







 博主在训练Bart模型时遇到loss降低但生成重复token的问题,通过理解BartForConditionGeneration与BartModel的区别、参数绑定操作和cache机制,揭示了问题根源并解决了bug。文章深入解析了Attention模块和Decoder层的工作原理,以及`use_cache`在生成阶段的作用。
博主在训练Bart模型时遇到loss降低但生成重复token的问题,通过理解BartForConditionGeneration与BartModel的区别、参数绑定操作和cache机制,揭示了问题根源并解决了bug。文章深入解析了Attention模块和Decoder层的工作原理,以及`use_cache`在生成阶段的作用。
2. 参数(词表)绑定操作
我在训练一个以Bart为基础的模型时,发现训练的loss是能够很好的降下去的,但是在generate的时候,生成的全是相同的token。很是奇怪,损失下降如下:
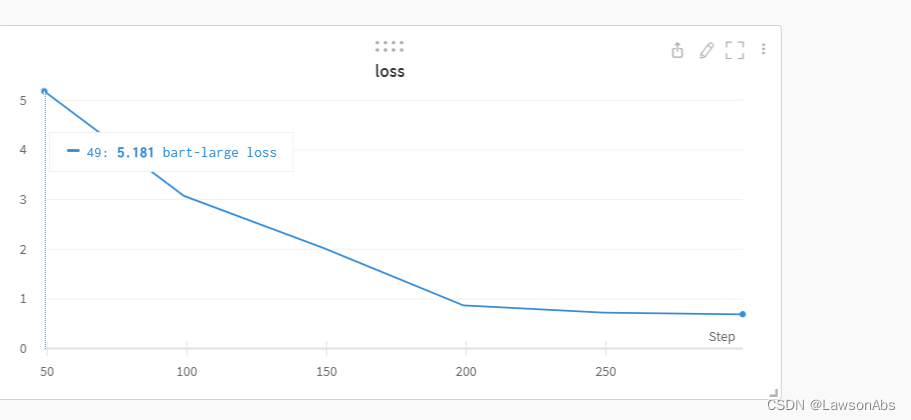
但是生成得到的pred却是下面这个样子:

我定义的Model name是MybartModel,其中的参数是从预训练中加载出来的。代码如下:
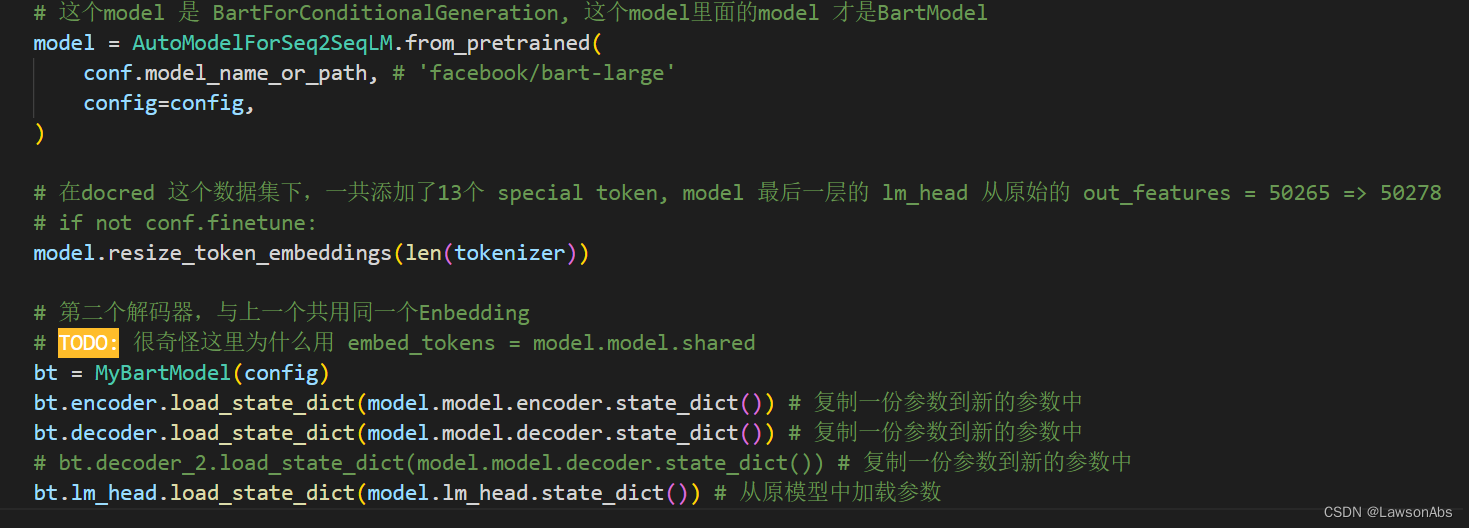
但是针对上面 出现的token重复 的问题,非常疑惑,因为我并不知道是怎么回事儿。直到我师兄说我没有对vocabulary做限制导致的,单纯的load参数只能保证在初始化的时候一致,但是无法保证在训练的时候也一致。即要让如下两个参数保持一致:
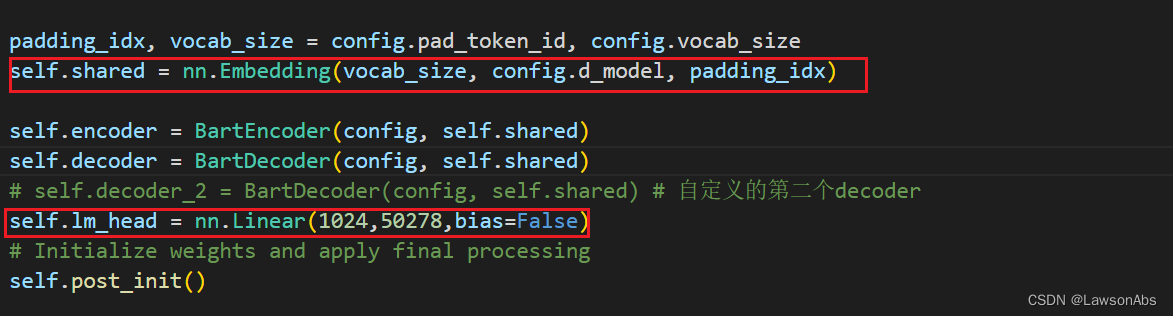
而这个保持一致的实现是在 from_pretrained() 中完成的:

具体细节后面再分析。过了两天终于把这个问题解决了,这次bug 的根本原因是:我不理解BartForConditionGeneration 和 BartModel 之间的区别,导致我直接copy了 BartModel 模型,从而丢失了原有模型的一部分~ ,进而得不到正确的生成结果
我发现这个问题的过程是:
@staticmethod
def _reorder_cache(past, beam_idx):
reordered_past = ()
for layer_past in past:
# cached cross_attention states don't have to be reordered -> they are always the same
reordered_past += (
tuple(past_state.index_select(0, beam_idx) for past_state in layer_past[:2]) + layer_past[2:],
)
return reordered_past
这个代码的目的和逻辑是什么?
缓存cross_attention 的状态,不需要再次排序。(它们始终相同)
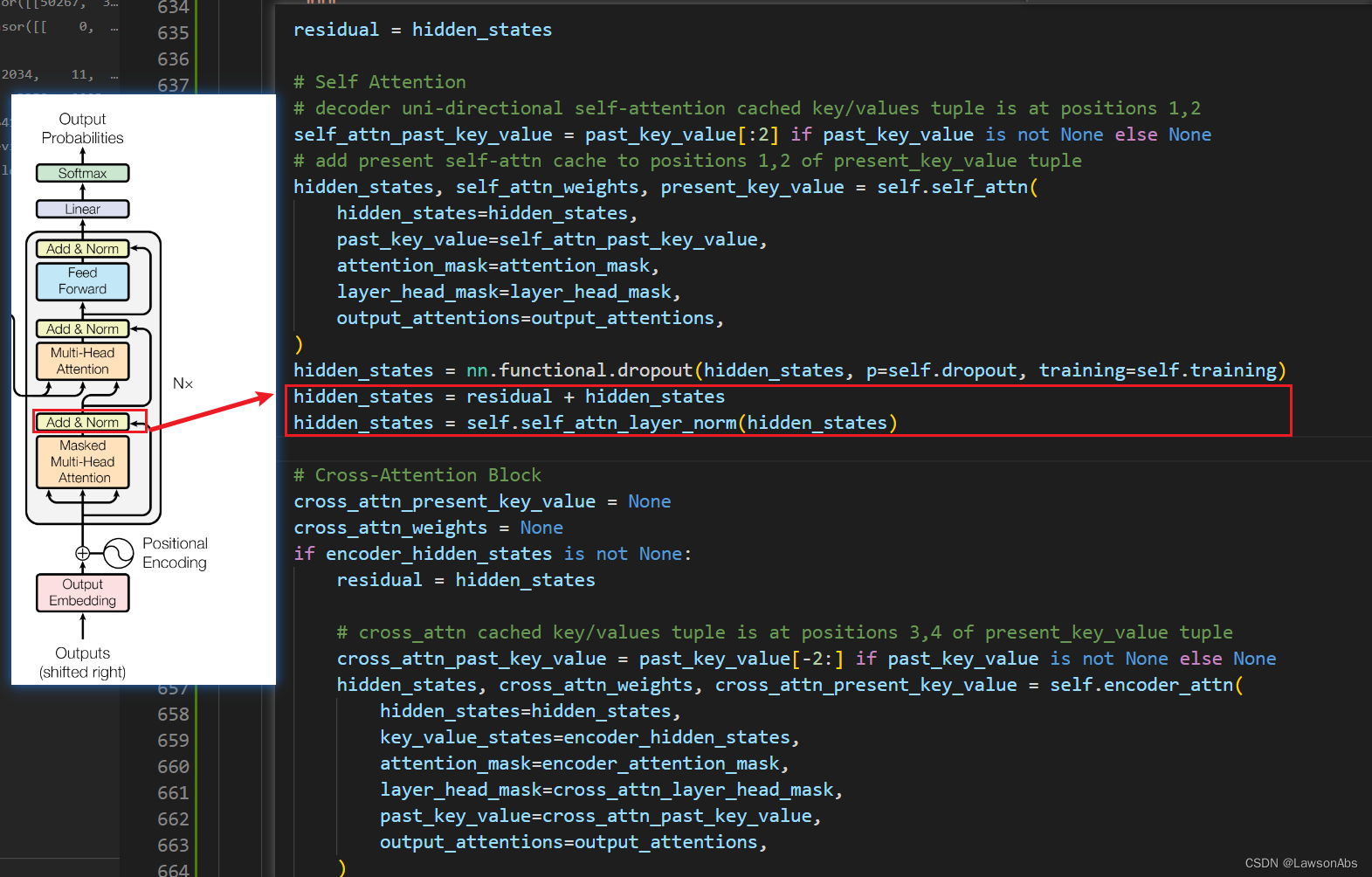
BartDecoderLayer
再聊聊这个BartDecoderLayer,这是Decoder中的基本组件,我们看看其中是怎么运行的:
class BartDecoderLayer(nn.Module):
def __init__(self, config: BartConfig):
super().__init__()
self.embed_dim = config.d_model
self.self_attn = BartAttention(
embed_dim=self.embed_dim,
num_heads=config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.dropout = config.dropout
self.activation_fn = ACT2FN[config.activation_function]
self.activation_dropout = config.activation_dropout
self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.encoder_attn = BartAttention(
self.embed_dim,
config.decoder_attention_heads,
dropout=config.attention_dropout,
is_decoder=True,
)
self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
self.final_layer_norm = nn.LayerNorm(self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = True,
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
encoder_hidden_states (`torch.FloatTensor`):
cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
cross attention 的输入,其shape 为 (batch,seq_len,embed_dim)
encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
这个encoder_attention_mask 与 上面的 attention_mask 有什么区别?
layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
`(encoder_attention_heads,)`.
cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
size `(decoder_attention_heads,)`.
past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
# Self Attention
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
# add present self-attn cache to positions 1,2 of present_key_value tuple
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
past_key_value=self_attn_past_key_value,
attention_mask=attention_mask,
layer_head_mask=layer_head_mask,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.self_attn_layer_norm(hidden_states)
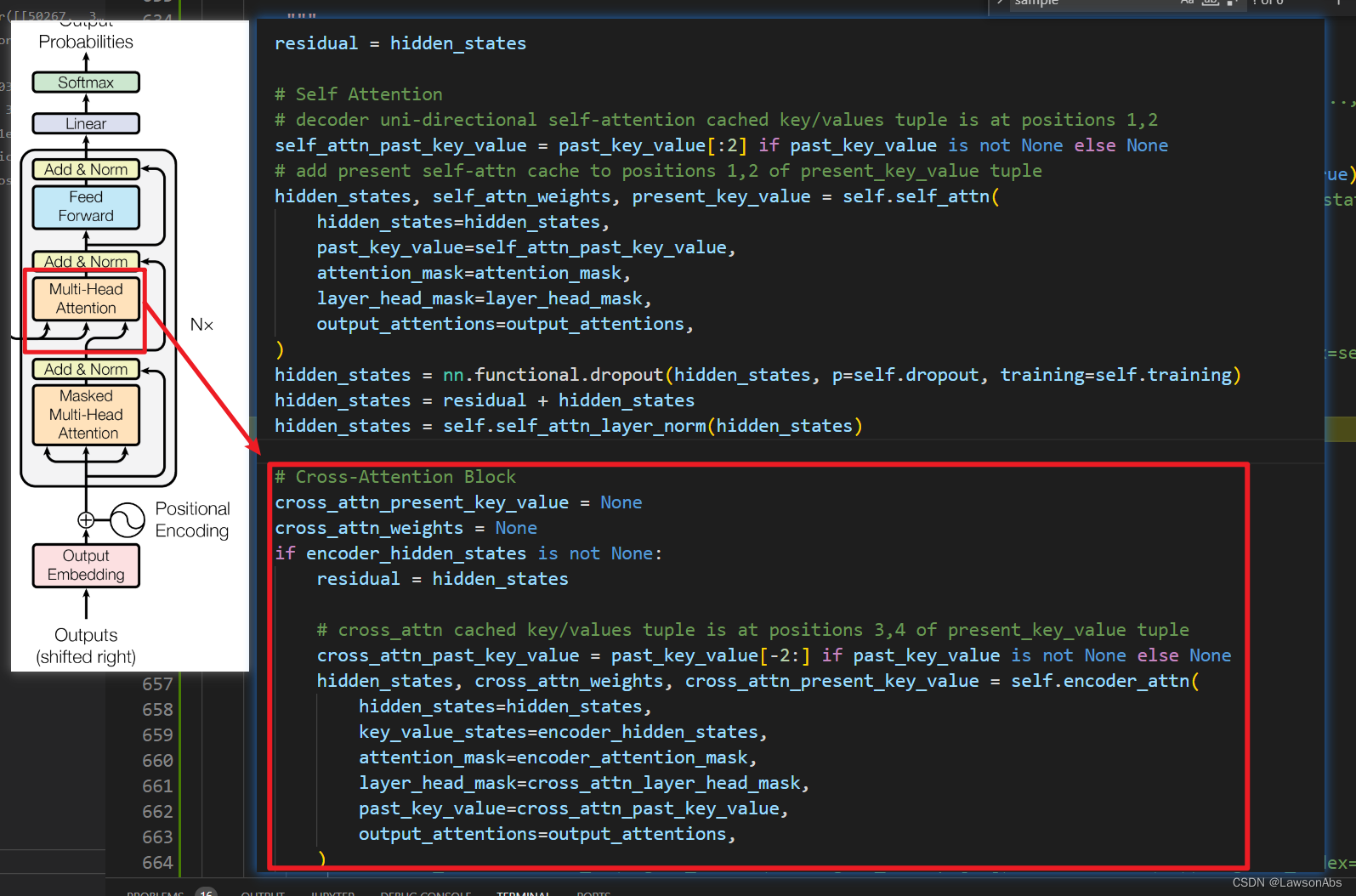
# Cross-Attention Block
cross_attn_present_key_value = None
cross_attn_weights = None
if encoder_hidden_states is not None:
residual = hidden_states
# cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
hidden_states=hidden_states,
key_value_states=encoder_hidden_states,
attention_mask=encoder_attention_mask,
layer_head_mask=cross_attn_layer_head_mask,
past_key_value=cross_attn_past_key_value,
output_attentions=output_attentions,
)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
hidden_states = residual + hidden_states
hidden_states = self.encoder_attn_layer_norm(hidden_states)
# add cross-attn to positions 3,4 of present_key_value tuple
present_key_value = present_key_value + cross_attn_present_key_value
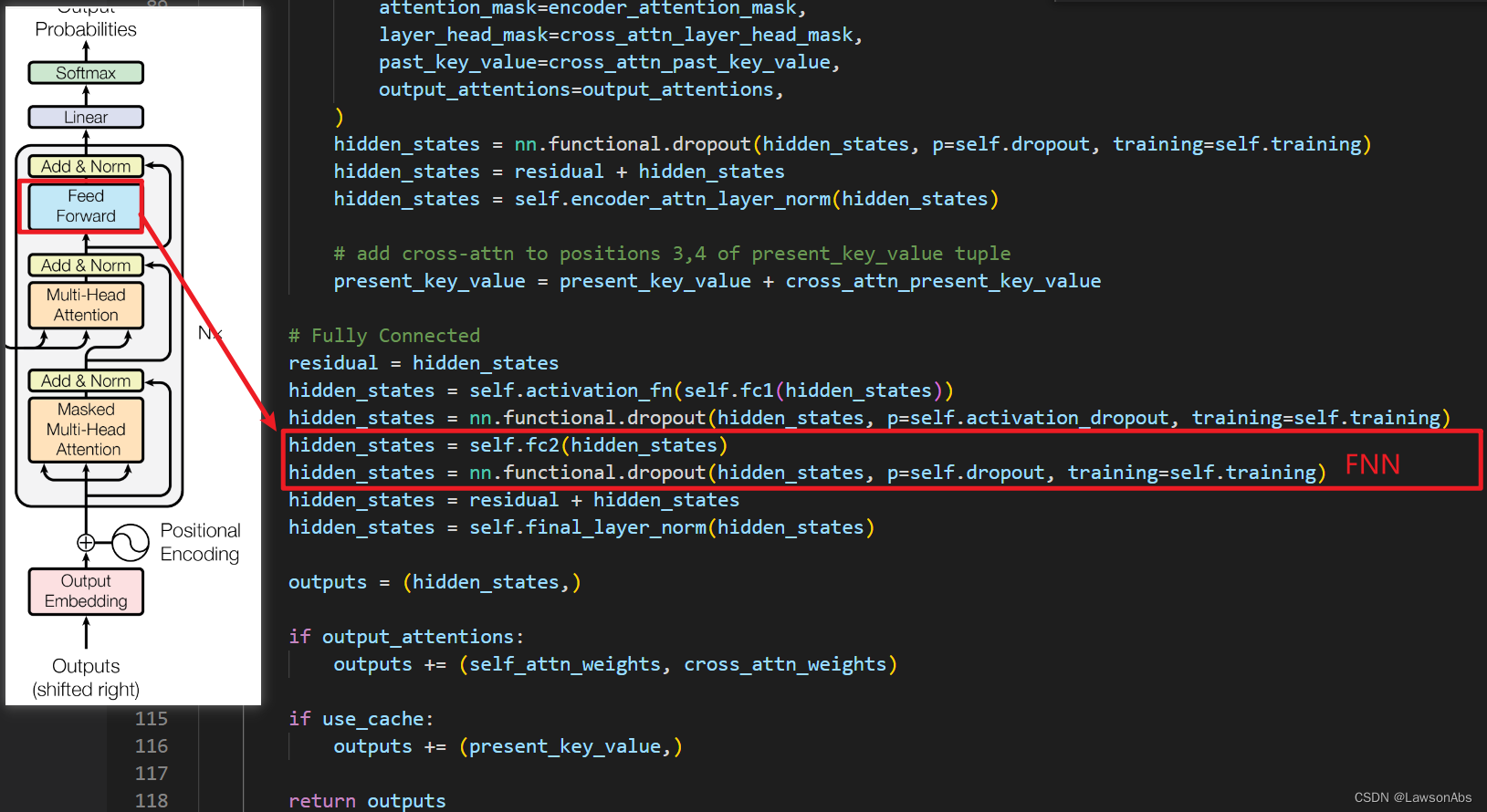
# Fully Connected
residual = hidden_states
hidden_states = self.activation_fn(self.fc1(hidden_states))
hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
hidden_states = self.fc2(hidden_states)
hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
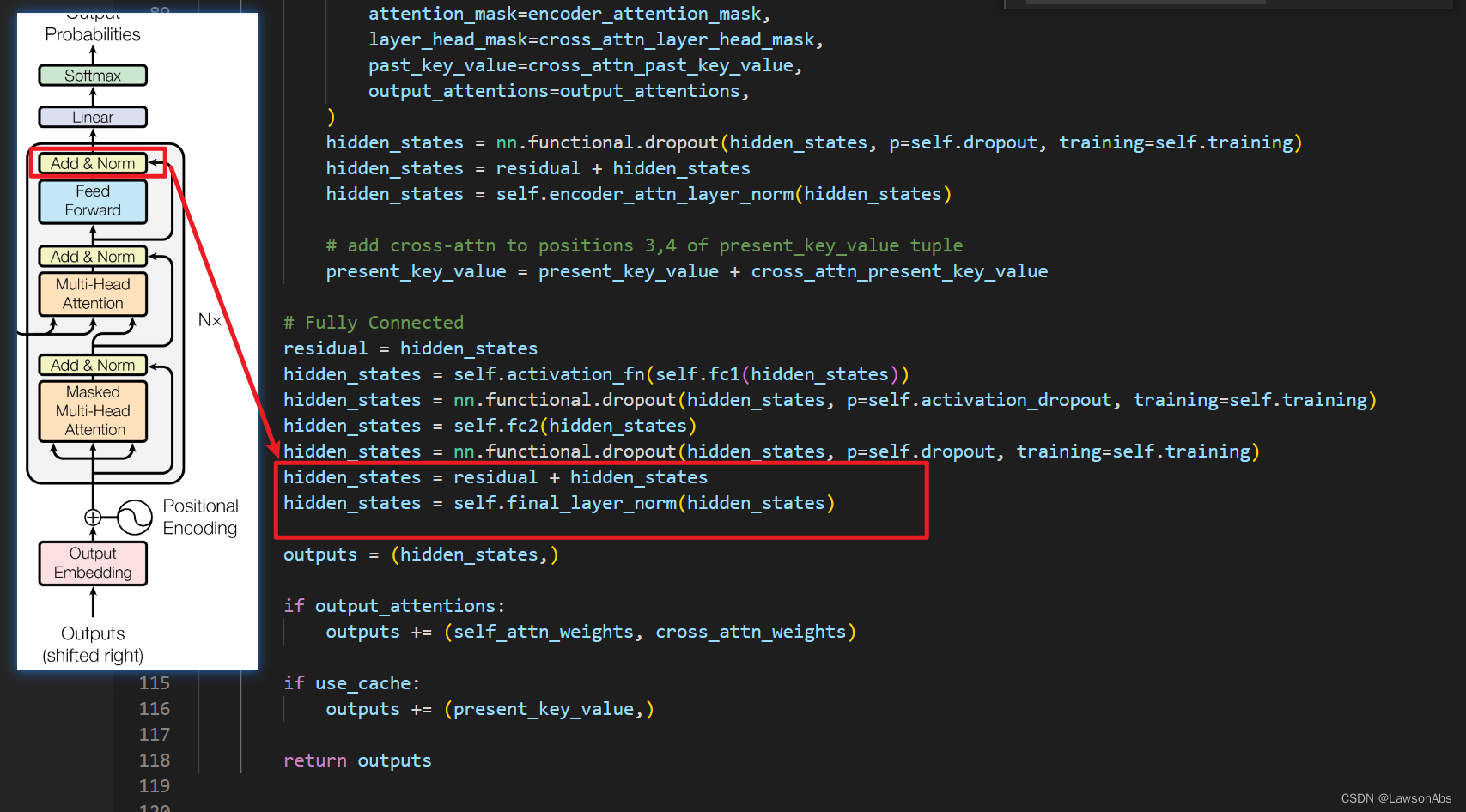
hidden_states = residual + hidden_states
hidden_states = self.final_layer_norm(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (self_attn_weights, cross_attn_weights)
if use_cache:
outputs += (present_key_value,)
return outputs
主要有如下问题:
- 这段代码是要实现什么?
- hidden_states 和 encoder_hidden_states 是什么关系?
hidden_states 是塞入到decoder的input_id 得到的初始embedding,encoder_hidden_states - attention_mask 和 encoder_attention_mask 是什么区别?
- past_key_value 是干啥的?
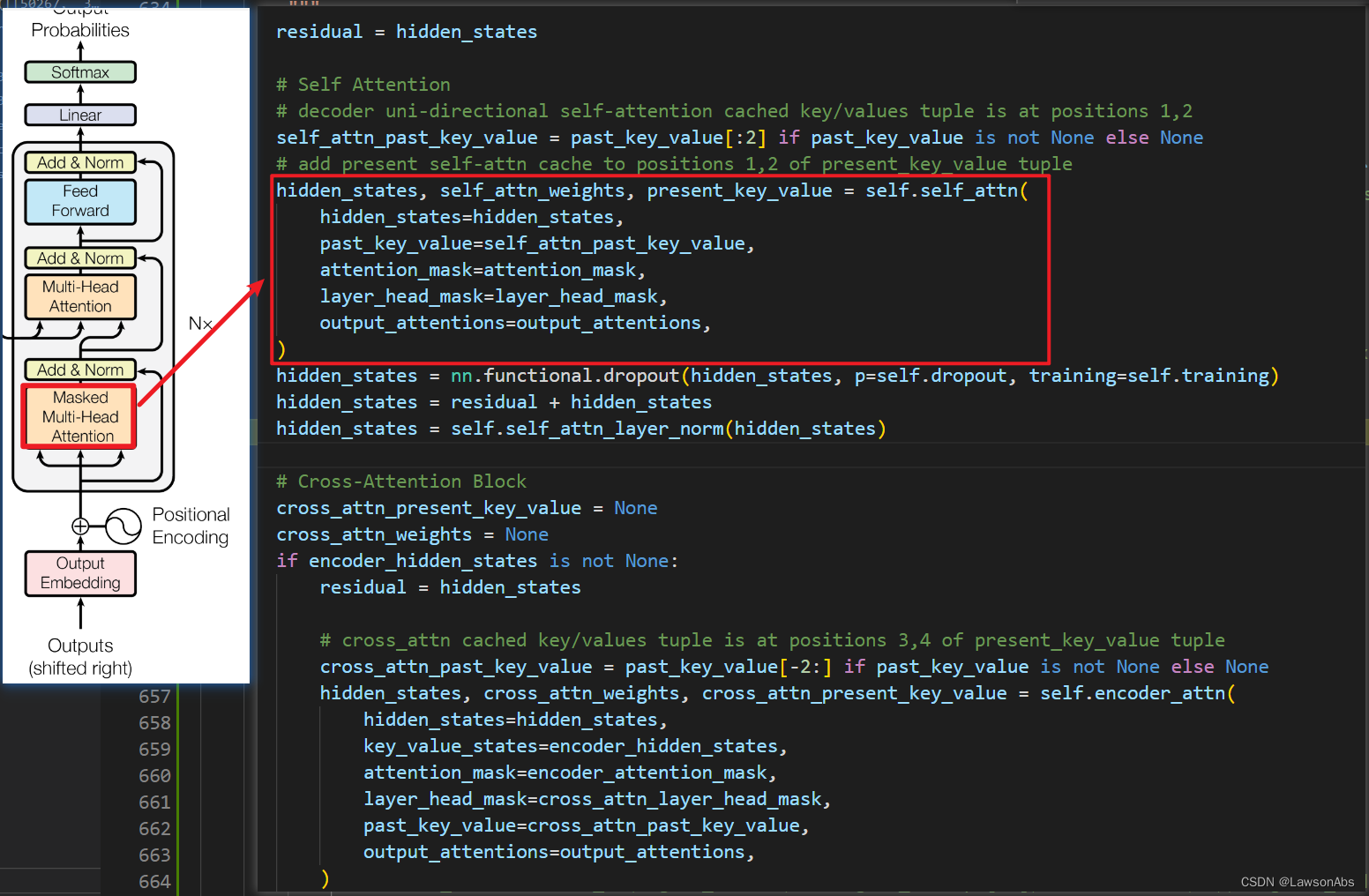
BartAttention
先了解一下 CrossAttention。源码如下:
class BartAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(
self,
embed_dim: int,
num_heads: int,
dropout: float = 0.0,
is_decoder: bool = False,
bias: bool = True,
):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.head_dim = embed_dim // num_heads
if (self.head_dim * num_heads) != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
f" and `num_heads`: {num_heads})."
)
self.scaling = self.head_dim**-0.5
self.is_decoder = is_decoder
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
# 就是一个reshape的操作,因为是Multi-Head Attention,所以这里需要shape成需要的样子
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
is_cross_attention = key_value_states is not None
bsz, tgt_len, _ = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# get key, value proj
# 在cross_attention 中,且使用cache 的情况下,预测第二个词开始会使用的逻辑
# 因为有多层decoder,所以这里重复使用之前就生成好的key_states, value_states
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_states = past_key_value[0]
value_states = past_key_value[1]
# (1)训练的时候cross_attention
# (2) 预测时候cross attention 的第一个词
elif is_cross_attention:
# cross_attentions
key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
elif past_key_value is not None:
# reuse k, v, self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
else:
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
# 针对不同的attention状态,进行一个值的保存
if self.is_decoder:
# 情况一:if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# 情况二:if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# 情况三: if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_states, value_states)
proj_shape = (bsz * self.num_heads, -1, self.head_dim) # 再搞成这个形状是为什么?
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is {attn_weights.size()}"
)
# 在计算完attention值之后,这时的size 是[bsz*self.num_heads,tgt_len,tgt_len]
if attention_mask is not None:
# 判断attention_mask,这里的size 其实就是 (bsz, 1, tgt_len, tgt_len)。为什么又搞出来一个src_len呢?
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
# decoder的时候,使用的是teach forcing,因为要mask掉之后的token,所以计算当前的token时,要保证看不到后面的token
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit awkward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to be reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
# 计算得到attention_probs之后,就是和V做乘法得到每个位置的hidden states
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is {attn_output.size()}"
)
# 修改一下shape
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
# Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
# partitioned aross GPUs when using tensor-parallelism.
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
# 为什么最后还要再搞个out_proj ?
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped, past_key_value
可以看到attention_mask 其实长下面这样(是一个下三角矩阵,上三角代表要屏蔽的):
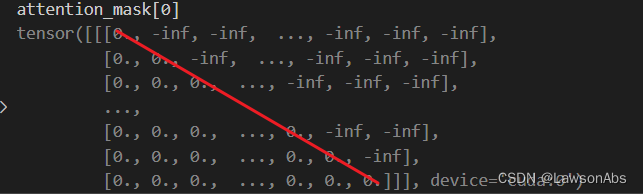
cross_attention 和 self-attention 都是使用上面这个代码(BartAttention把这些所有的attention写在了这个函数中)。decoder 有两类attention,encoder 只有一类attention。所以加一起有三类attention。上面代码的逻辑随着 cross/self-attention 是有变化的。下面就详细讲一下在cross-attention中的计算逻辑。
-
其key_states 和 value_states 都是从 past_key_value 中得到
这里的attn_weights为什么是不是一个方阵?
attn_probs的形状如下:

value_states的shape如下:
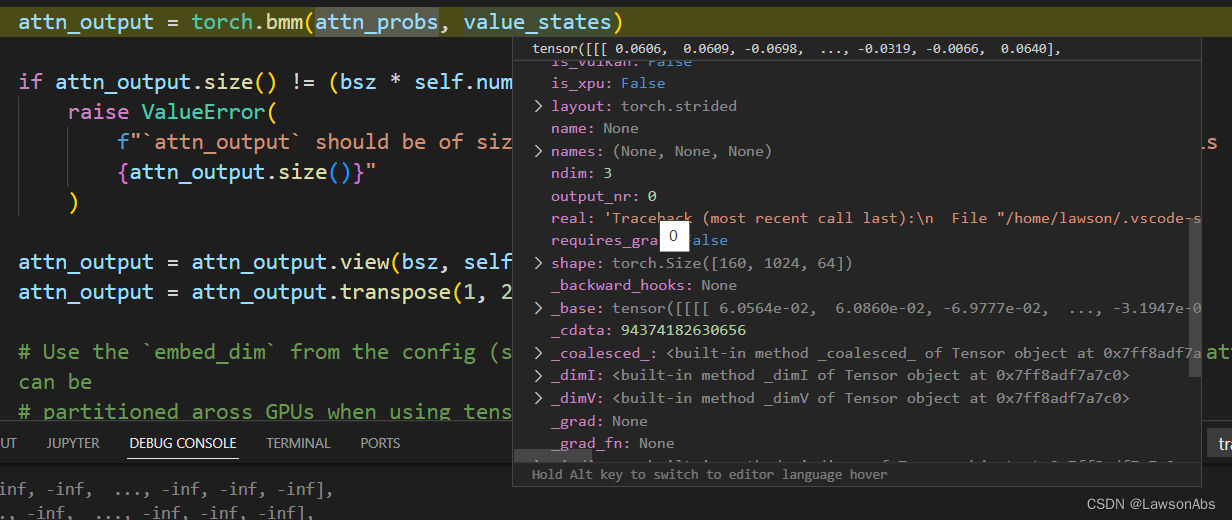
送入到corss_attention 的q是 维度是(10,1,1024), 变成了 (160,1,64), key的维度是(160,1024,64),value 的维度是 (160,1024,64)。
q 是来自于decoder,k,v 是来自于encoder。 -
past_key_value 的逻辑
Encoder-Decoder 的真实样子
我们通常看到的图长下面这样:
但这个图还不够准确,如果是生成模型,那么准确的模型结构应该是下面这样:
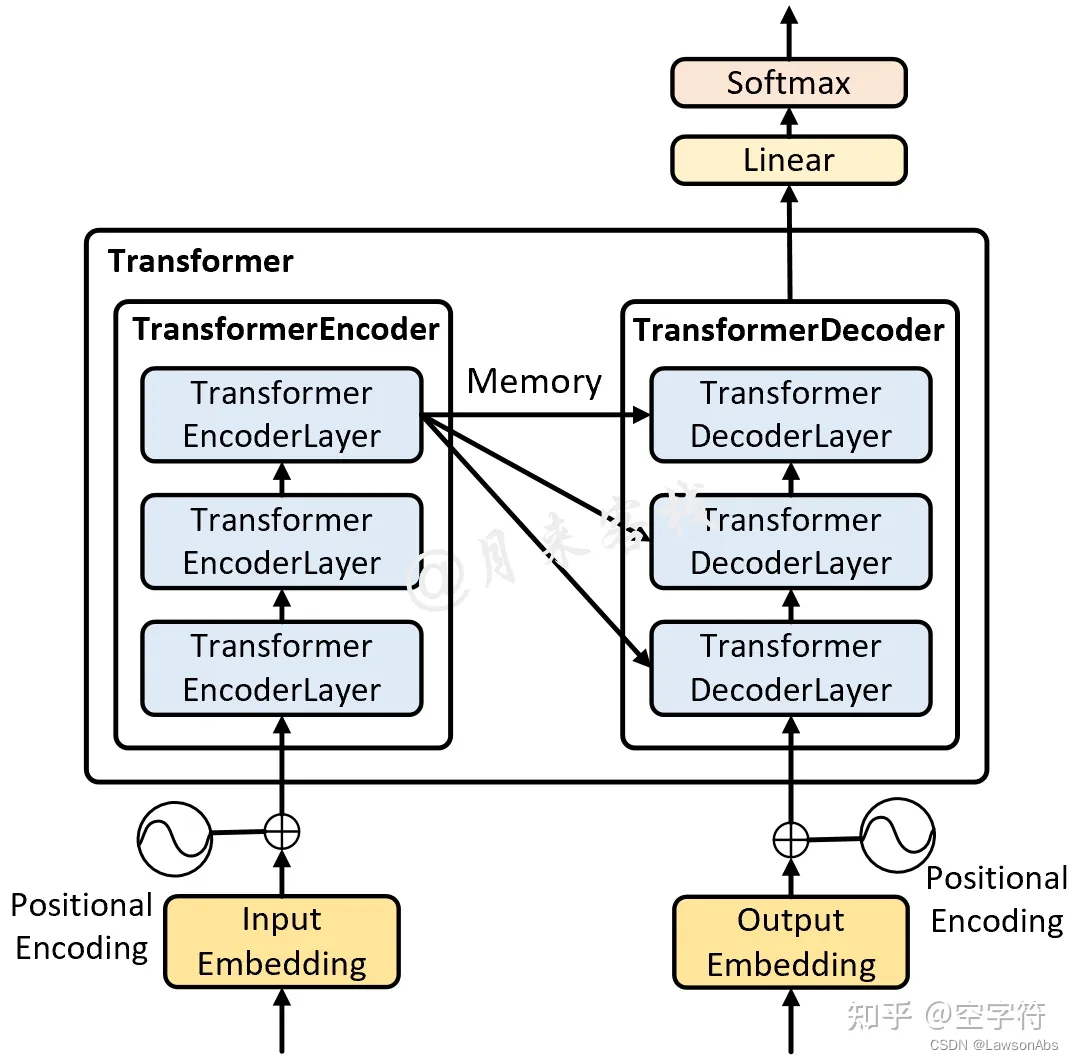
上图说明,decoder的时候,其实是每层都要有一个cross attention。
要时刻记得 decoder 的目标是得到接下来的生成单词,又因为是自回归的,所以每次 decoder 得到的hidden_state 都是一个单词,准确来说,其维度是 (bsz,1,1024/768)。这个1024/768 指的是隐藏层的维度。
use_cache 的作用是什么?
可以参考一下下面这个回复:
https://discuss.huggingface.co/t/what-is-the-purpose-of-use-cache-in-decoder/958
我稍微解释一下:
use_cache 仅仅在generate() 的时候使用,而不是在训练的时候。
BartModel 源码
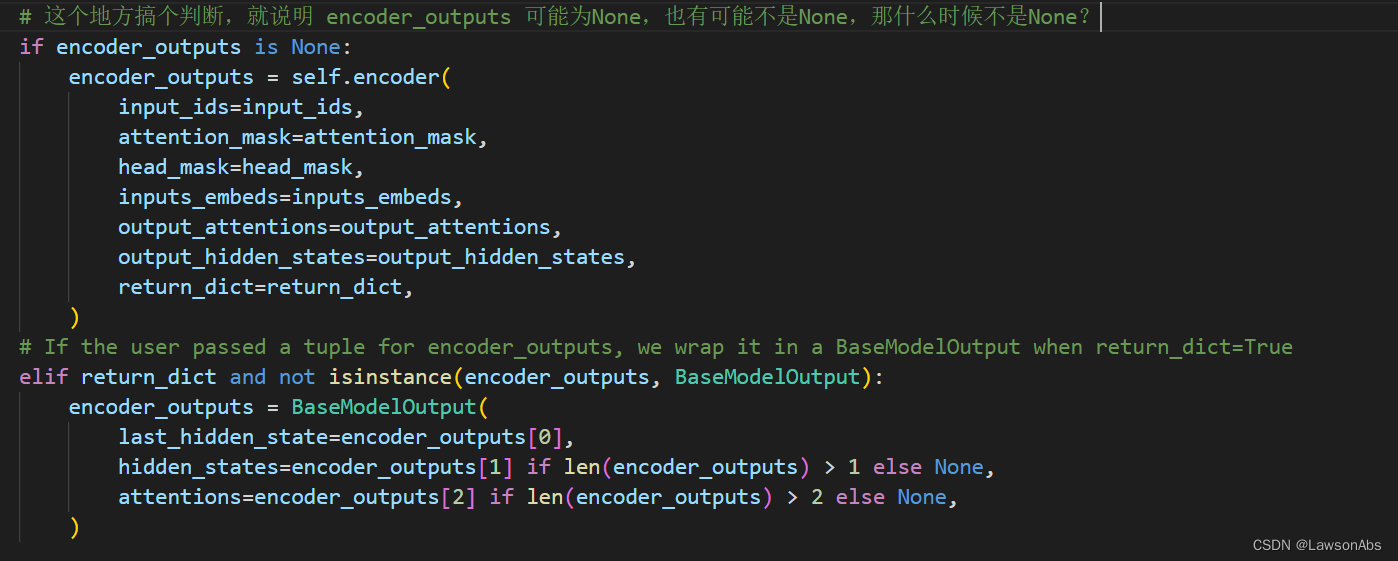
这里为啥先对encoder_outputs 做一个判断?我的猜测是:如果是第一层的decoder layer,那么就需要走这个self.encoder,后几层的decoder layer 则可以直接复用之前计算好的值。
但是我感觉这个理解是不对的,因为复用 encoder_outputs 是在decoder中复用的,而这段代码是在BartModel 中的。
生成的速度很慢,但是训练速度是正常的。
问题是这样的:
我把BartForConditionGeneration 单独拿出来
优秀的源码真的每一行都不是多余的。有这么个感慨是因为,我今天在看Bar他ForConditionGeneration的时候,发现我自己实现的方法和类就是错的。本质上还是对这个BartForConditionGeneration 和 BartModel 不理解导致的。我直接覆写了BartModel,但是没想到其中BartForCoditionGeneration 才是生成模型的最外层的模型。


















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











