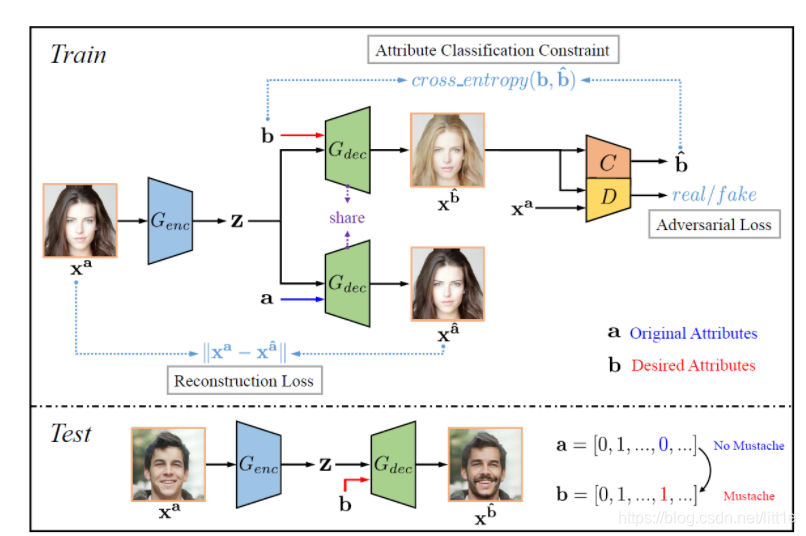
理解论文算法
A. 人脸属性编辑
以学习为基础的方法提出通过部署一个对抗属性损失和一个深度特征损失,来训练出深度特征识别属性转移模型。该模型可以增加或移除一个属性到一个人脸图像(或者将属性从图像中移除)。
属性编辑的能力是通过修改潜在表达去获得所期待的属性信息并解码它而获得的。也就是说这个属性编辑的能力来源于将解码模型增添属性的feature map,然后通过解码过程及鉴别器和calssification的损失,在训练中BP来优化的。这一部分我们在后面的代码中在详细了解。
B. 生成对抗网络(Genreative Adversarial Networks)
GAN的灵魂在于生成对抗,它的原理就是生成器G和鉴别器D的对抗。G包括encode和decode部分,G将输入图像压缩成高维特征后通过解码再形成假图,这个假图作为D的输入,D输出约接近1说明假图越像真图。所以就是在这个不断的生成对抗的过程中,G可以把假图变得越来越真。
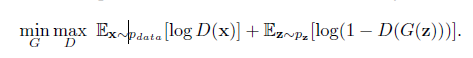
从上图loss中,我们知道X是原图,D(x)表示鉴别器对原图的鉴定结果,Z表示X通过encode压缩成高维特征,G(z)指z由decode后生成的假图,D(G(z))表示用鉴别器去鉴别这个假图有多真。所以当 minmax条件成立,说明假图逼近真图。
ATTGAN
A. Testing Formulation
给一张带有n个二进制属性a=[a1,…,a2]的人脸图像
X
a
X^a
Xa,编码器Genc将
X
a
X^a
Xa转化为潜在表达,记为:
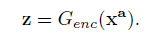
将
X
a
X^a
Xa编辑为属性b的过程是通过解码z(以属性b为条件)来获得的。
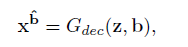

test的过程如上,给定输入图像以及它的属性a,通过Genc变成z,再加入b属性(b属性可以通过a获得,原文中有13个特征,逐位取反既可获得b,可以生成13个b所以test出来可以有13张)
这里大家一定疑惑code中如何添加b的,下面大家看到code就明白了。
B. Training Formulation
属性编辑的问题可以定义为编码器和解码器的学习过程。这个过程是非监督的,因为我们并没有
X
b
X^b
Xb的ground truth。一方面,在原图
X
a
X^a
Xa上编辑,期望产生带有b属性的真实图像。为了达到这个目标,属性分类器被用来限制产生的
X
b
X^b
Xb能够正确获得所期望的属性。另一方面,一个合格的属性编辑应该只改变想改变的属性,同时保持其他不变的细节。为了达到这个目的,reconstruction learning被引入
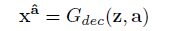
A. Attribute Classification Constraint.
正如上面提及的,生成图应该正确获得新属性b。因此,部署classifier C来限制它获得所期待的属性。
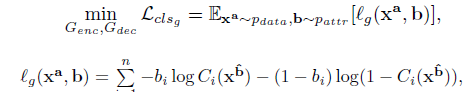
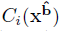
表示对第i个属性的预测,其实可以简单的看成二分类,loss就是交叉熵损失。
B. Reconstruction Loss.
为了完美的保留不改变的部分,作者提出Reconstruction Loss.
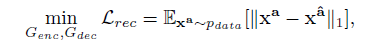
C. Adversarial Loss.
对抗损失同样还是为了生成图更加真实,它分为G和D两部分损失
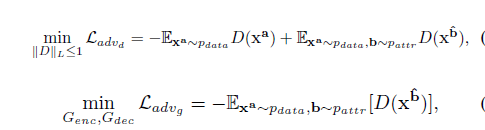
总结,train部分训练了两块(G,D)。
G的损失函数如下:
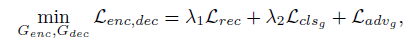
D的损失函数如下:
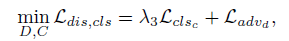
网络结构:

code
def trainG(self, img_a, att_a, att_a_, att_b, att_b_):
for p in self.D.parameters():
p.requires_grad = False
zs_a = self.G(img_a, mode='enc')
img_fake = self.G(zs_a, att_b_, mode='dec')
img_recon = self.G(zs_a, att_a_, mode='dec')
d_fake, dc_fake = self.D(img_fake)
if self.mode == 'wgan':
gf_loss = -d_fake.mean()
if self.mode == 'lsgan': # mean_squared_error
gf_loss = F.mse_loss(d_fake, torch.ones_like(d_fake))
if self.mode == 'dcgan': # sigmoid_cross_entropy
gf_loss = F.binary_cross_entropy_with_logits(d_fake, torch.ones_like(d_fake))
gc_loss = F.binary_cross_entropy_with_logits(dc_fake, att_b)
gr_loss = F.l1_loss(img_recon, img_a)
g_loss = gf_loss + self.lambda_2 * gc_loss + self.lambda_1 * gr_loss
self.optim_G.zero_grad()
g_loss.backward()
self.optim_G.step()
errG = {
'g_loss': g_loss.item(), 'gf_loss': gf_loss.item(),
'gc_loss': gc_loss.item(), 'gr_loss': gr_loss.item()
}
return errG
trainG就是对G这一部分进行训练,从p.requires_grad = False可以找到,虽然G的loss用到了D的部分,但是并不对D进行BP,两部分是分开训练的。
self.G是Genc,将图像压缩成高维特征,这一块代码比较简单,我们从上面的网络结构就可以知道Genc是个啥了。 img_fake就是生成的带有b属性的假图,img_recon是生成的带有a属性的假图。
class Discriminators(nn.Module):
# No instancenorm in fcs in source code, which is different from paper.
def __init__(self, dim=64, norm_fn='instancenorm', acti_fn='lrelu',
fc_dim=1024, fc_norm_fn='none', fc_acti_fn='lrelu', n_layers=5, img_size=128):
super(Discriminators, self).__init__()
self.f_size = img_size // 2**n_layers
layers = []
n_in = 3
for i in range(n_layers):
n_out = min(dim * 2**i, MAX_DIM)
layers += [Conv2dBlock(
n_in, n_out, (4, 4), stride=2, padding=1, norm_fn=norm_fn, acti_fn=acti_fn
)]
n_in = n_out
self.conv = nn.Sequential(*layers)
self.fc_adv = nn.Sequential(
LinearBlock(1024 * self.f_size * self.f_size, fc_dim, fc_norm_fn, fc_acti_fn),
LinearBlock(fc_dim, 1, 'none', 'none')
)
self.fc_cls = nn.Sequential(
LinearBlock(1024 * self.f_size * self.f_size, fc_dim, fc_norm_fn, fc_acti_fn),
LinearBlock(fc_dim, 13, 'none', 'none')
)
def forward(self, x):
h = self.conv(x)
h = h.view(h.size(0), -1)
return self.fc_adv(h), self.fc_cls(h)
d_fake, dc_fake = self.D(img_fake),这里注意。我们看到这个D里有两个输出,一个是将假图压缩成1个pixel,用来判断真假,真就是1,假是0。另一个是把假图压缩成13个pixels用来编辑属性的。
g_loss = gf_loss + self.lambda_2 * gc_loss + self.lambda_1 * gr_loss
gf_loss 就是对抗生成损失,gc_loss是 Attribute Classification Constraint的损失,gr_loss是reconstruction loss,正好对应了论文中的结论。
其他部分就不详述了,想交流的可以留言。















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









