






目录
一、污点
节点亲和性,是Pod的一种属性(偏好或硬性要求),它使Pod被吸引到一类特定的节点。Taint 则相反,它使节点能够排斥一类特定的 Pod。
Taint 和 Toleration 相互配合,可以用来避免 Pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 Pod,是不会被该节点接受的。如果将 toleration 应用于 Pod 上,则表示这些 Pod 可以(但不一定)被调度到具有匹配 taint 的节点上。
使用 kubectl taint 命令可以给某个 Node 节点设置污点,Node 被设置上污点之后就和 Pod 之间存在了一种相斥的关系,可以让 Node 拒绝 Pod 的调度执行,甚至将 Node 已经存在的 Pod 驱逐出去。
污点的组成格式如下:
key=value:effect
每个污点有一个 key 和 value 作为污点的标签,其中 value 可以为空,effect 描述污点的作用。
当前 taint effect 支持如下三个选项:
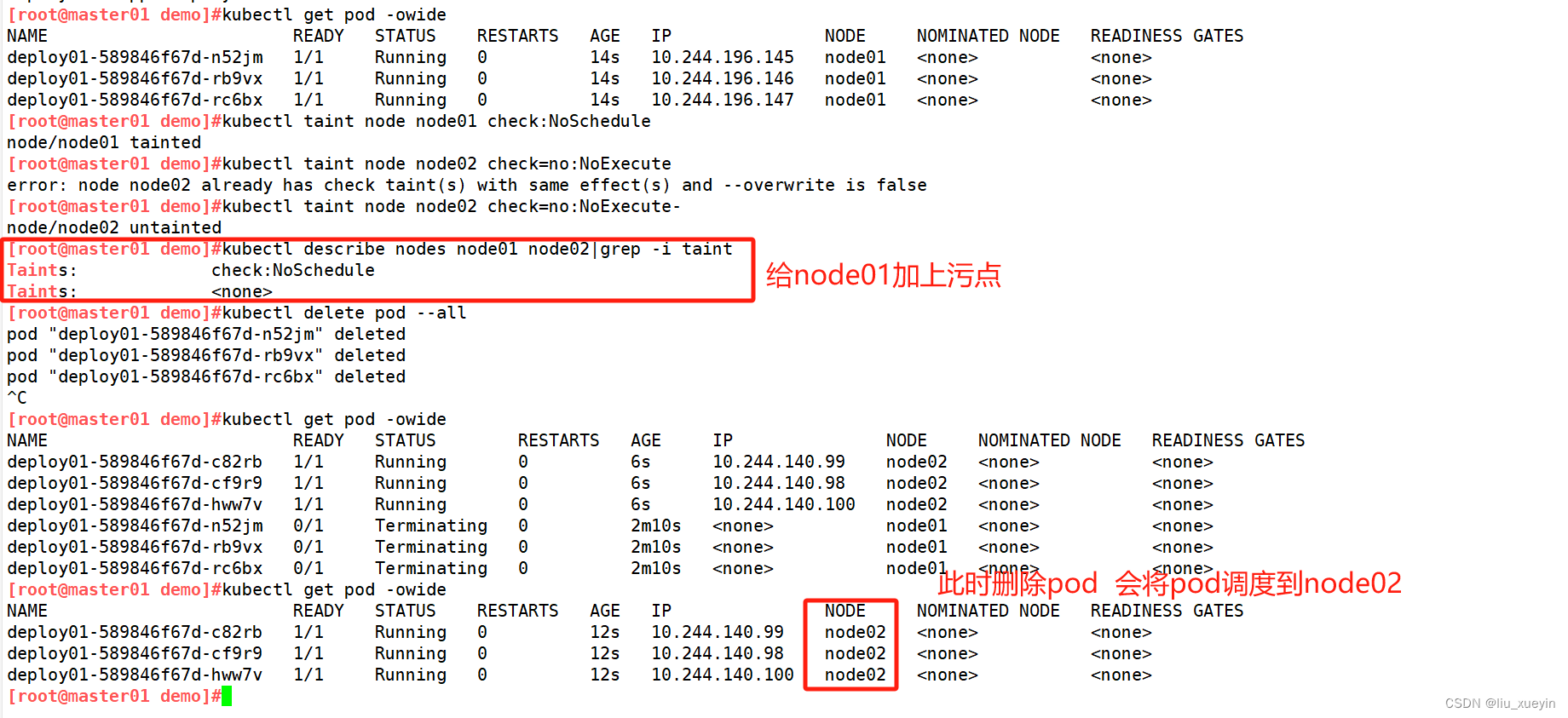
●NoSchedule:表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上
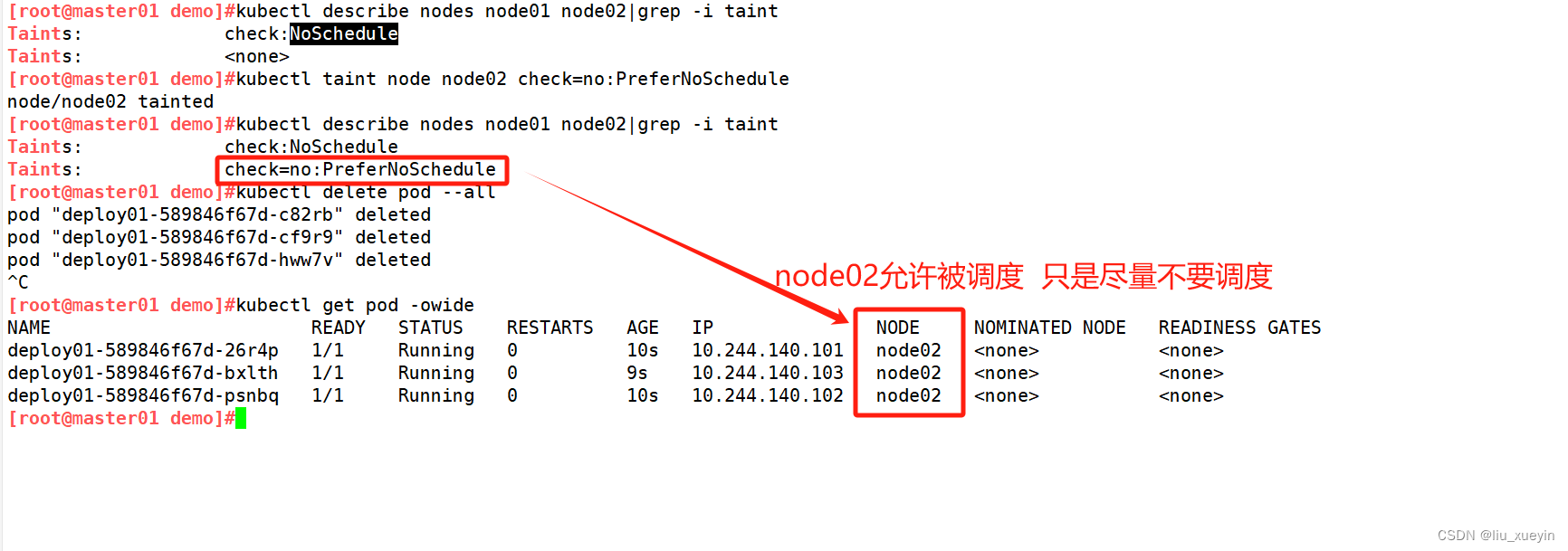
●PreferNoSchedule:表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
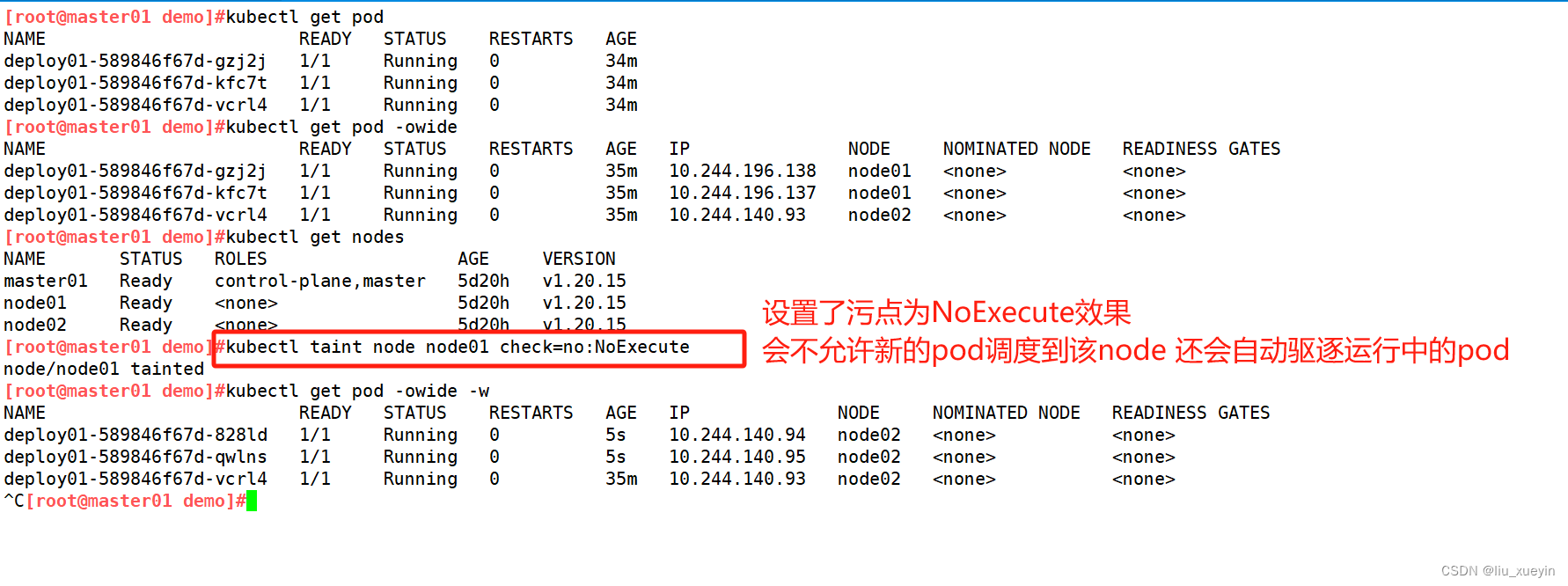
●NoExecute:表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐出去
关于污点的增删改查
kubectl taint node node01 键名=键值:NoSchedule
//增加污点
kubectl taint node node01 键名=键值:NoSchedule-
kubectl taint node node01 键名-
//删除
kubectl describe nodes node01|grep -A5 -i taint
//查看
验证污点的作用——NoExecute
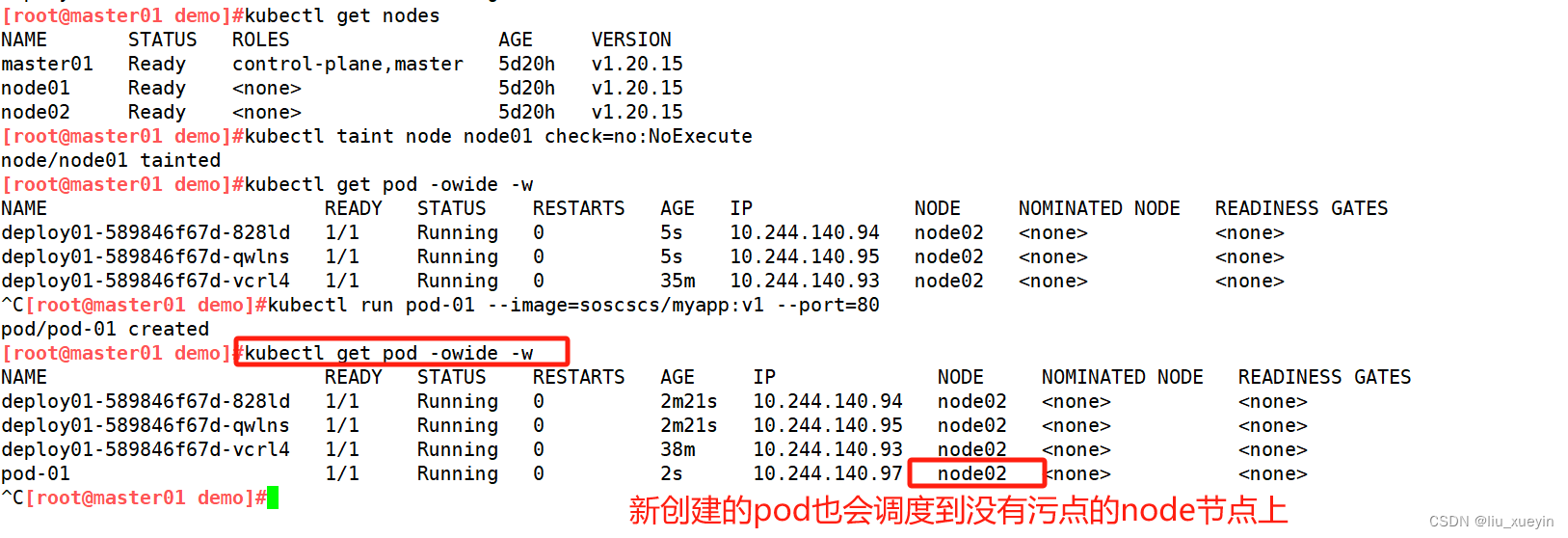
 验证污点的作用——NoSchedule
验证污点的作用——NoSchedule
验证污点的作用——PreferNoSchedule
二、容忍
设置了污点的 Node 将根据 taint 的 effect:NoSchedule、PreferNoSchedule、NoExecute 和 Pod 之间产生互斥的关系,Pod 将在一定程度上不会被调度到 Node 上。但我们可以在 Pod 上设置容忍(Tolerations),意思是设置了容忍的 Pod 将可以容忍污点的存在,可以被调度到存在污点的 Node 上。
apiVersion: v1
kind: Pod
metadata:
name: myapp01
labels:
app: myapp01
spec:
containers:
- name: with-node-affinity
image: soscscs/myapp:v1
tolerations:
- key: "check"
operator: "Equal"
value: "no"
effect: "NoExecute"
tolerationSeconds: 3600

#其中的 key、vaule、effect 都要与 Node 上设置的 taint 保持一致
#operator 的值为 Exists 将会忽略 value 值,即存在即可
#tolerationSeconds 用于描述当 Pod 需要被驱逐时可以在 Node 上继续保留运行的时间
//其它注意事项
(1)当不指定 key 值时,表示容忍所有的污点 key
tolerations:
- operator: "Exists"
(2)当不指定 effect 值时,表示容忍所有的污点作用
tolerations:
- key: "key"
operator: "Exists"
(3)有多个 Master 存在时,防止资源浪费,可以如下设置
kubectl taint node Master-Name node-role.kubernetes.io/master=:PreferNoSchedule
//如果某个 Node 更新升级系统组件,为了防止业务长时间中断,可以先在该 Node 设置 NoExecute 污点,把该 Node 上的 Pod 都驱逐出去
kubectl taint node node01 check=mycheck:NoExecute
//此时如果别的 Node 资源不够用,可临时给 Master 设置 PreferNoSchedule 污点,让 Pod 可在 Master 上临时创建
kubectl taint node master node-role.kubernetes.io/master=:PreferNoSchedule
//待所有 Node 的更新操作都完成后,再去除污点
kubectl taint node node01 check=mycheck:NoExecute-
三、关于cordon 和 drain
##对节点执行维护操作:
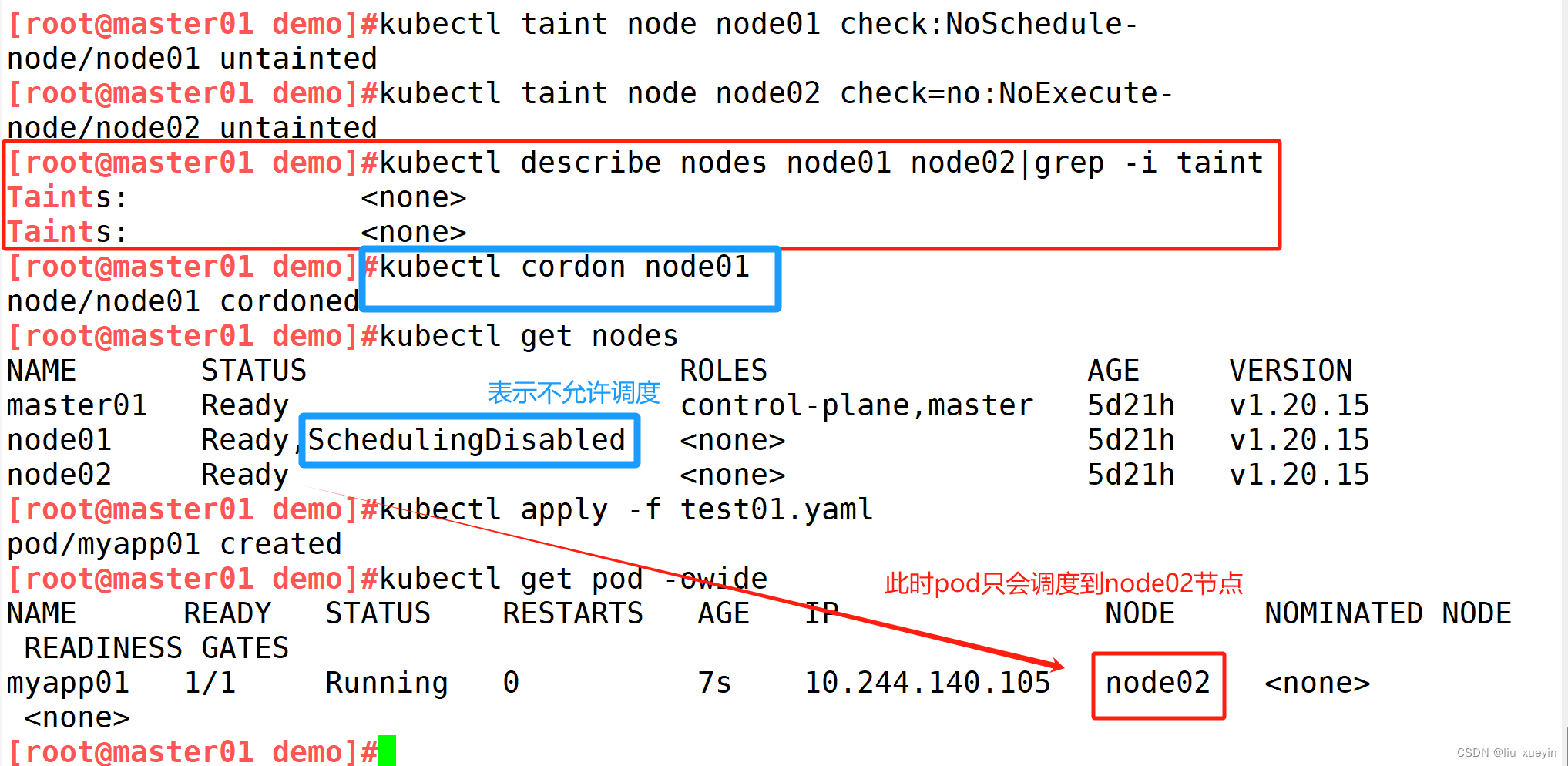
kubectl get nodes
//将 Node 标记为不可调度的状态,这样就不会让新创建的 Pod 在此 Node 上运行
kubectl cordon <NODE_NAME> #该node将会变为SchedulingDisabled状态cordon
drain
//kubectl drain 可以让 Node 节点开始释放所有 pod,并且不接收新的 pod 进程。drain 本意排水,意思是将出问题的 Node 下的 Pod 转移到其它 Node 下运行
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data --force
--ignore-daemonsets:无视 DaemonSet 管理下的 Pod。
--delete-emptydir-data:如果有 mount local volume 的 pod,会强制杀掉该 pod。
--force:强制释放不是控制器管理的 Pod。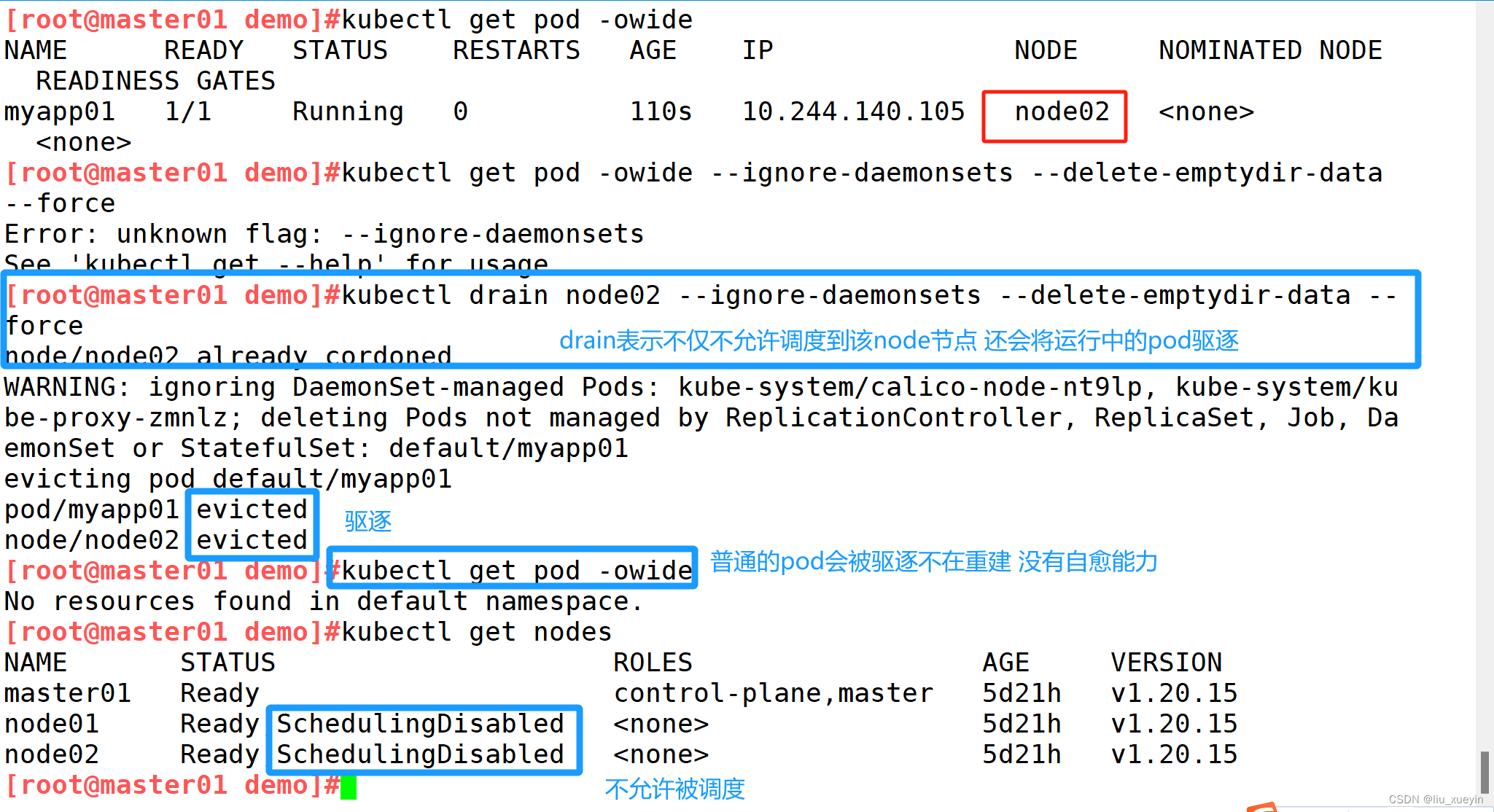
注:执行 drain 命令,会自动做了两件事情:
(1)设定此 node 为不可调度状态(cordon)
(2)evict(驱逐)了 Pod
四、Pod启动阶段
第一步:controller manager管理的控制器创建pod副本
第二步:scheduler调度器根据调度算法选择最合适的node节点调度pod
第三步:kubelet拉取镜像
第四步:kubelet挂载存储卷
第五步:kubelet创建并运行容器
第六步:kubelet根据容器探针的探测结果设置Pod状态
五、关于pod的五种状态
Pending:Pod已经创建,但是Pod还处于包括未完成调度到node节点或者还处于在拉取镜像的过程中、存储卷挂载失败的情况
Running:Pod所有容器已被创建,且至少有一个容器正在运行
Succeeded:Pod所有容器都已经成功退出,且不再重启。(Completed)
Failed:Pod所有容器都已经退出,且至少有一个容器是异常退出的。(Error)
Unknown:master节点的controller manager无法获取到Pod的状态信息,通常是因为master节点的apiserver与Pod所在node节点的kubelet通信失联导致的(比如node节点宕机或kubelet进程故障)
总结:Pod遵循预定于的生命周期,起始于Pend阶段,如果至少有一个容器正常运行,则进Running阶段,之后取决于Pod是否有容器以失败状态退出而进入Succeeded或Failed阶段。
六、k8s常见的排障手段
针对组件故障
kubectl get nodes 查看node节点运行状态
kubectl describe nodes <node节点名称> 查看node节点的详细信息和资源描述
kubectl get cs 查看master组件的健康状态
kubectl cluster-info 查看集群信息
journalctl -u -f kubelet 跟踪查看kubelet进程日志针对pod故障
kubectl get pods -o wide 查看Pod的运行状态和就绪状态
kubectl describe <pods|其它资源类型> <资源名称> 查看资源的详细信息和事件描述,主要是针对处于Pending状态的故障
kubectl logs <Pod资源名称> -c <容器名称> -f -p 查看Pod容器的主进程日志,主要是针对进入Running状态后的故障,比如Failed异常问题
kubectl exec -it <Pod资源名称> -c <容器名称> sh|bash 进入Pod容器查看容器内部相关的状态信息,比如进程、端口、文件、流量等状态信息
kubectl debug -it <Pod资源名称> --image=<临时工具容器的镜像名> --target=<目标容器> 在Pod中创建临时工具容器进入目标容器进行调试,主要针对没有调试工具的容器使用
nsenter -n --target <容器ID> 在Pod容器宿主机使用nsenter转换网络namespace,直接在宿主机进入目标容器的网络命名空间进行抓包等调试工作针对网络故障
kubectl get svc 查看service资源的clusterIP、port、nodePort等信息
kubectl describe svc <svc资源名称> 查看service资源的标签选择器、endpoints端点等信息
kubectl get pods --show-lables 查看Pod的标签















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











