







pod其实就是容器,不过它是一个被包装起来的容器,因为pod里面有很多策略,是容器没法直接实现的,如镜像的各种下载策略、容器重启策略等,在实际工作中,很难有机会单独创建pod,因为意义不大,手动一个个创建pod并不能给我们带来便捷性,手动创建的pod挂掉后也不会帮我们自动重启
所以我们一般会通过控制器来管理pod,控制器里都会定义pod的模板
一、pod的基本管理
(1)创建pod
创建pod可以通过两种方式:
a.命令行的方式
#三个可选的镜像下载策略:
# 1.Always——不管本地是否存在该镜像,每次创建都会去拉取
# 2.IfNotPresent——优先使用本地镜像,若本地没有该镜像,才会去拉取
# 3.Nerver——从不拉取,只使用本地的
#“=”可以省略
kubectl run [pod名] --image=[镜像名] --image-pull-policy=[镜像下载策略]
#例:
#先拉取nginx镜像
nerdctl pull nginx
#创建pod
kubectl run pod1 --image nginx --image-pull-policy IfNotPresent
可以通过kuberctl --help查看可以指定哪些参数
b.yaml文件方式创建
更推荐这种方式,因为在yaml文件里可以指定更多的选项,更适合我们去定制我们想要的pod
怎么获得yaml文件?
——复制官网的模板
——通过命令行生成
通过命令行的方式生成yaml,这里镜像用nginx为例:
# --dry-run 表示模拟创建,并非真的创建出来,有两个值可选[client/server]
# -o yaml 表示以yaml的格式输出
# > pod1.yaml 重定向输出到pod1.yaml文件里(后缀得是.yaml或.yml)
kubectl run pod1 --image nginx --image-pull-policy IfNotPresent --dry-run=client -o yaml > pod1.yaml
以下就是根据命令行输出的yaml文件,我们来进行分析
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod1
name: pod1
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
kind: Pod 表示资源类型为pod
apiVersion: v1 每种资源都有对应一个apiVersion,怎么知道各资源的apiVersion是什么呢?可以通过kubectl api-resources看到
metadata 元数据,这里定义了包括pod的标签、pod名,也可以定义命名空间,不定义则是默认命名空间
...
kine: Pod
metadata:
creationTimestamp: null
labels:
run: pod1
name: pod1
namespace: 命名空间名
sepc:
...
spec 规格,这里面定义了包括容器containers,容器可以是一个或多个,及一些策略dnsPolicy、restartPolicy
containers项表示这个pod下的容器(可以包括多个容器),每个image项表示一个该镜像的容器
(1)定义容器内变量:
每个容器下也可以定义变量,通过env定义,如容器中用到了mysql,我们想定义mysql变量
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
env:
- name: [变量名1]
value: [变量值1]
- name: [变量名2]
value: [变量值2]
...
注意:若变量值是数字,必须要加上引号
例如:
- name: xxx
value: "8888"
(2)配置容器的端口映射:
通过ports来定义(ports与env、image等同一级),containerPort为容器端口,hostPort为宿主机端口,如以下将容器端口80端口映射到宿主机端口8888
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
ports:
- name: httpxxx
containerPort: 80
hostPort: 8888
...
(3)指定多个容器:
一个pod里指定多个容器,每个image项表示该镜像的一个容器,各容器名不能重复,这里定义两个容器,一个名为c1,一个名为c2
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: c1
resources: {}
- image: nginx
imagePullPolicy: IfNotPresent
name: c2
resources: {}
...
(4)以特权方式运行某个容器:
若要进入容器并修改相关内核参数,默认则不能修改,需要添加一个安全系数相关参数(详见下面 “进入pod” 相关内容)
添加以下配置项:
securityContext:
privileged: true
修改后为:
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
securityContext:
privileged: true
...
(5)使pod内容器共享宿主机的网络空间
在spec下增加一个参数 “hostNetwork”,值为 “true”,就相当于docker或nerdctl中nerdctl run ....... --network=host
...
spec:
hostNetwork: true
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
(6)指定容器启动后运行的进程
例:若定义一个pod,里面包含两个nginx容器c1和c2,创建好pod后,通过kubectl get pods查看pod状态,就会发现READY为1/2,即其中一个容器启动失败,这是因为容器c1、c2镜像都是nginx,当容器运行的时候默认端口都是80,所以产生端口冲突了,因此有一个容器会出错,在一个容器上加上一个“command”选项,表示指定容器启动后运行什么进程,指定了后就会覆盖原来镜像中CMD指定的进程,这里指定休眠10000000毫秒,因此就不会运行原来nginx的守护进程,就不会去占用端口80
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
command: ["sh","-c","sleep 10000000"]
...
除了以上写法外还有以下两种写法
command:
- sh
- -c
- "sleep 10000000"
#-----------------
args:
- sh
- -c
- "sleep 10000000"
若想知道更多的定义pod的yaml文件信息,可通过kubectl explain pod查询、
查询yaml中spec下kubectl explain pod.spec、
查询spec下的containerkubectl explain pod.spec.container等逐级查看
根据yaml文件创建pod
kubectl apply -f xxx.yaml
创建pod后,查看pod状态(是否创建成功)
#列出默认命名空间下的所有pods,可查看各pod的NAME、READY、STATUS等
kubectl get pods
# STATUS会有以下几种状态:
#(1)ContainerCreating——正在创建容器
#(2)ErrImagePull——镜像拉取错误,因网络或其他原因,镜像拉取错误,如本地已存在nginx镜像,但镜像拉取策略为always,又因网络问题镜像一直拉取不下来,又或者是访问不了国外镜像源,一直拉取失败
#(3)Running——pod创建成功,正在运行
# READY的含义:
#2/2表示该pod内共有两个容器,并且两个容器都是运行状态,1/2表示只有一个容器在运行
查看pod在哪个节点上运行
#加上-o wide,可看到NODE信息(在哪个节点运行),及IP(在哪个网段)
kubectl get pods -o wide
查看pod里包括的容器
nerdctl ps | grep [pod名]
pod里的容器是不需要ip地址的,因为pod里的容器会共享pod的网络空间,只要访问pod的ip地址,就能访问到容器
(2)pod的生命周期、重启策略
由于容器的存活时间由容器内的进程决定,容器内的进程结束了,容器也就结束了,而pod是包在容器外面的壳,因此pod里所有的容器都结束了,pod也就结束了,不同于容器的是,pod里有重启策略restartPolicy
restartPolicy定义在pod的yaml文件中,如下:
...
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
...
可以通过kubectl explain pod.spec查看restartPolicy有哪些值
可以看到有这三个值:
Always————pod只要结束了、到期了、没有在运行,就会重启
Never————不管pod是正常退出还是不正常退出,都不重启
OnFailure————只有出错了、失败了才重启,若是正常结束、退出,则不重启
(3)进入pod
在docker或nerctl中,我们想进入容器,通过nerdctl exec -it [容器名/ID] 进入
1.进入pod内的容器,pod内只有一个容器时
#进入pod并打开bash
kubectl exec -it [pod名] -- bash
#进入pod并执行/tmp命令
kubectl exec -it [pod名] -- /tmp
2.pod内存在多个容器时
存在多个容器时,若不指定,则默认进入的是定义在前面的容器,若要进入指定的容器:
# -c 指定进入的容器并打开bash
kubectl exec -it [pod名] -c [容器名] -- bash
3.进入pod内容器后,想要进行一些操作时的注意事项:
(1)修改内核参数
进入pod,并打开bash后,若想修改容器的内核参数,例如:echo 10 > /proc/sys/vm/swappiness,会发现系统不让我们修改,因为pod内容器占用的是宿主机的cpu、内存,修改内核参数的话,修改的也是宿主机的内核参数,会有安全限制
若想修改,则需要在定义pod的yaml中的image下增加一个安全系数相关的参数 “securityContext”,值改为以特权方式运行
securityContext:
privileged: true
修改如下:
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
securityContext:
privileged: true
...
用修改好后的yaml文件创建pod,然后进入pod的bash后就可以进行修改了echo 10 > /proc/sys/vm/swappiness
(若是pod内有多个容器,用-c指定进入容器)
(2)将宿主机文件拷贝到容器中
例:
进入pod内的容器,并执行 ls /tmp 命令,查看/tmp下的文件
kubectl exec -it pod1 -- ls /tmp
拷贝宿主机/etc/issue这个文件到容器/tmp下
kubectl cp /etc/issue pod1:/tmp
进入容器查看/tmp下已经有issue了
kubectl exec -it pod1 -- ls /tmp
若是pod内有多个容器,则-c指定容器,如:
kubectl cp /etc/issue pod1:/tmp -c [容器名]
(3)将pod内容器里的文件拷贝到宿主机中
例:
将容器内的/etc/hosts文件拷贝到宿主机/hosts下
kubectl cp pod1:/etc/hosts ./hosts
(4)删除pod、pod的宽限期
kubectl delete pod [pod名称]
#或
kubectl delete -f xxx.yaml
有时候,当删除一个pod时,会发现等待好久也删不掉这个pod,大概等待30s,才有反应——这就是宽限期的策略
宽限期:
执行删除pod的命令时,若此时pod内有业务正在工作,则会等待pod继续工作一会,最多等待30s,然后删除——优雅的关闭pod
若不想优雅的关闭,直接关闭它,或者修改宽限的时间,可以通过修改pod.yaml文件来实现
通过命令kubectl explain pod.spec,可以查看到 “terminationGracePeriodSeconds” 这个属性及说明,默认是30s
我们可以在pod的yaml文件中增加这个配置
如下设置:设置为0则不会等待,直接关闭,也可以修改为任意时长
...
spec:
terminationGracePeriodSeconds: 0
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
...
不想等待,也可以强制删除
# --force 强制删除
kubectl delete pod [pod名称] --force
(5)查看pod的属性及修改
查看资源属性的通用语法
kubectl describe [资源类型] [资料名字]
查看pod的属性
kubectl describe pod [pod名]
(6)查看pod的日志输出
查看pod的日志输出,作为排错时的依据
kubectl logs [pod名]
若是pod内有多个容器,则用-c指定
kubectl logs [pod名] -c [容器名]
(7)pod的钩子进程
钩子进程介绍
前面我们说过,若想让容器启动时运行我们自定义的主进程,可以在pod的yaml文件中配置command属性,而配置了command,就会覆盖镜像中默认的主进程,要想运行镜像原来默认的主进程,就只能将command去掉,只能二选一
如下配置:配置了启动便sleep 10000000秒,就不会运行nginx默认的主进程
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
command: ["sh","-c","sleep 10000000"]
...
虽然command自定义的主进程和镜像中默认的主进程不能同时存在,即容器内只能有一个主进程,但是我们若想既能运行容器的主进程,同时也能运行另外一个进程,这就需要pod里的钩子进程——pod hook
钩子进程pod hook中有两个属性:postStart和preStop
postStart
在容器启动的时候就开始启动的一个进程,这个进程与容器中的主进程没有先后顺序,而是在创建pod的时候同时启动的,这个进程不执行完毕,则pod的状态一直是ContainerCreating(正在创建容器),等到它执行完毕了,pod的状态才变为Running
在pod.yaml里的lifecycle项里定义:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
command: ["sh","-c","sleep 10000000"]
lifecycle:
postStart:
exec:
command: [......]
preStop
在pod被关闭之前要启动的一个进程,但这个进程的执行时间也得在宽限期的时间范围内,若宽限期terminationGracePeriodSeconds被设置成了0,那么在关闭pod的时候,也不会执行这个进程,直接关闭
若这个进程执行的时间小于宽限期的时间,那么关闭pod的时候,也还是会等到宽限期时间到了再关闭,总之关闭pod的时候都按宽限期为准
在pod.yaml里的lifecycle项里定义:
...
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
command: ["sh","-c","sleep 10000000"]
lifecycle:
preStop:
exec:
command: [......]
...

(8)pod的状态
Pending:pod因为其他的原因导致pod准备开始创建,还没有创建(卡住了)
Running:pod已经调度成功,也就是它包含的容器都已经创建成功,并且至少有一个容器正在运行中
Completed:pod里所有容器正常退出
CrashLoopBackOff:创建的时候就出错,属于内部原因(如端口冲突、内部程序报错等)
imagePullBackoff:创建pod的时候,镜像下载失败
二、初始化pod及静态pod
初始化pod
在pod的yaml文件中,在containers下定义的容器,称之为普通容器,假设这个容器要正常运行的话,需要一定的先决条件,我们的环境又不一定满足,若不满足,则容器无法运行起来
我们可以通过常见初始化容器来打头阵,做一些初始化的操作,可以有多个初始化容器,无论先定义了普通容器还是先定义了初始化容器,都先会运行初始化容器,只要当所有的初始化容器都执行完毕,且正确了,才会创建普通容器,若某个初始化容器错误了,则后续的初始化容器便不再创建了,普通容器自然也没法继续了
配置初始化容器
在yaml文件中通过initcontainers配置
例:假设要运行某容器,需要将系统参数vm.swappiness设置为0才行
拉取alpine镜像
nerdctl pull alpine
配置两个初始化容器
一个nginx容器,自定义主进程为sleep15秒
另一个为alpine容器,自定义进程去修改系统参数vm.swappiness=0,因为要修改参数,所以要以特权的方式运行
...
spec:
terminationGracePeriodSeconds: 0
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
initContainers:
- name: c1
image: nginx
command: ["sh","-c","sleep 15"]
- name: c2
image: alpine
command: ["sh","-c","/sbin/sysctl -w vm.swappiness=0"]
securityContext:
privileged: true
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
...
创建该pod
kubectl apply -f xxx.yaml
静态pod
对于整个集群的管理,都是要连接到master上的kube-apiserver上来,通过kubectl get pods -n kube-system查看k8s必须的组件的pod,若这些pod没正常运行,就代表master是没有正常工作的,但是master没有工作,又是谁把这些pod运行起来的呢?这就是一个先有鸡还是先有蛋的问题了
——是由静态pod来实现的
所谓静态pod就是,不是master上创建,不由master管理,而是由kubelet直接管理的pod,
要创建静态pod,我们只要把一个pod的yaml文件放在/etc/kubernetes/manifests目录下,kubelet就会自动把他创建出来
编辑/var/lib/kubelet/config.yaml
vim /var/lib/kubelet/config.yaml
可以看到静态pod路径配置项:
配置了staticPodPath: /etc/kubernetes/manifests
...
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
...
kubelet会到此目录下去加载apiserver、etcd、controller-manager、kube-scheduler
这个目录下有以下文件:
ls /etc/kubernetes/manifests
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
实验:创建一个静态pod
在/etc/kubernetes/manifests下创建一个pod的yaml文件:
vim /etc/kubernetes/manifests/pod1.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod1
name: pod1
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod1
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: OnFailure
status: {}
查看所有命名空间里的pod
kubectl get pods --all-namespaces 简写:kubectl get pods -A
可以看到这个pod在默认命名空间中被创建出来了
若删除掉这个yaml文件,这个pod也就没有了
若想修改默认的staticPodPath,则需要提前将目录创建出来,然后将原目录下的内容复制过来(etcd.yaml、kube-apiserver.yaml、kube-controller-manager.yaml、kube-scheduler.yaml),然后在/var/lib/kubelet/config.yaml中修改好后重启kubeletsystemctl restart kubelet
使用静态pod的场景?
其实使用静态pod的场景不多,主要的场景就是把master本身启动起来(kube-system命名空间下这些pod),第二个可能用到的场景就是,若master宕机了,此时想创建pod都创建不了了,但是worker还可以正常工作,此时想对外提供一个服务、通知,就可以创建一个共享宿主机网络的临时pod
三、pod的调度
(1)kube-apiserver调度
但用户发送了一个创建pod的请求,首先kube-apiserver会接收请求,然后kube-scheduler来调度由哪个节点来创建
那么kube-scheduler是怎样来进行调度的呢?
首先kube-scheduler会考虑这么几个因素:
(1)当前有多少个等待被创建的pod——待调度的pod列表
有很多的场景中都会需要同时创建很多个pod
(2)有哪些可用节点(状态为Ready的节点),若状态不是Ready的话,是不会被调度的
(3)在第二个因素的基础上,即状态为Ready的节点,不一定Ready的节点就一定可用,还要排除掉一些节点,如:
a.有污点的节点
b.若在该节点创建该pod,会与节点内的其他pod产生冲突(如端口冲突等)
c…
在符合条件的节点中,kube-scheduler又会有自己的算法,来根据各节点的cpu及内存的负载等来进行打分,最后择出最优节点来创建pod
因此,在创建pod的时候,我们自己是无法判断这个pod最后会由哪个节点创建的,只能是创建后通过kubectl get pods -owide来查看pod运行在哪个节点上
那么我们有没有办法,来手动控制某个pod就是要运行在worker1上或者是worker2上呢?
(2)如何手动指定pod在哪个节点上运行
——在pod的yaml文件的spec这项下来指定
方式一:通过nodeName来指定,这种方式,即使是节点上有污点也是可以运行
#1.列出所有节点,查看节点名称NAME
kubectl get nodes
#2.yaml文件中,配置nodeName属性,将完整的节点名称写上
...
spec:
nodeName: [完整的节点名称]
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
方式二:通过标签的方式进行控制(在k8s环境里,万事万物都有标签)
标签相关的内容,可以回看【三、kubernetes集群管理】中的【资源的标签相关】内容
我们可以设置让pod在含有某个标签的节点上运行
例如,我们可以先在vms22这个节点上设置一个标签xx=xx
kubectl label nodes vms22.rhce.cc xx=xx
让pod1在含有xx=xx标签的节点上运行,在yaml文件中的spec下通过nodeSelector(节点选择器)项配置
...
spec:
nodeSelector:
xx: xx
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
现假设实际中没有含有xx=xx这个标签的node,则创建pod的时候,状态为“Pending”(找不到合适的node,卡住了)
现假设满足含有xx=xx的标签的node有多个,则kube-scheduler又会根据它的算法在所有合适的node中进行打分
方式三:主机亲和性
这里会涉及到两种策略:硬策略、软策略
硬策略:必须满足条件
软策略:若不满足条件,也没关系
在yaml文件中spec下通过affinity项进行配置
a.软策略:
...
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 2
preference:
matchExpressions:
- key: bb
operator: Gt
values:
- "3"
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
例:
假设现在有两个节点vms22、vms23,现在分别对这两个节点设置标签
vms22:aa=1,bb=10
vms23:aa=10,bb=1
kubectl label nodes vms22.rhce.cc aa=1
kubectl label nodes vms22.rhce.cc bb=10
kubectl label nodes vms23.rhce.cc aa=10
kubectl label nodes vms23.rhce.cc bb=1
软策略的配置matchExpressions,意为表达式
...
- key: bb
operator: Gt
values:
- "3"
...
如上的表达式意为:键为bb的标签,值大于3(Gt大于、Ge大于等于、Lt小于、Le小于等于、Ne不等于、Eq等于)
即pod优先运行在标签键为bb、值大于3的节点上——即运行在vms22上
此时有两个表达式,如下所示,既要aa>3,又要bb>3,按照现在的环境,没有同时满足这两个条件的节点,即两个表达式冲突了,这个时候就需要看weight(权重)这个属性,权重大的,优先根据这个条件来——即运行在vms22上
...
- weight: 2
preference:
matchExpressions:
- key: aa
operator: Gt
values:
- "3"
- weight: 3
preference:
matchExpressions:
- key: bb
operator: Gt
values:
- "3"
...
假设此时的表达式为aa>30,则现在并没有满足条件的节点,但是pod也能创建成功,它会运行在更接近条件的节点中,即vms23
...
- weight: 2
preference:
matchExpressions:
- key: aa
operator: Gt
values:
- "30"
...
b.硬策略:
...
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- vms62.rhce.cc
- vms63.rhce.cc
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
如上硬策略的表示式意为:标签的键为kubernetes.io/hostname,值为vms62.rhce.cc或vms63.rhce.cc
此时没有满足这个条件的节点,因为是硬策略,因此pod不会创建成功,状态为 “Pending” 卡住了
(3)警戒线cordon
如果一个node被标记为cordon,则新创建的pod不会被调度到此node上
已经调度上去的不会被移走,需要被删除让其重新生成
假设此时我们在vms22这个节点上设置了一个标签xx=xx
kubectl label nodes vms22.rhce.cc xx=xx
此时的yaml文件如下:通过nodeSelector配置,让pod1在含有xx=xx标签的节点上运行(vms22)
...
spec:
nodeSelector:
xx: xx
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
此时,假设我们要在vms22上进行测试、维护,不想让vms22上创建更多pod了,但是也不想影响vms22节点内现有的pod
就可以使用cordon操作,“让其休息”
#cordon语法
kubectl cordon [节点名]
#恢复就绪状态
kubectl uncordon [节点名]
对vms22进行cordon
kubectl cordon vms22.rhce.cc
此时kubectl get nodes,可以看到STATUS变成了“Ready,SchedulingDisabled”,此时vms22上就不会再接收更多的pod了,若再指定在vms22上创建,创建的pod的状态会是“Pending”,对于vms22内现有的pod,并不影响他们正常运行
NAME STATUS ROLES AGE VERSION
vms21.rhce.cc Ready control-plane 7d5h v1.24.2
vms22.rhce.cc Ready,SchedulingDisabled <none> 7d5h v1.24.2
vms23.rhce.cc Ready <none> 7d5h v1.24.2
让vms22恢复
kubectl uncordon vms22.rhce.cc
(4)节点的drain
如果一个节点被设置为drain,则此节点不再被调度pod,且此节点上已经运行的pod会被驱逐(evicted)到其他节点
drain其实包含了两步:cordon + evicted,先cordon然后evicted
evicted(驱逐):赶到其他节点上运行,要结合控制器一起使用,驱逐的本质是直接删除,因为控制器有再生功能,其实是在其他节点上重新生成一个,所以感觉上是驱逐
drain操作与cordon类似,常用于节点维护,区别于cordon的就是,除了不能继续在节点上创建pod外,节点内的pod也要一个个驱逐出去,但不会删除由控制器daemon-set所创建的pod
kubectl drain [节点名] --ignore-daemonsets --force
#恢复就绪状态
kubectl uncordon [节点名]
当对某个节点drain操作时,删除里面的pod,我们就会担心正在进行的业务被中断,但其实是不必担心的,因为用户在请求的时候,请求先到了svc,svc再把请求转发给某个节点的某个pod,当对某个节点进行drain操作时,他会删除pod,但是删除pod的时候,并不是马上就删除,就是前面所说的他还有一个宽限期,对于已连接的正在执行某个任务的pod,他会继续在宽限期内对外提供服务,只是这个pod的状态变为了Terminating关闭中…,总之状态不再是Running,后面再有新的请求,就会在其他的节点重新创建这个pod,然后新的请求就会转发到其他节点的这个pod了

四、节点的污点及pod的容忍度
现在我们的环境中vms21为master,vms22、vms23为worker
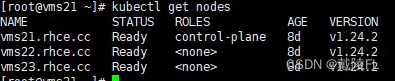
若我们不作任何指定,pod只会在vms22或vms23上运行,而不会在vms21上运行,为什么呢?——这就涉及到了节点的污点以及pod的容忍度
节点上存在污点,并且pod不能容忍,所以pod不会在该节点上运行,即使强行指定pod在该节点上运行,pod的状态的也是Pending
节点的污点 taint
查看节点的污点
kubectl describe nodes [节点名称]
#查看节点的污点(过滤关键字,并增加一行输出)
kubectl describe nodes [节点名称] | grep -A1 Taints
describe查看节点属性,向下拉,可以看到Taints这项属性,即节点的污点
我们可以看到vms21存在两个污点,而vms22、vms23中没有污点
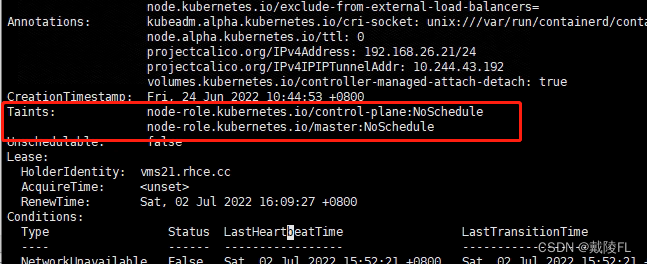
污点的格式与标签的格式类似,都是键值对的格式(键=值),在键值对后再加一个“:effect“,effect一般为NoSchedule
给节点设置污点
kubectl taint node [节点名] [污点键]=[污点值]:NoSchedule
例:给vms22设置污点xx=xx:NoSchedule
kubectl taint node vms22.rhce.cc xx=xx:NoSchedule
查看vms22的污点
kubectl describe nodes vms22.rhce.cc | grep Tiants

取消污点
取消污点和取消标签类似
kubectl taint node [节点名] [污点键]-
pod的容忍度 tolerations
因为节点有污点,因此pod不会在节点上运行,当然,我们可以设置让pod容忍这个污点,从而让pod可以在节点上创建
通过yaml文件中spec下配置tolerations这个属性
...
spec:
tolerations:
- effect: NoSchedule
key: xx
operator: [Exists/Equal]
containers:
- image: nginx
imagePullPolicy: IfNotPresent
...
tolerations下,effect的值一般设为NoSchedule,key即为污点的键,operator的值可以是Exists或是Equal,若operator的值为Exists,则表示不管污点的值是什么,只要污点的键是xx,pod就都容忍
若operator值为Equal,则需要加上值value
tolerations:
- effect: NoSchedule
key: xx
operator: Equal
value: xx
表示pod只容忍键为xx,并且值为xx的污点
若节点上有多个污点,想让pod在此节点上创建,就必须要容忍所有的污点
















 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











