







 本文介绍了在Windows WSL上使用Docker搭建Hadoop、Hive和Spark集群,并详细阐述了如何进行MapReduce、Spark应用和Hive编程的开发流程,包括环境配置、Maven的使用、IDEA集成等。
本文介绍了在Windows WSL上使用Docker搭建Hadoop、Hive和Spark集群,并详细阐述了如何进行MapReduce、Spark应用和Hive编程的开发流程,包括环境配置、Maven的使用、IDEA集成等。
前述,我们在Windows WSL上,通过Docker容器技术实现了Hadoop集群环境,现在看看利用现有集群环境进行编程开发。
1 设置容器开启时自运行SSH服务
参照docker中安装Ubuntu无法在启动时运行ssh服务的解决方案 - llCoding - 博客园 (cnblogs.com),在我们的hadoop-spark集群镜像中添加如下内容:
vim /root/startup_run.sh
chmod +x /root/startup_run.sh编写startup_run.sh 脚本内容。
#!/bin/bash
LOGTIME=$(date "+%Y-%m-%d %H:%M:%S")
echo "[$LOGTIME] startup run..." >>/root/startup_run.log
/bin/systemctl status sshd.service |grep "active (running)" > /dev/null 2>&1
if [ "$?" -ne "0" ]; then
if [ -f /root/startup_run.sh ]; then
. /root/startup_run.sh
fi
fi
#service mysql start >>/root/startup_run.log在.bashrc末尾增加如下语句。
vim /root/.bashrc# startup run
if [ -f /root/startup_run.sh ]; then
./root/startup_run.sh
fi同样,修改hadoop-client镜像,startup_run.sh 脚本内容改写为:
#!/bin/bash
LOGTIME=$(date "+%Y-%m-%d %H:%M:%S")
echo "[$LOGTIME] startup run..." >>/root/startup_run.log
/etc/init.d/ssh start >>/root/startup_run.log
#service mysql start >>/root/startup_run.log其他类同。
wslu@LAPTOP-ERJ3P24M:~$ sudo docker commit -m "hadoop spark ssh" hadoop-spark centos/hadoop-spark:v32 Hadoop Mapreduce开发
创建并运行hadoop集群容器。
sudo docker run -it --name hadoop-master -p 60070:50070 -p 2222:22 -h master centos/hadoop-spark:v3 /bin/bash
sudo docker run -it --name hadoop-node02 -p 50070 -p 22 -h node02 centos/hadoop-spark:v3 /bin/bash
sudo docker run -it --name hadoop-node03 -p 50070 -p 22 -h node03 centos/hadoop-spark:v3 /bin/bash
sudo docker run -it --name hadoop-client1 -p 22222:22 -h client1 centos/hadoop-client:v1 /bin/bash启动容器中SSH服务。在master、node02和node03各节点容器以及client客户端容器分别执行。
service sshd start/etc/init.d/ssh start启动hadoop集群。在master节点容器,运行。
[root@master ~]# hadoop/hadoop-2.7.7/sbin/start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /root/hadoop/hadoop-2.7.7/logs/hadoop-root-namenode-master.out
node02: starting datanode, logging to /root/hadoop/hadoop-2.7.7/logs/hadoop-root-datanode-node02.out
node03: starting datanode, logging to /root/hadoop/hadoop-2.7.7/logs/hadoop-root-datanode-node03.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /root/hadoop/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-master.out
[root@master ~]# hadoop/hadoop-2.7.7/sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/hadoop/hadoop-2.7.7/logs/yarn--resourcemanager-master.out
node02: starting nodemanager, logging to /root/hadoop/hadoop-2.7.7/logs/yarn-root-nodemanager-node02.out
node03: starting nodemanager, logging to /root/hadoop/hadoop-2.7.7/logs/yarn-root-nodemanager-node03.outjps查看集群运行进程。
[root@master ~]# jps
4195 ResourceManager
3798 NameNode
4487 Jps
4008 SecondaryNameNode浏览器运行http://localhost:60070。
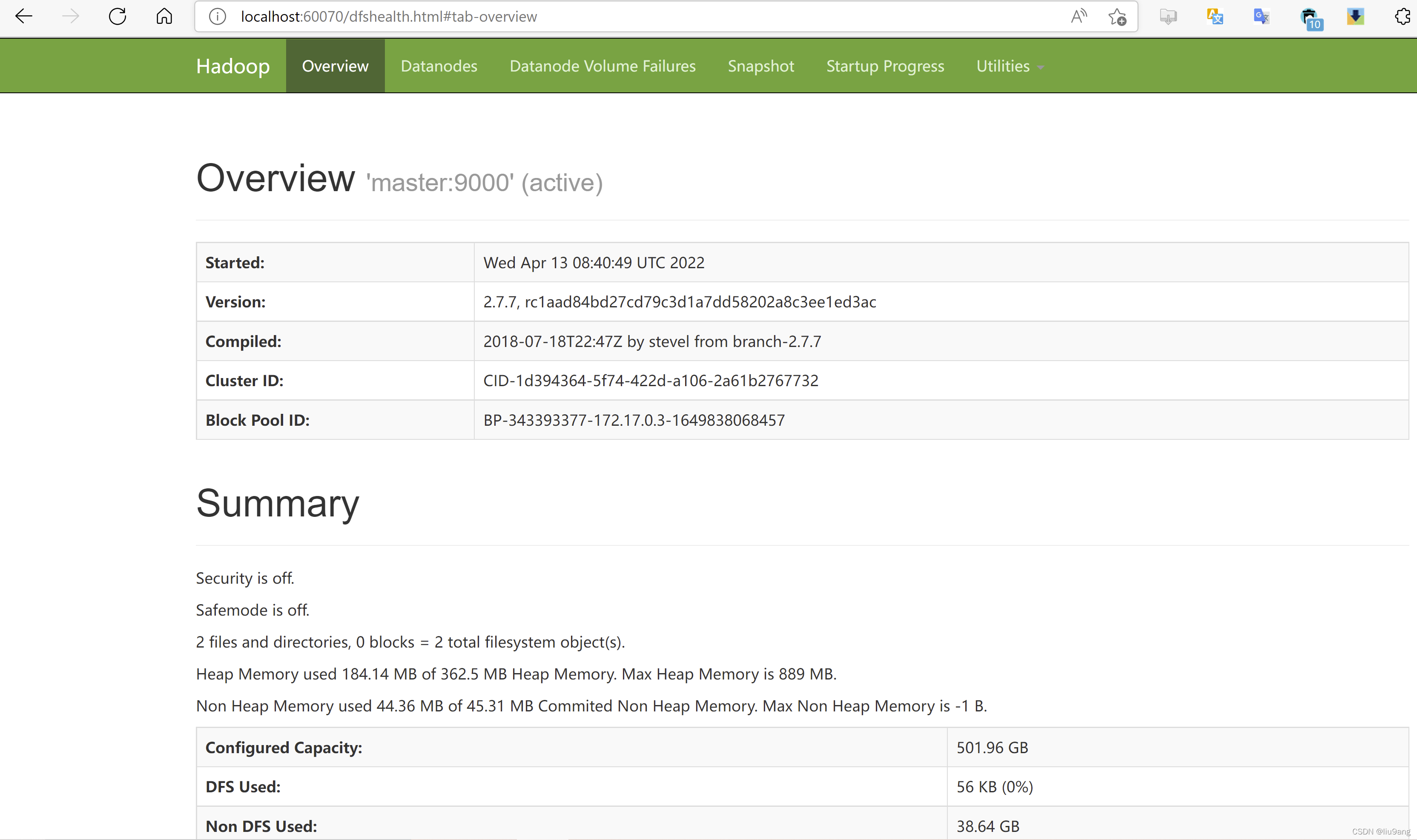

在客户端容器执行和查看hdfs情况。
root@client1:~# hdfs dfs -mkdir /tmp
root@client1:~# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2022-04-13 16:32 /tmpApache Maven的下载与安装。Maven – Download Apache Maven下载apache-maven-3.8.5-bin.tar.gz,传到hadoop-client1容器的data目录下,解压,移动到/root/apache-maven-3.8.5。设置环境变量MAVEN_HOME和PATH路径。
root@client1:~# cd
root@client1:~# cd data
root@client1:~/data# ls
apache-maven-3.8.5-bin.tar.gz
root@client1:~/data# tar xzvf apache-maven*
root@client1:~/data# mv apache-maven-3.8.5 /root/apache-maven-3.8.5
root@client1:~# vi .bashrcMAVEN_HOME=/root/apache-maven-3.8.5
PATH=$PATH:$MAVEN_HOME/bin
export JAVA_HOME JRE_HOME CLASSPATH PATH
export HADOOP_HOME SPARK_HOME HIVE_HOME ZOOKEEPER_HOME
export FLUME_HOME FLUME_CONF_DIR
export KAFKA_HOME FLINK_HOME
export MAVEN_HOMEroot@client1:~# source .bashrcroot@client1:~# mvn --version
Apache Maven 3.8.5 (3599d3414f046de2324203b78ddcf9b5e4388aa0)
Maven home: /root/apache-maven-3.8.5
Java version: 1.8.0_312, vendor: Private Build, runtime: /usr/lib/jvm/java-8-openjdk-amd64/jre
Default locale: en_US, platform encoding: ANSI_X3.4-1968
OS name: "linux", version: "5.10.102.1-microsoft-standard-wsl2", arch: "amd64", family: "unix"
root@client1:~#写一个WordCount测试,参考(203条消息) 使用IDEA+Maven实现MapReduce的WordCount功能_Java_Lioop的博客-CSDN博客_idea词频统计。我们使用MobaXterm开启hadoop-client1容器SSH终端,开启idea。
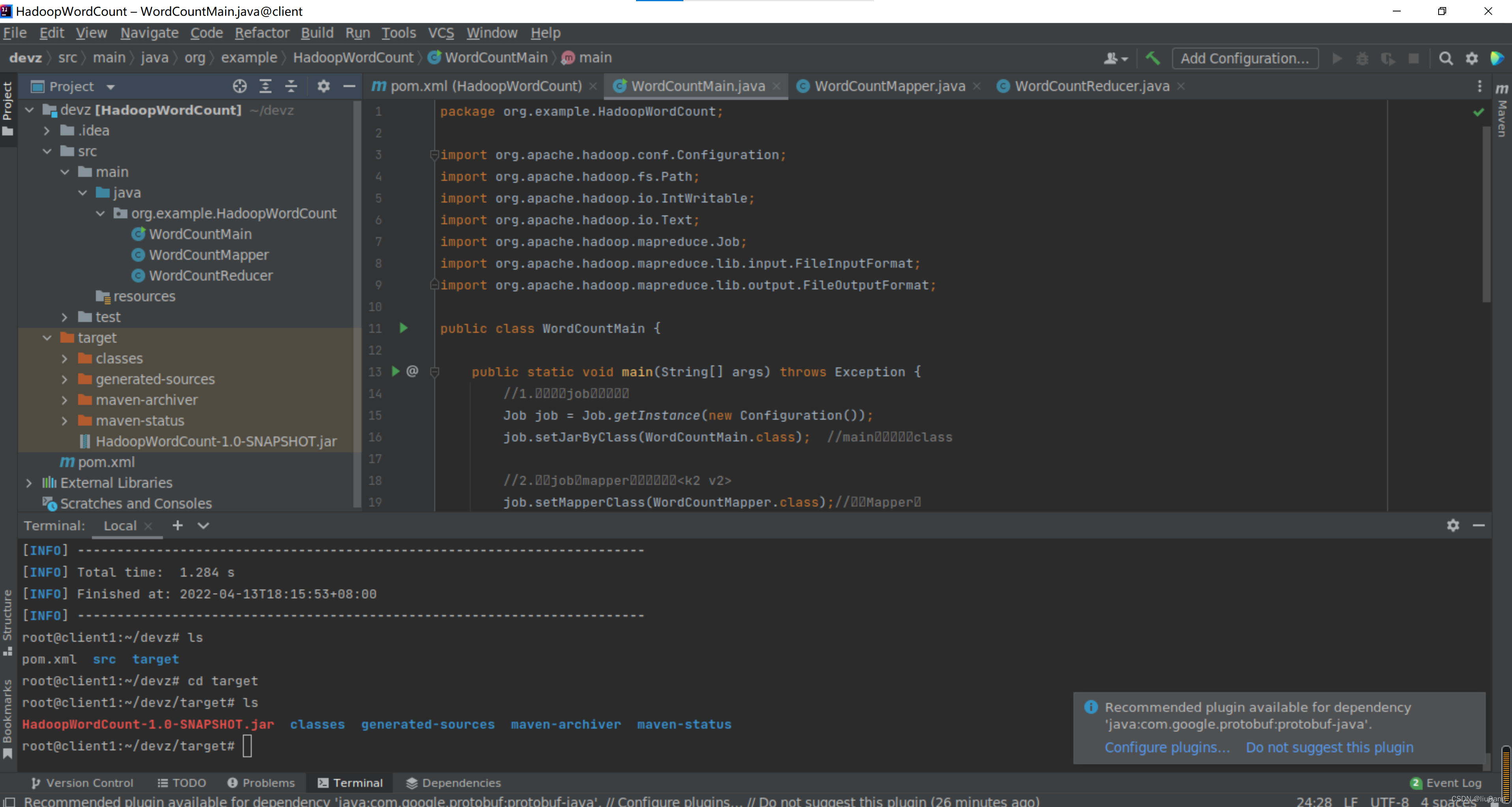
新建maven项目HadoopWordCount。编辑pom.xml。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HadoopWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
</dependency>
</dependencies>
</project>建立项目文件结构。
devz
.idea
src
main
java
org.example.HadoopWordCount
WordCountMain
WordCountMapper
WordCountReducer
resources
test编写WordCountMain、WordCountMapper和WordCountReducer三个java类。
package org.example.HadoopWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
//1.创建一个job和任务入口
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class); //main方法所在的class
//2.指定job的mapper和输出的类型<k2 v2>
job.setMapperClass(WordCountMapper.class);//指定Mapper类
job.setMapOutputKeyClass(Text.class); //k2的类型
job.setMapOutputValueClass(IntWritable.class); //v2的类型
//3.指定job的reducer和输出的类型<k4 v4>
job.setReducerClass(WordCountReducer.class);//指定Reducer类
job.setOutputKeyClass(Text.class); //k4的类型
job.setOutputValueClass(IntWritable.class); //v4的类型
//4.指定job的输入和输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//5.执行job
job.waitForCompletion(true);
}
}
package org.example.HadoopWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// 泛型 k1 v1 k2 v2
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//数据: I like MapReduce
String data = value1.toString();
//分词:按空格来分词
String[] words = data.split(" ");
//输出 k2 v2
for(String w:words){
context.write(new Text(w), new IntWritable(1));
}
}
}
package org.example.HadoopWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// k3 v3 k4 v4
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
//对v3求和
int total = 0;
for(IntWritable v:v3){
total += v.get();
}
//输出 k4 单词 v4 频率
context.write(k3, new IntWritable(total));
}
}
在idea terminal下编译成jar包。
root@client1:~/devz# mvn clean package
[INFO] Scanning for projects...
[INFO]
[INFO] --------------------< org.example:HadoopWordCount >---------------------
[INFO] Building HadoopWordCount 1.0-SNAPSHOT
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ HadoopWordCount ---
[INFO]
[INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ HadoopWordCount ---
[WARNING] Using platform encoding (ANSI_X3.4-1968 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] Copying 0 resource
[INFO]
[INFO] --- maven-compiler-plugin:3.1:compile (default-compile) @ HadoopWordCount ---
[INFO] Changes detected - recompiling the module!
[WARNING] File encoding has not been set, using platform encoding ANSI_X3.4-1968, i.e. build is platform dependent!
[INFO] Compiling 3 source files to /root/devz/target/classes
[INFO]
[INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ HadoopWordCount ---
[WARNING] Using platform encoding (ANSI_X3.4-1968 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /root/devz/src/test/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.1:testCompile (default-testCompile) @ HadoopWordCount ---
[INFO] Nothing to compile - all classes are up to date
[INFO]
[INFO] --- maven-surefire-plugin:2.12.4:test (default-test) @ HadoopWordCount ---
[INFO] No tests to run.
[INFO]
[INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ HadoopWordCount ---
[INFO] Building jar: /root/devz/target/HadoopWordCount-1.0-SNAPSHOT.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 1.284 s
[INFO] Finished at: 2022-04-13T18:15:53+08:00
[INFO] ------------------------------------------------------------------------
查看devz/target下存在HadoopWordCount-1.0-SNAPSHOT.jar。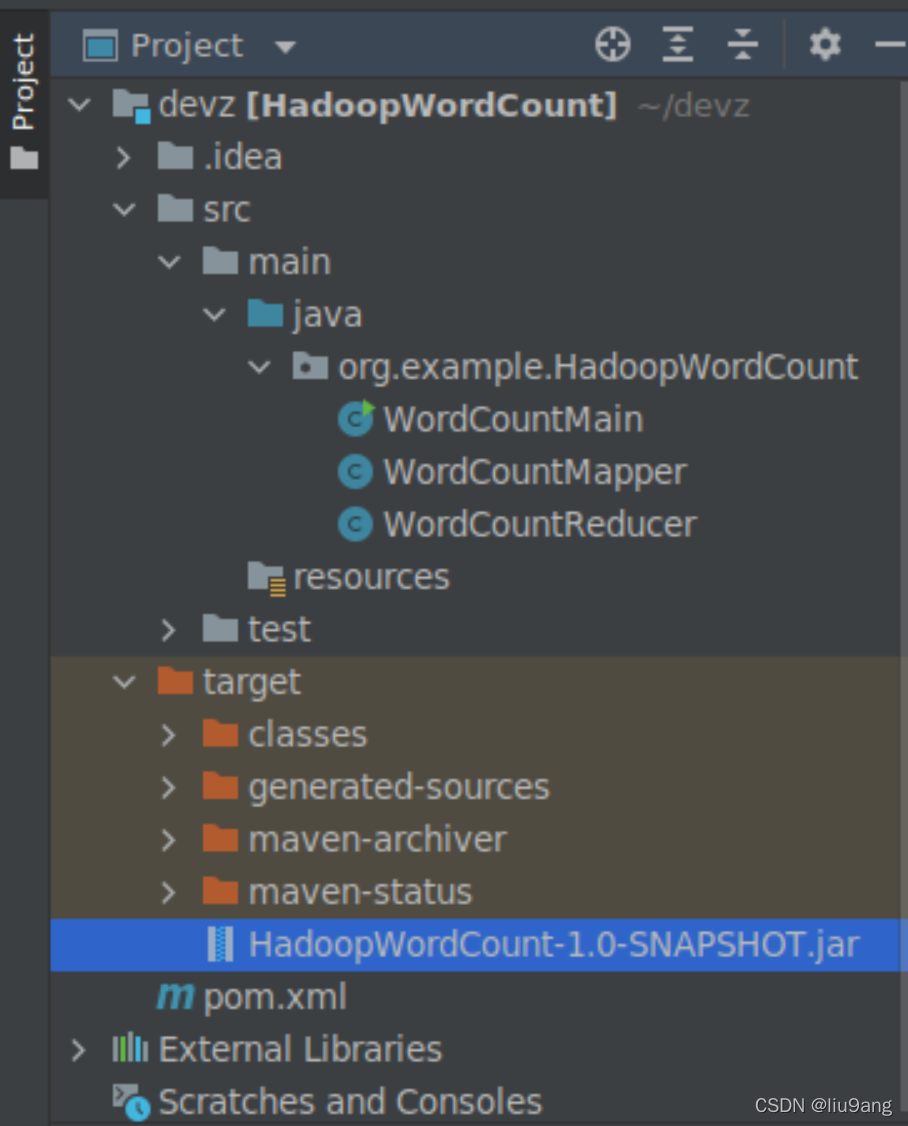
新建文件word.txt。
root@client1:~# vi word.txthello hdfs
hdfs hello
This is MapReduce
reduce word
word great在hdfs文件系统下新建/input目录,将word.txt传到hadoop hdfs /input下。
root@client1:~# hdfs dfs -mkdir /input
root@client1:~# hdfs dfs -put word.txt /input
root@client1:~# hdfs dfs -ls /input
Found 1 items
-rw-r--r-- 3 root supergroup 63 2022-04-13 18:19 /input/word.txt
root@client1:~# hdfs dfs -cat /input/word.txt
hello hdfs
hdfs hello
This is MapReduce
reduce word
word great接下来运行hadoop jar。
root@client1:~# hadoop jar ./devz/target/HadoopWordCount-1.0-SNAPSHOT.jar org/example/HadoopWordCount/WordCountMain /input/word.txt /output
22/04/13 18:28:33 INFO client.RMProxy: Connecting to ResourceManager at master/172.17.0.3:8032
22/04/13 18:28:33 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
22/04/13 18:28:33 INFO input.FileInputFormat: Total input paths to process : 1
22/04/13 18:28:33 INFO mapreduce.JobSubmitter: number of splits:1
22/04/13 18:28:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1649839271892_0001
22/04/13 18:28:34 INFO impl.YarnClientImpl: Submitted application application_1649839271892_0001
22/04/13 18:28:34 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1649839271892_0001/
22/04/13 18:28:34 INFO mapreduce.Job: Running job: job_1649839271892_0001
22/04/13 18:28:39 INFO mapreduce.Job: Job job_1649839271892_0001 running in uber mode : false
22/04/13 18:28:39 INFO mapreduce.Job: map 0% reduce 0%
22/04/13 18:28:43 INFO mapreduce.Job: map 100% reduce 0%
22/04/13 18:28:47 INFO mapreduce.Job: map 100% reduce 100%
22/04/13 18:28:48 INFO mapreduce.Job: Job job_1649839271892_0001 completed successfully
22/04/13 18:28:48 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=135
FILE: Number of bytes written=245597
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=161
HDFS: Number of bytes written=63
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1992
Total time spent by all reduces in occupied slots (ms)=1582
Total time spent by all map tasks (ms)=1992
Total time spent by all reduce tasks (ms)=1582
Total vcore-milliseconds taken by all map tasks=1992
Total vcore-milliseconds taken by all reduce tasks=1582
Total megabyte-milliseconds taken by all map tasks=2039808
Total megabyte-milliseconds taken by all reduce tasks=1619968
Map-Reduce Framework
Map input records=5
Map output records=11
Map output bytes=107
Map output materialized bytes=135
Input split bytes=98
Combine input records=0
Combine output records=0
Reduce input groups=8
Reduce shuffle bytes=135
Reduce input records=11
Reduce output records=8
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=57
CPU time spent (ms)=630
Physical memory (bytes) snapshot=454873088
Virtual memory (bytes) snapshot=3882061824
Total committed heap usage (bytes)=344457216
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=63
File Output Format Counters
Bytes Written=63查看结果。
root@client1:~# hdfs dfs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2022-04-13 18:19 /input
drwxr-xr-x - root supergroup 0 2022-04-13 18:28 /output
drwxr-xr-x - root supergroup 0 2022-04-13 18:28 /tmp
root@client1:~# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2022-04-13 18:28 /output/_SUCCESS
-rw-r--r-- 3 root supergroup 63 2022-04-13 18:28 /output/part-r-00000
root@client1:~# hdfs dfs -cat /output/part-r-00000
MapReduce 1
This 1
great 1
hdfs 2
hello 2
is 1
reduce 1
word 23 Spark应用
启动hadoop集群和spark集群。
同上,加载hadoop-master、hadoop-node02和hadoop03容器,并加载hadoop-client容器,修正/etc/hosts文件,正确指定master、node02、node03和client1及相应IP地址的对应。
我们通过两个shell脚本简化设置的工作。在WSL运行hadoop-master-hosts.sh,通过docker inspect获取对应容器ip地址并传回各容器。
#!/bin/bash
echo -e "`docker inspect --format='{
{range .NetworkSettings.Networks}}{
{.IPAddress}}{
{end}}' hadoop-master`\tmaster" > hadoop-hosts
echo -e "`docker inspect --format='{
{range .NetworkSettings.Networks}}{
{.IPAddress}}{
{end}}' hadoop-node02`\tnode02" >> hadoop-hosts
echo -e "`docker inspect --format='{
{range .NetworkSettings.Networks}}{
{.IPAddress}}{
{end}}' hadoop-node03`\tnode03" >> hadoop-hosts
echo -e "`docker inspect --format='{
{range .NetworkSettings.Networks}}{
{.IPAddress}}{
{end}}' hadoop-client1`\tclient1" >> hadoop-hosts
#echo -e "`docker inspect --format='{
{range .NetworkSettings.Networks}}{
{.IPAddress}}{
{end}}' hadoop-mysql`\tmysqls" > hadoop-hosts
sudo docker cp hadoop-hosts hadoop-master:/root/hosts1
sudo docker cp hadoop-hosts hadoop-node02:/root/hosts1
sudo docker cp hadoop-hosts hadoop-node03:/root/hosts1
sudo docker cp hadoop-hosts hadoop-client1:/root/hosts1
#sudo docker cp hadoop-hosts hadoop-mysql:/root/hosts1在各容器中执行re-hosts.sh。
#!/bin/bash
echo "$(sed '/172.17.0/d' /etc/hosts)" > /etc/hosts
cat hosts1 >> /etc/hosts在master运行/root/hadoop/hadoop-2.7.7/sbin/start-dfs.sh,/root/hadoop/hadoop-2.7.7/sbin/start-yarn.sh启动hadoop。
在master运行/root/hadoop/spark-2.1.1-bin-hadoop2.7/sbin/start-master.sh,/root/hadoop/spark-2.1.1-bin-hadoop2.7/sbin/start-slaves.sh启动spark集群。
在hadoop-client1容器执行spark-shell。
root@client1:~# spark-shell --master master:7077
Error: Master must either be yarn or start with spark, mesos, local
Run with --help for usage help or --verbose for debug output
root@client1:~# spark-shell --master spark://master:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/spark-2.1.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/04/14 13:01:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/04/14 13:01:29 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
22/04/14 13:01:30 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
22/04/14 13:01:30 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://172.17.0.5:4040
Spark context available as 'sc' (master = spark://master:7077, app id = app-20220414050124-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala>输入:quit退出。
集群测试参见在集群上运行Spark应用程序_厦大数据库实验室博客 (xmu.edu.cn)。在集群中运行应用程序JAR包。把spark://master:7077作为主节点参数递给spark-submit,运行Spark自带的样例程序SparkPi,它的功能是计算得到pi的值(3.1415926)。
root@client1:~# spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 hadoop/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar 100 2>&1 | grep "Pi is roughly"
Pi is roughly 3.1420243142024313在spark-shell中输入代码 。
scala> val textFile = sc.textFile("hdfs://master:9000/input/word.txt")
textFile: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/input/word.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count()
res0: Long = 6
scala> textFile.first()
res1: String = hello hdfsspark on yarn。在集群中运行应用程序JAR包,向Hadoop YARN集群管理器提交应用,把yarn-cluster作为主节点参数递给spark-submit。
root@client1:~# spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster hadoop/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar
Warning: Master yarn-cluster is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/spark-2.1.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/04/14 13:27:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/04/14 13:27:24 INFO client.RMProxy: Connecting to ResourceManager at master/172.17.0.2:8032
22/04/14 13:27:25 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers
22/04/14 13:27:25 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
22/04/14 13:27:25 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead
22/04/14 13:27:25 INFO yarn.Client: Setting up container launch context for our AM
22/04/14 13:27:25 INFO yarn.Client: Setting up the launch environment for our AM container
22/04/14 13:27:25 INFO yarn.Client: Preparing resources for our AM container
22/04/14 13:27:25 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
22/04/14 13:27:26 INFO yarn.Client: Uploading resource file:/tmp/spark-b31ba74b-bd24-419a-95db-f74a457290c9/__spark_libs__7573270795616141427.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1649911721270_0001/__spark_libs__7573270795616141427.zip
22/04/14 13:27:27 INFO yarn.Client: Uploading resource file:/root/hadoop/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar -> hdfs://master:9000/user/root/.sparkStaging/application_1649911721270_0001/spark-examples_2.11-2.1.1.jar
22/04/14 13:27:27 INFO yarn.Client: Uploading resource file:/tmp/spark-b31ba74b-bd24-419a-95db-f74a457290c9/__spark_conf__3756889894852026633.zip -> hdfs://master:9000/user/root/.sparkStaging/application_1649911721270_0001/__spark_conf__.zip
22/04/14 13:27:27 INFO spark.SecurityManager: Changing view acls to: root
22/04/14 13:27:27 INFO spark.SecurityManager: Changing modify acls to: root
22/04/14 13:27:27 INFO spark.SecurityManager: Changing view acls groups to:
22/04/14 13:27:27 INFO spark.SecurityManager: Changing modify acls groups to:
22/04/14 13:27:27 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/04/14 13:27:27 INFO yarn.Client: Submitting application application_1649911721270_0001 to ResourceManager
22/04/14 13:27:28 INFO impl.YarnClientImpl: Submitted application application_1649911721270_0001
22/04/14 13:27:29 INFO yarn.Client: Application report for application_1649911721270_0001 (state: ACCEPTED)
22/04/14 13:27:29 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1649914047921
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1649911721270_0001/
user: root
22/04/14 13:27:30 INFO yarn.Client: Application report for application_1649911721270_0001 (state: ACCEPTED)
22/04/14 13:27:31 INFO yarn.Client: Application report for application_1649911721270_0001 (state: ACCEPTED)
22/04/14 13:27:32 INFO yarn.Client: Application report for application_1649911721270_0001 (state: RUNNING)
22/04/14 13:27:32 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 172.17.0.4
ApplicationMaster RPC port: 0
queue: default
start time: 1649914047921
final status: UNDEFINED
tracking URL: http://master:8088/proxy/application_1649911721270_0001/
user: root
22/04/14 13:27:33 INFO yarn.Client: Application report for application_1649911721270_0001 (state: RUNNING)
22/04/14 13:27:34 INFO yarn.Client: Application report for application_1649911721270_0001 (state: RUNNING)
22/04/14 13:27:35 INFO yarn.Client: Application report for application_1649911721270_0001 (state: RUNNING)
22/04/14 13:27:36 INFO yarn.Client: Application report for application_1649911721270_0001 (state: RUNNING)
22/04/14 13:27:37 INFO yarn.Client: Application report for application_1649911721270_0001 (state: FINISHED)
22/04/14 13:27:37 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 172.17.0.4
ApplicationMaster RPC port: 0
queue: default
start time: 1649914047921
final status: SUCCEEDED
tracking URL: http://master:8088/proxy/application_1649911721270_0001/
user: root
22/04/14 13:27:37 INFO util.ShutdownHookManager: Shutdown hook called
22/04/14 13:27:37 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-b31ba74b-bd24-419a-95db-f74a457290c9
root@client1:~#用spark-shell连接到独立集群管理器上。
root@client1:~# spark-shell --master yarn
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/spark-2.1.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/04/14 13:41:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/04/14 13:41:03 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
22/04/14 13:41:12 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://172.17.0.5:4040
Spark context available as 'sc' (master = yarn, app id = application_1649911721270_0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val textFile = sc.textFile("hdfs://master:9000/input/word.txt")
textFile: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/input/word.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count()
res0: Long = 6
scala> textFile.first()
res2: String = hello hdfs
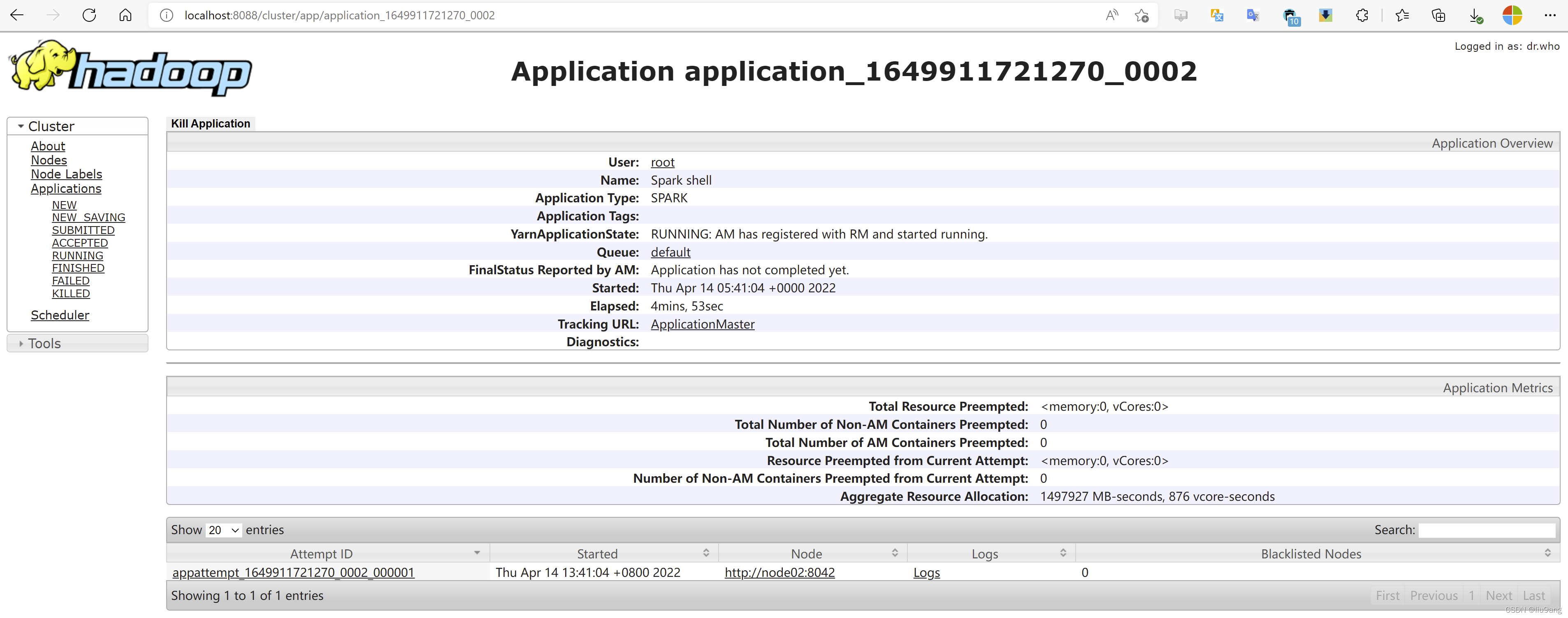
scala>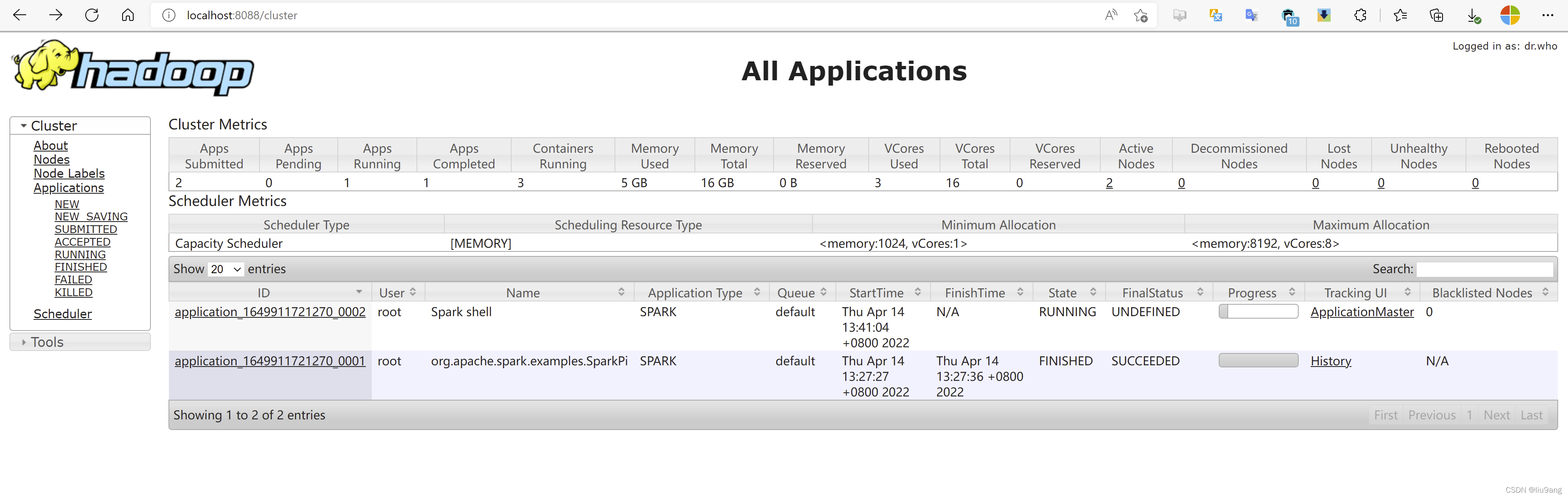
 使用idea,在idea安装Scala插件。
使用idea,在idea安装Scala插件。
参考大数据,Spark_厦大数据库实验室博客 (xmu.edu.cn)。新建maven项目,在项目文件结构中src/main下新建scala目录,将scala目录设置为Resources Root。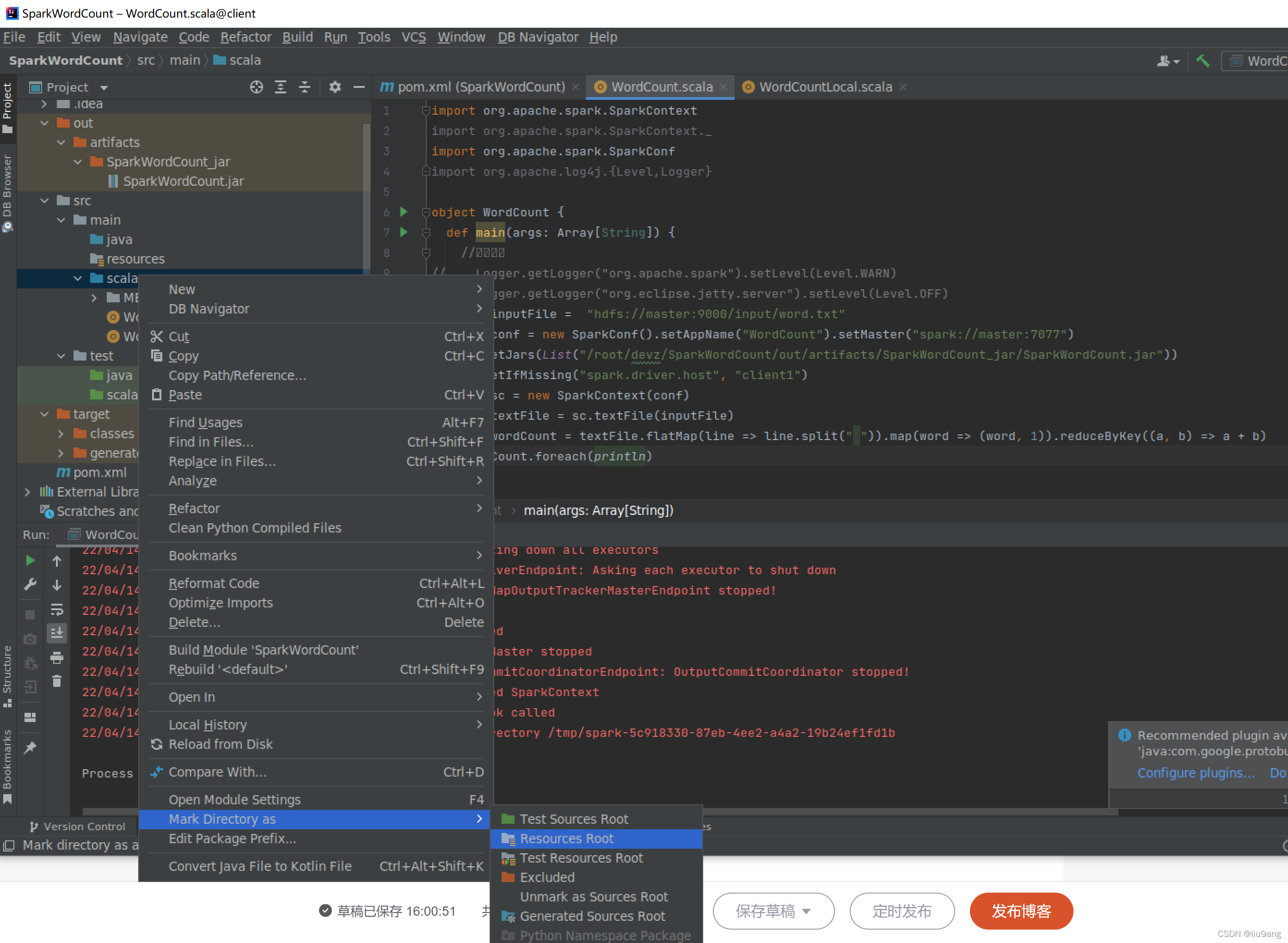
新建一个Scala类,Word Count.scala,输入程序。
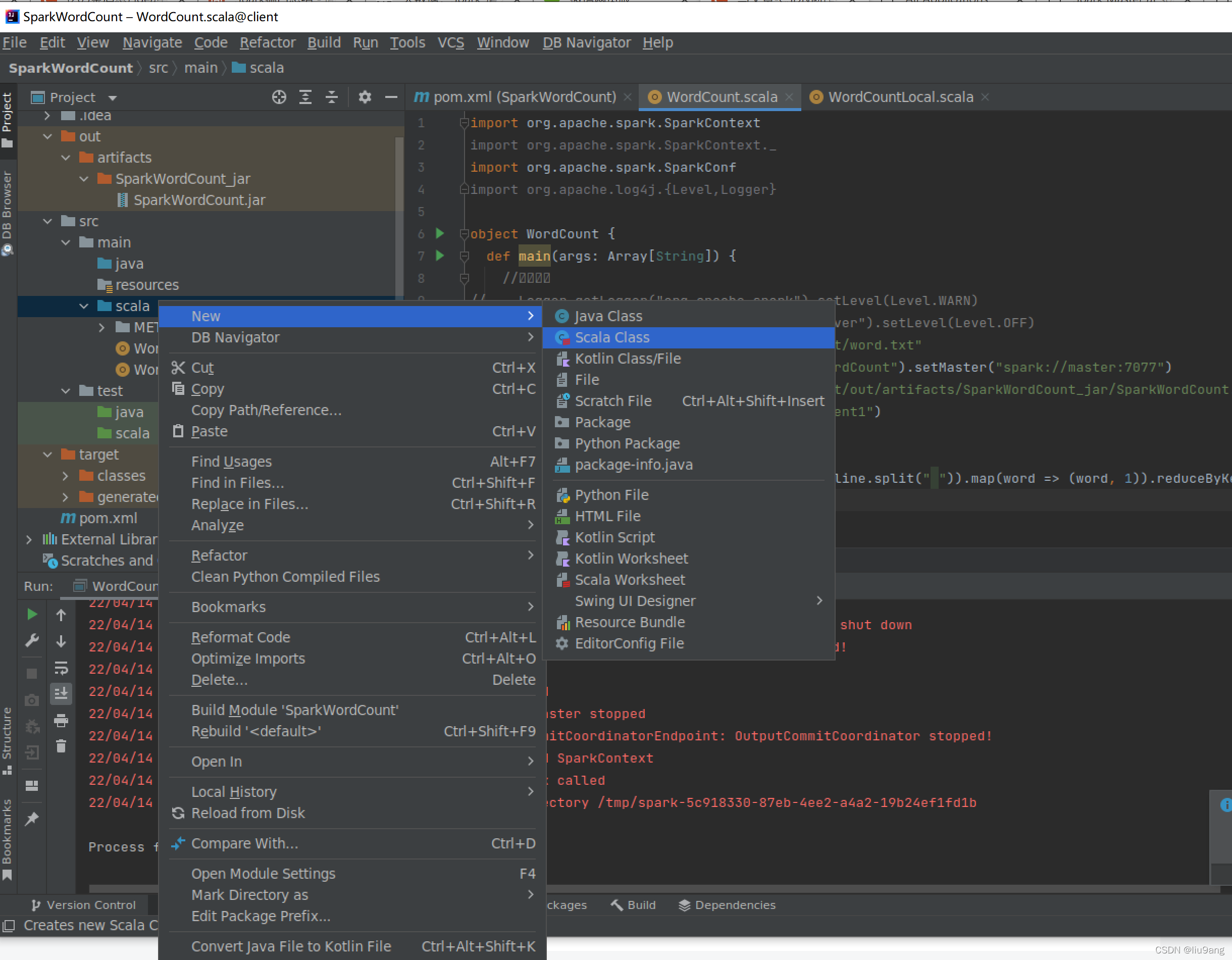
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.log4j.{Level,Logger}
object WordCountLocal {
def main(args: Array[String]) {
//屏蔽日志
// Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val inputFile = "hdfs://master:9000/input/word.txt"
val conf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}添加pom.xml。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkWordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>2.1.1</spark.version>
<scala.version>2.11</scala.version>
<hadoop.version>2.7.7</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>运行结果。
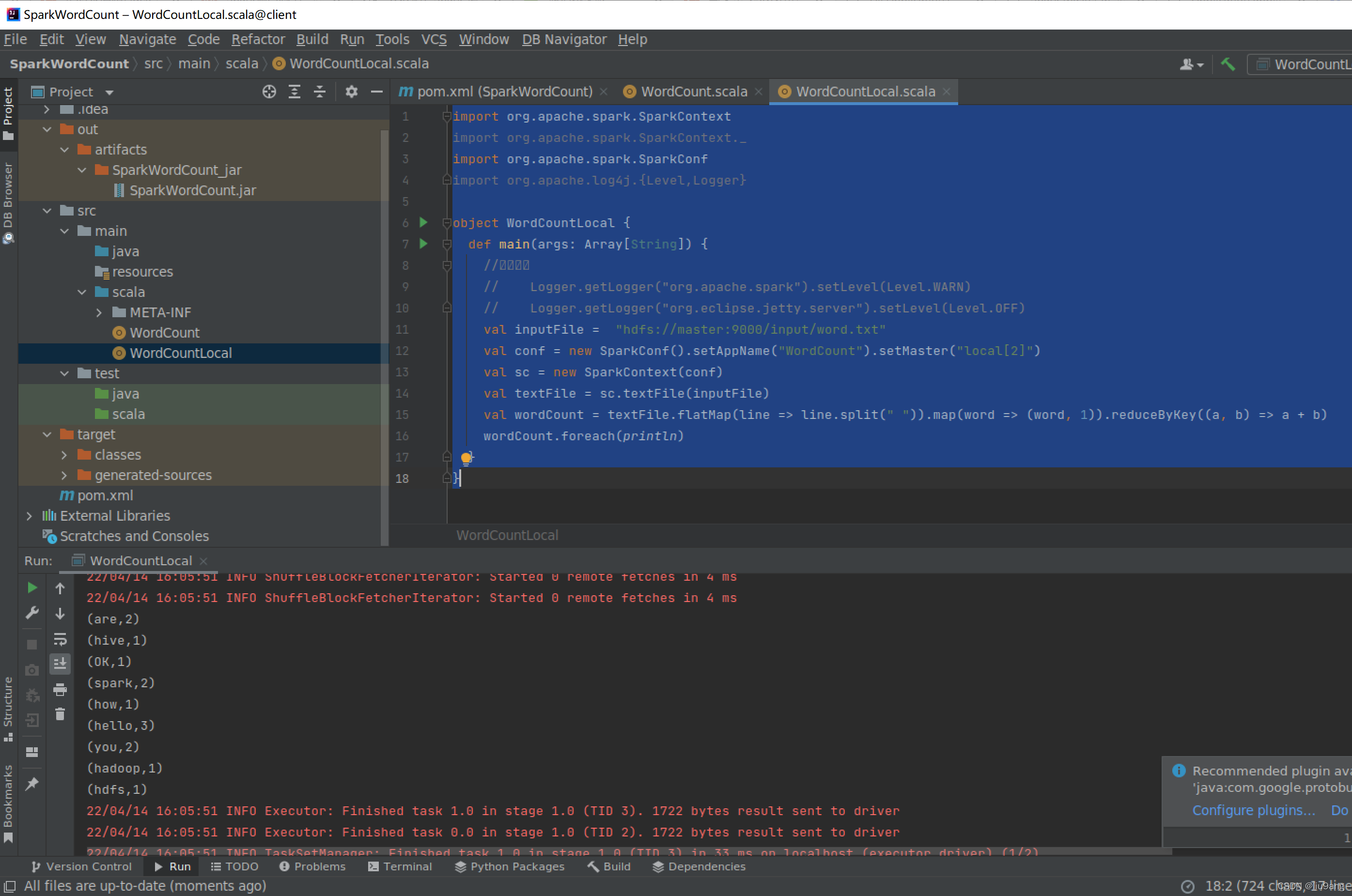
root@client1:~# spark-submit --master local[2] --class WordCountLocal /root/devz/SparkWordCount/out/artifacts/SparkW
ordCount_jar/SparkWordCount.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/hadoop/spark-2.1.1-bin-hadoop2.7/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/04/14 18:35:59 INFO spark.SparkContext: Running Spark version 2.1.1
22/04/14 18:35:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/04/14 18:35:59 INFO spark.SecurityManager: Changing view acls to: root
22/04/14 18:35:59 INFO spark.SecurityManager: Changing modify acls to: root
22/04/14 18:35:59 INFO spark.SecurityManager: Changing view acls groups to:
22/04/14 18:35:59 INFO spark.SecurityManager: Changing modify acls groups to:
22/04/14 18:35:59 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/04/14 18:35:59 INFO util.Utils: Successfully started service 'sparkDriver' on port 46193.
22/04/14 18:35:59 INFO spark.SparkEnv: Registering MapOutputTracker
22/04/14 18:35:59 INFO spark.SparkEnv: Registering BlockManagerMaster
22/04/14 18:35:59 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/04/14 18:35:59 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/04/14 18:36:00 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-4bec553e-97cf-450d-a324-b7e8deb92dd2
22/04/14 18:36:00 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
22/04/14 18:36:00 INFO spark.SparkEnv: Registering OutputCommitCoordinator
22/04/14 18:36:00 INFO util.log: Logging initialized @1195ms
22/04/14 18:36:00 INFO server.Server: jetty-9.2.z-SNAPSHOT
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3aee3976{/jobs,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5ef8df1e{/jobs/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27cf3151{/jobs/job,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@127e70c5{/jobs/job/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5910de75{/stages,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4108fa66{/stages/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1f130eaf{/stages/stage,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7e0aadd0{/stages/stage/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@21362712{/stages/pool,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27eb3298{/stages/pool/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@200a26bc{/storage,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@bc57b40{/storage/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1b5bc39d{/storage/rdd,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@655a5d9c{/storage/rdd/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1494b84d{/environment,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@34abdee4{/environment/json,null,AVAILABLE,@Spark}
22/04/14 18:36:00 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHand 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









