







1.K-Means概述
无监督学习与聚类算法
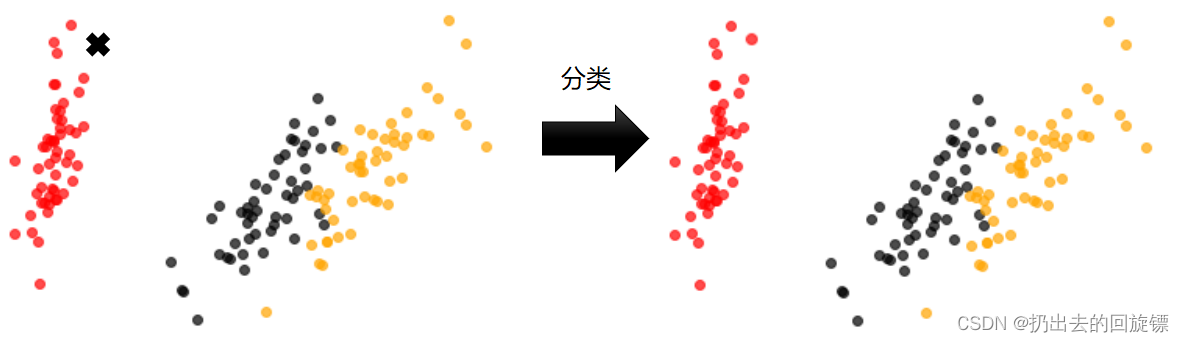
聚类算法是典型的无监督学习算法,即训练不需要特征的标签。聚类的目的是将数据划分成为有意义或者有用的组,用于帮助我们探索数据的自然结构和分布
分类和聚类

| 聚类 | 分类 | |
|---|---|---|
| 核心 | 将数据分成多个组 探索每个组的数据是否有联系 | 从已经分组的数据中去学习把新数据放到已经分好的组中去 |
| 学习类型 | 无监督,无需标签进行训练 | 有监督,需要标签进行训练 |
| 典型算法 | K-Means,DBSCAN,层次聚类,光谱聚类 | 决策树,贝叶斯,逻辑回归 |
| 算法输出 | 聚类结果是不确定的 不一定总是能够反映数据的真实分类 同样的聚类,根据不同的业务需求可能是一个好结果,也可能是一个坏结果 | 分类结果是确定的 分类的优劣是客观的,不是根据业务或算法需求决定 |
sklearn中的聚类算法
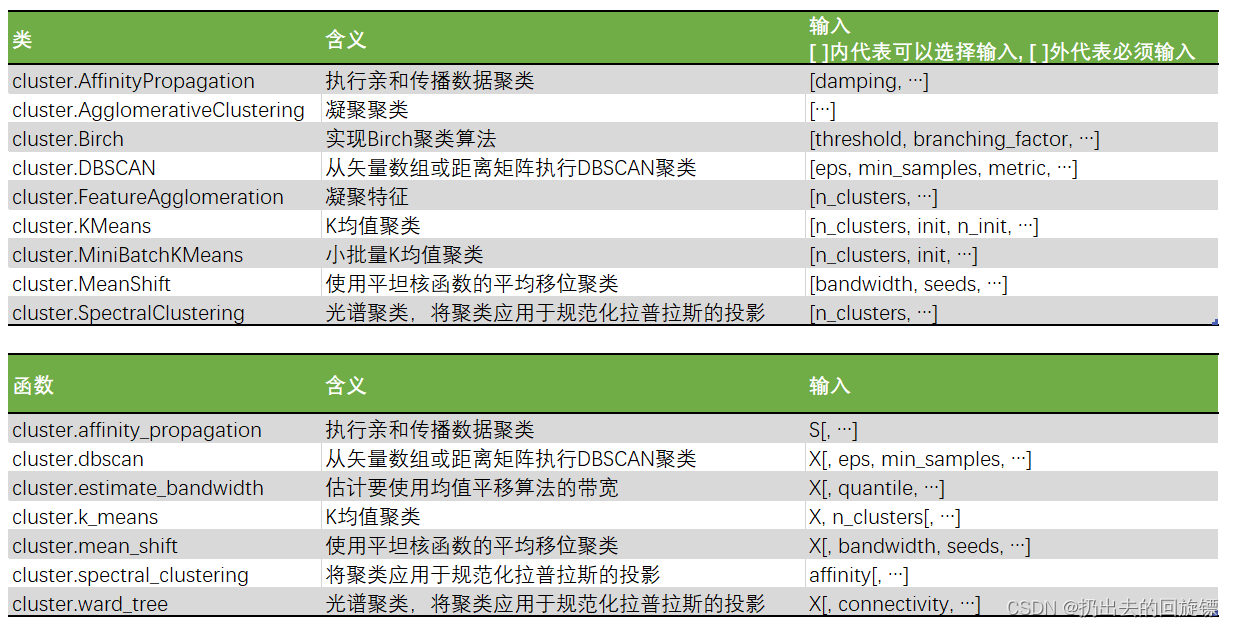
一种是需要实例化的类,训练并使用接口和属性来调用结果。另一种是函数,只需要输入特征矩阵和超参数即可返回聚类的结果和各种指标。
函数cluster.k_meanss

函数k_means会依次返回质心,每个样本对应的簇的标签,inertia以及最佳迭代次数
2.KMeans如何工作
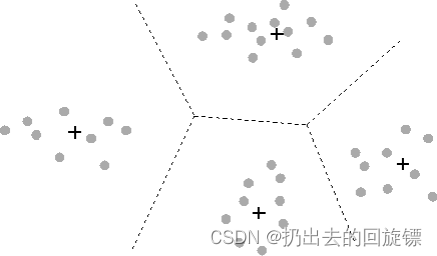
设定超参数K,找出K个最优的质心
具体过程如下:
- 随机抽取K个样本作为最初的质心
- 开始循环:
- 将每个样本点分配到离他们最近的质心,生成K个簇
- 对于每个簇,计算所有被分到该簇的样本点的平均值作为新的质心
- 当质心的位置不再发生变化,迭代停止,聚类完成

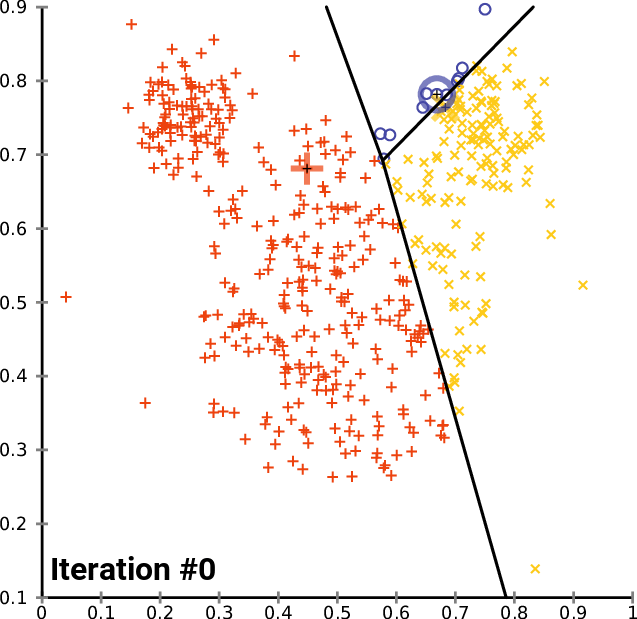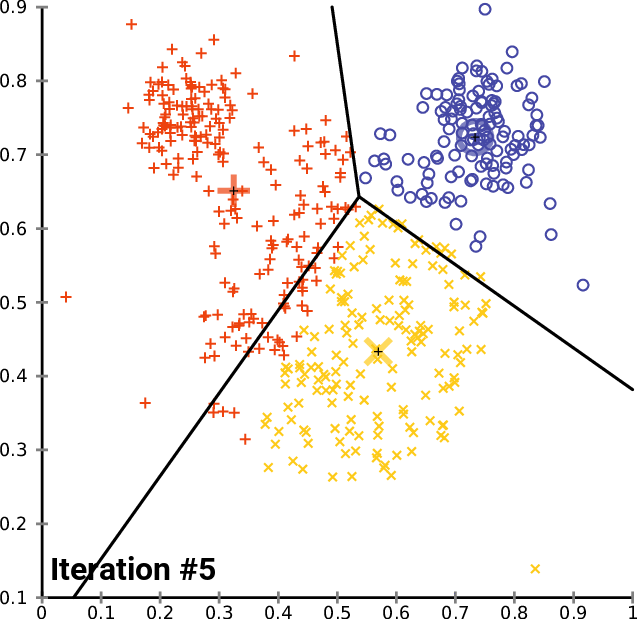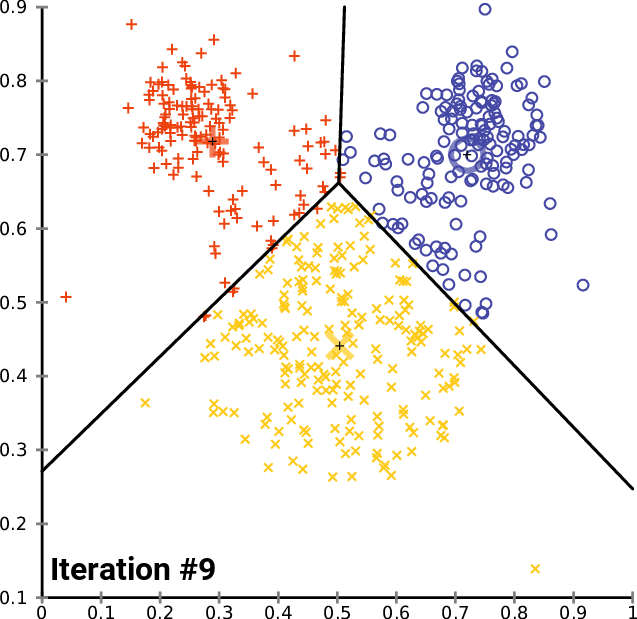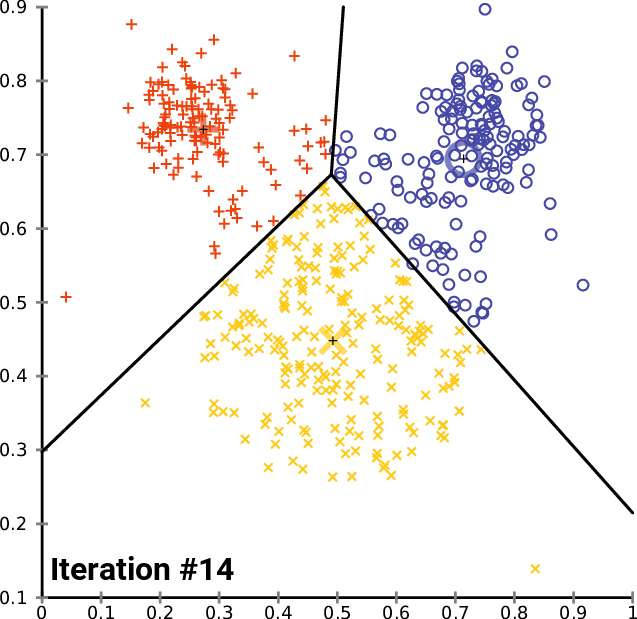
簇内误差平方和的含义
类似于分箱,将相似的数据做为一个簇,争取“簇内差异小,簇外差异大”,而这个差异有样本点到器所在簇的质心的距离衡量。常用衡量距离如下:
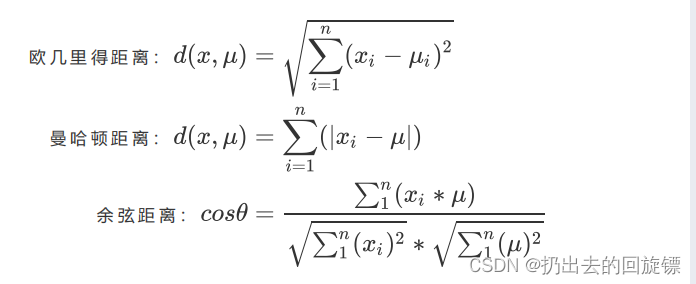
如采用欧几里得距离,则一个簇中所有样本点的距离的平方和为:
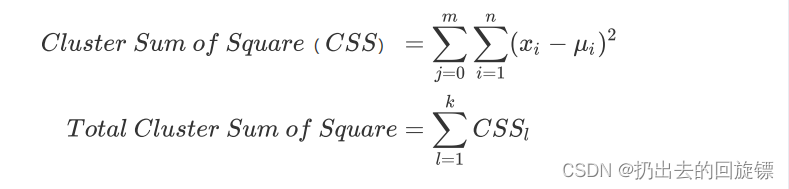
簇内平方和(CSS)m为一个簇中样本的个数,j为每个样本的编号。将一个数据集汇总所有簇的簇内平方和相加,就得到了整体平方和。Total Inertia越小,代表每个簇内样本月相似,聚类效果就越好。因此K-Means求解过程变成最优化问题
其他距离方式的Inertia
| 距离度量 | 质心 | Inertia |
|---|---|---|
| 欧几里得距离 | 均值 | 最小化每个样本点到质心的欧式距离之和 |
| 曼哈顿距离 | 中位数 | 最小化每个样本点到质心的曼哈顿距离之和 |
| 余弦距离 | 均值 | 最小化每个样本点到质心的余弦距离之和 |
是否可以认为Kmeans有损失函数
损失函数是用来衡量模型拟合效果的,只有有求解参数需求的算法才有损失函数。KMeans不进行参数的求解,也没有数据的拟合,所以本质上是不存在损失函数的。
但是由于Inertia和逻辑回归中损失函数的功能非常相似。可以认为Inertia具有损失函数的功能。但是对于决策树,有衡量分类效果的accuracy,准确度对应的损失叫做泛化误差,我们不能通过最小泛化误差来求解模型中需要的信息,我们只需需要模型效果上表现出来的泛化误差很小,因此决策树是绝对不存在损失函数的。
Kmeans算法的时间复杂度
KMeans算法的平均复杂度是
O
(
k
∗
n
∗
T
)
O(k*n*T)
O(k∗n∗T),其中k是我们的超参数,所需要输入的簇数,n是整个数据集中的样本量,
T是所需要的迭代次数。在最坏的情况下,KMeans的复杂度可以写作
O
(
n
k
+
2
p
O(n^\frac{k+2}{p}
O(npk+2,其中n是整个数据集中的样本量,p是特征总数。
聚类算法的模型评估指标
当使用inertia来作为聚类的衡量指标时的缺点:
1.太容易受到特征数目的影响,当数据维度很大时会导致计算量非常大,不适合用来评估;‘’
2.同时它受超参数k的影响,当K变大时必然导致inertia变小,但却不能代表模型效果变好;
3.inertia假设数据满足凸分布以及各向同性,即数据在不同方向代表相同的含义,但现实数据往往不符合这种规则,导致很多时候使用inertia作为评估指标表现一般
通常情况下,分两种情况来选择评估指标
第一种:真实标签已知
| 模型评估指标 | 说明 |
|---|---|
| 互信息分 普通互信息分 metrics.adjusted_mutual_info_score (y_pred, y_true) 调整的互信息分 metrics.mutual_info_score (y_pred, y_true) 标准化互信息分 metrics.normalized_mutual_info_score (y_pred, y_true) | 取值范围在(0,1)之中 越接近1,聚类效果越好 在随机均匀聚类下产生0分 |
| V-measure:基于条件上分析的一系列直观度量 同质性:是否每个簇仅包含单个类的样本 metrics.homogeneity_score(y_true, y_pred) 完整性:是否给定类的所有样本都被分配给同一个簇中 metrics.completeness_score(y_true, y_pred) 同质性和完整性的调和平均,叫做V-measure metrics.v_measure_score(labels_true, labels_pred) 三者能同时计算 metrics.homogeneity_completeness_v_measure(labels_true,labels_pred) | 取值范围在(0,1)之中越接近1,聚类效果越好 由于分为同质性和完整性两种度量,可以更仔细地研究,模型到底哪个任务做得不够好 对样本分布没有假设,在任何分布上都可以有不错的表现 在随机均匀聚类下不会产生0分 |
| 调整兰德系数 | 取值在(-1,1)之间,负值象征着簇内的点差异巨大,甚至相互独立,正类的兰德系数比较优秀,越接近1越好 对样本分布没有假设,在任何分布上都可以有不错的表现,尤其是在具有"折叠"形状的数据上表现优秀 在随机均匀聚类下产生0分 |
第二种:真实标签未知
大多数时候的情况都是如此。此时我们依靠轮廓系数来进行衡量,其定义如下:
1)样本与其自身所在簇中的相似度a,等于样本与同一簇中所有其他点之间的平均距离
2)样本与其他簇中样本的相似性,等于样本与下一个最近的簇中所有点之间的平均距离
s
=
b
−
a
m
a
x
(
a
,
b
)
s=\frac{b-a}{max(a,b)}
s=max(a,b)b−a
可以化简为:
s
=
{
1
−
a
b
,
a
<
b
0
,
a
=
b
b
a
−
1
,
a
>
b
s=\begin{cases} 1-\frac{a}{b}, a<b \\ 0,a=b\\\frac{b}{a}-1,a>b\end{cases}
s=⎩
⎨
⎧1−ba,a<b0,a=bab−1,a>b
廓系数范围是(-1,1),其中值越接近1表示样本与自己所在的簇中的样本很相似,并且与其他簇中的样本不相似,当样本点与簇外的样本更相似的时候,轮廓系数就为负。当轮廓系数为0时,则代表两个簇中的样本相似度一致,两个簇本应该是一个簇。可以总结为轮廓系数越接近于1越好,负数则表示聚类效果非常差
其他常用方式:
| 标签未知时的评估指标 |
|---|
| 卡林斯基-哈拉巴斯指数 sklearn.metrics.calinski_harabaz_score (X, y_pred) |
| 戴维斯-布尔丁指数 sklearn.metrics.davies_bouldin_score (X, y_pred) |
| 权变矩阵 sklearn.metrics.cluster.contingency_matrix (X, y_pred) |
说明:卡林斯基-哈拉巴斯指数计算非常快速
from sklearn.metrics import calinski_harabasz_score
from time import time
t0 = time()
calinski_harabasz_score(X, y_pred)
time() - t0
t0 = time()
silhouette_score(X,y_pred)
time() - t0
import datetime
datetime.datetime.fromtimestamp(t0).strftime("%Y-%m-%d %H:%M:%S")
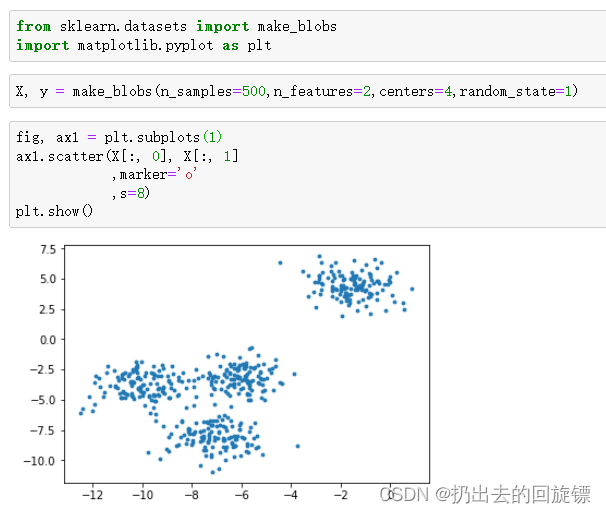
进行一次简单的聚类

步骤一:导入库和手动生成一份实验数据
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500,n_features=2,centers=4,random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8)
plt.show()
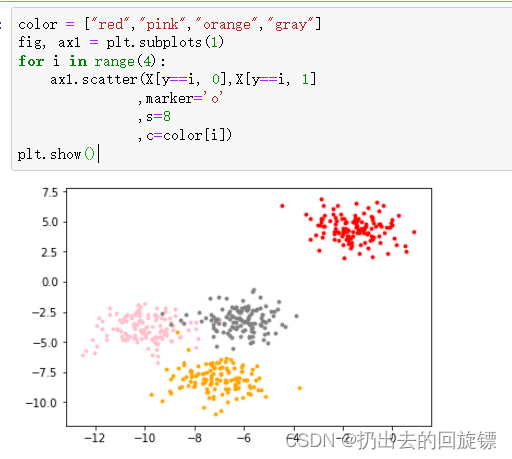
根据数据真实标签绘制散点图:
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0],X[y==i, 1]
,marker='o'
,s=8
,c=color[i])
plt.show()
步骤二:让簇数量为3进行KMeans聚类
导入所有数据进行聚类并检验效果
from sklearn.cluster import KMeans
n_clusters =3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
y_pred = cluster.labels_
pre = cluster.fit_predict(X)
pre == y_pred

在实际情况中遇到规模很大的数据时,可以划分部分进行拟合再进行预测,可以节省时间。但不可避免的精确度会有部分影响,但数据量很大时这个影响可以忽略。
cluster_smallsub = KMeans(n_clusters=n_clusters,random_state=0).fit(X[:200])
y_pred_ = cluster_smallsub.predict(X)
y_pred == y_pred_
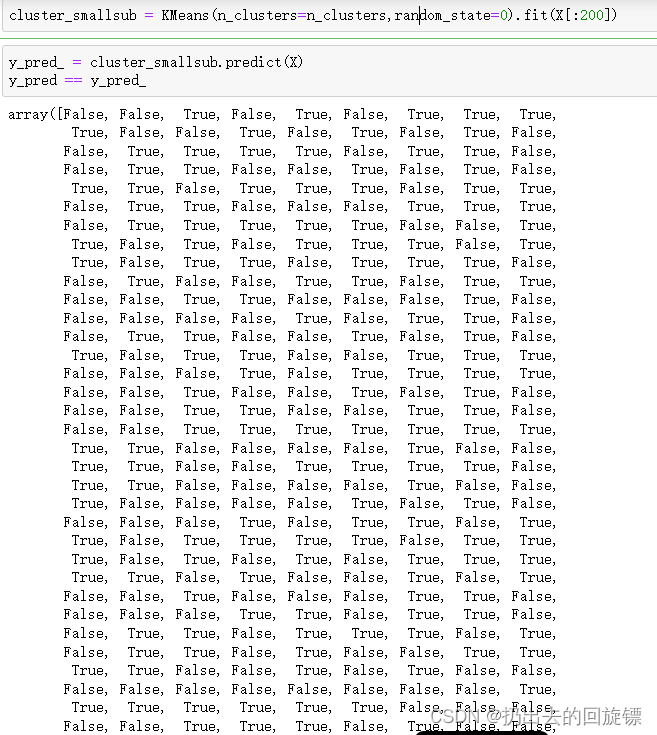
上面模拟切片,可以看到数据量小的时候对精确性的影响比较明显。
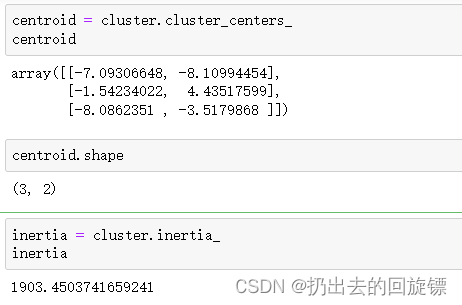
步骤三:查看质心和距离和
centroid = cluster.cluster_centers_
centroid
centroid.shape
inertia = cluster.inertia_
inertia
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred==i, 0],X[y_pred==i, 1]
,marker='o'
,s=8
,c=color[i])
ax1.scatter(centroid[:,0],centroid[:,1]
,marker="x"
,s=15
,c="black")
plt.show()
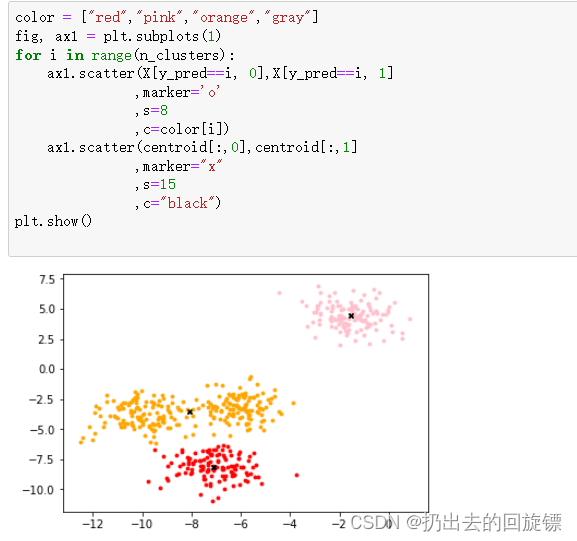
步骤四:查看簇增大的情况下对距离和的影响
n_clusters = 4
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
n_clusters = 5
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
n_clusters = 500
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
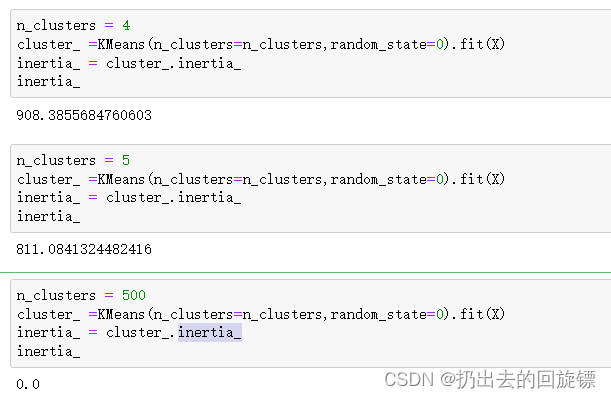
这就是需要保持簇不变情况最求inertia小的原因
步骤五:利用轮廓系数评价模型表现
from sklearn.metrics import silhouette_score
from sklearn.metrics import silhouette_samples
n_clusters = 3
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
silhouette_score(X,cluster_.labels_)
n_clusters = 4
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
silhouette_score(X,cluster_.labels_)
n_clusters = 5
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
silhouette_score(X,cluster_.labels_)
n_clusters = 6
cluster_ =KMeans(n_clusters=n_clusters,random_state=0).fit(X)
silhouette_score(X,cluster_.labels_)
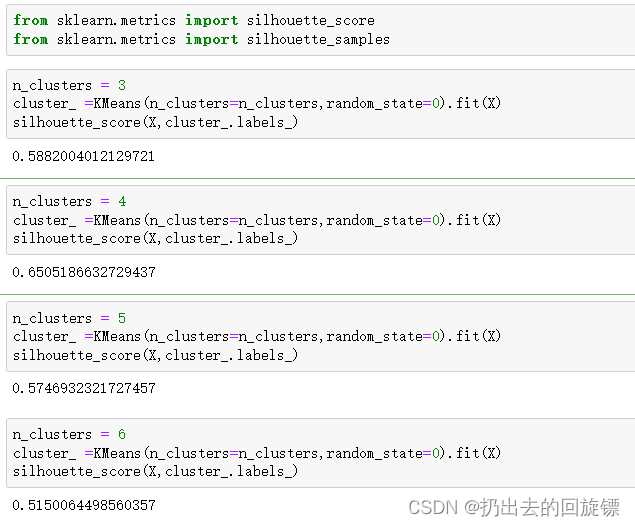
可以看到当簇数选择为4的时候,评分最高,符合实际情况。
3.实例:通过轮廓系数找最佳n_clusters
步骤一:导入库和数据
数据用的就是之前的自建数据集
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
步骤二:绘制n_clusters为4时的各簇中轮廓系数和的分类二维散点图
n_clusters =4
fig, (ax1,ax2) = plt.subplots(1,2)
fig.set_size_inches(18,7)
ax1.set_xlim([-0.1,1])
ax1.set_ylim([0,X.shape[0]+(n_clusters + 1)*10])#适当扩大y轴范围
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_cluster = ",n_clusters,
"The average silhouette_score is:",silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10 #簇间距离
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels ==i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
#让每簇的颜色相同
ax1.fill_betweenx(np.arange(y_lower,y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7)
ax1.text(-0.05
,y_lower+0.5*size_cluster_i
,str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#整体轮廓系数平均线
ax1.axvline(x=silhouette_avg,color="red",linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float)/n_clusters)
ax2.scatter(X[:,0],X[:,1]
,marker='o'
,s=8
,c=colors)
centers = clusterer.cluster_centers_
ax2.scatter(centers[:,0],centers[:,1],marker='x',c="red",alpha=1,s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
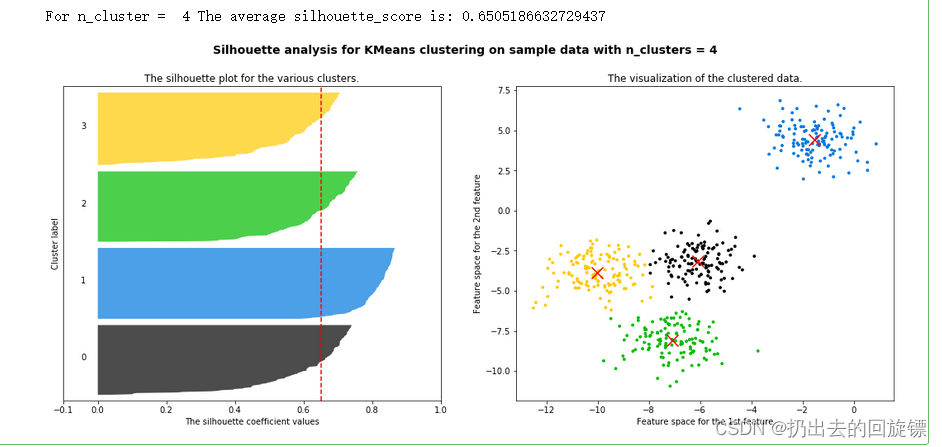
步骤三:包装循环绘制n_clusters为2-6时的图像
哈哈哈哈,其实是一样的
for n_clusters in [2,3,4,5,6]:
n_clusters = n_clusters
fig, (ax1,ax2) = plt.subplots(1,2)
fig.set_size_inches(18,7)
ax1.set_xlim([-0.1,1])
ax1.set_ylim([0,X.shape[0]+(n_clusters + 1)*10])#适当扩大y轴范围
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_cluster = ",n_clusters,
"The average silhouette_score is:",silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10 #簇间距离
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels ==i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
#让每簇的颜色相同
ax1.fill_betweenx(np.arange(y_lower,y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7)
ax1.text(-0.05
,y_lower+0.5*size_cluster_i
,str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#整体轮廓系数平均线
ax1.axvline(x=silhouette_avg,color="red",linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float)/n_clusters)
ax2.scatter(X[:,0],X[:,1]
,marker='o'
,s=8
,c=colors)
centers = clusterer.cluster_centers_
ax2.scatter(centers[:,0],centers[:,1],marker='x',c="red",alpha=1,s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
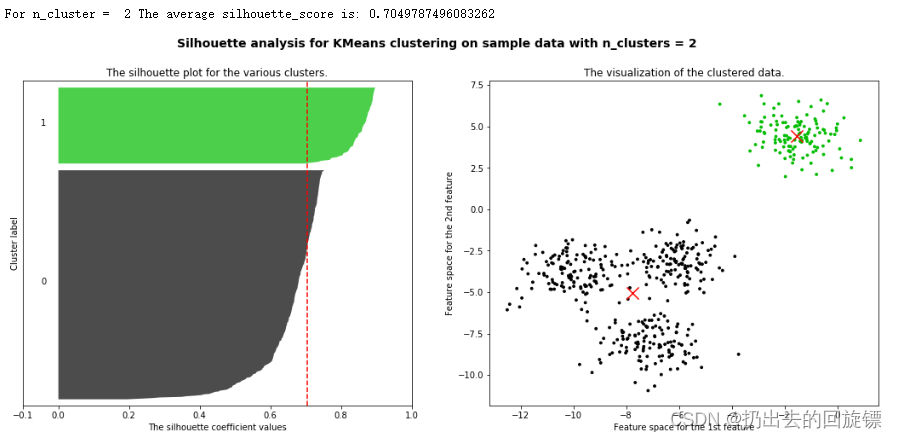
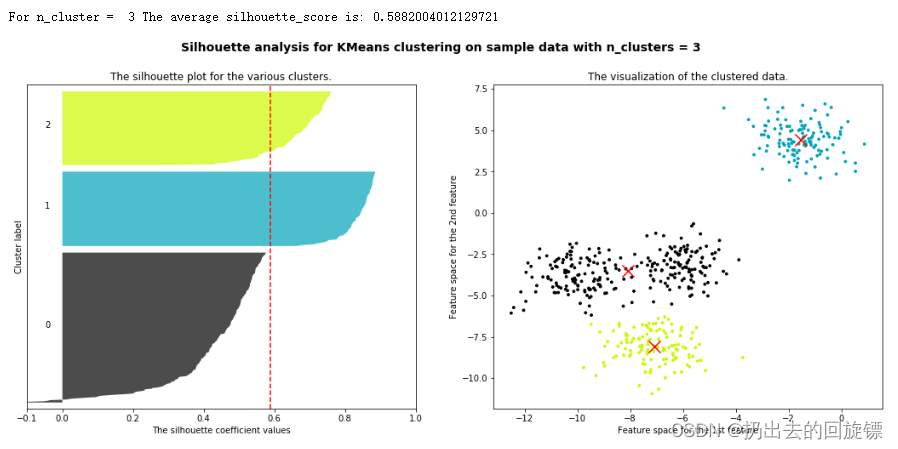
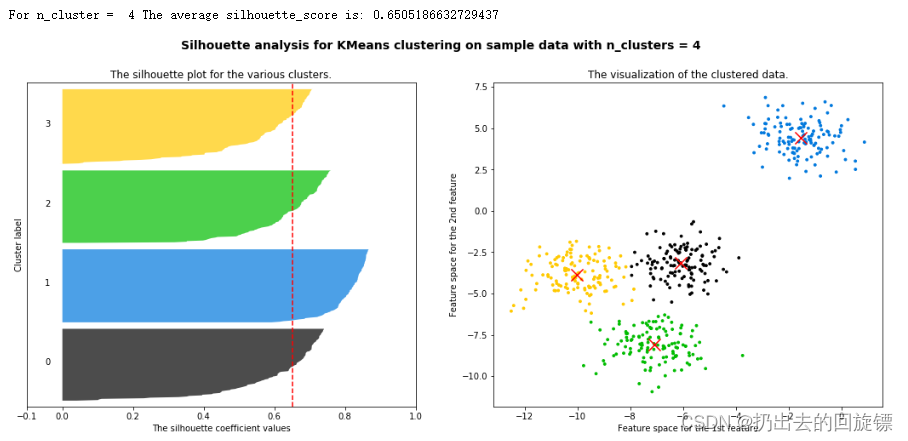
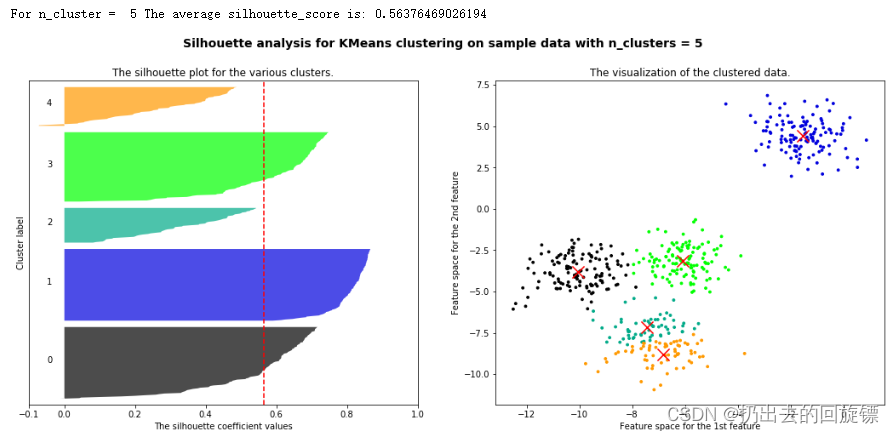
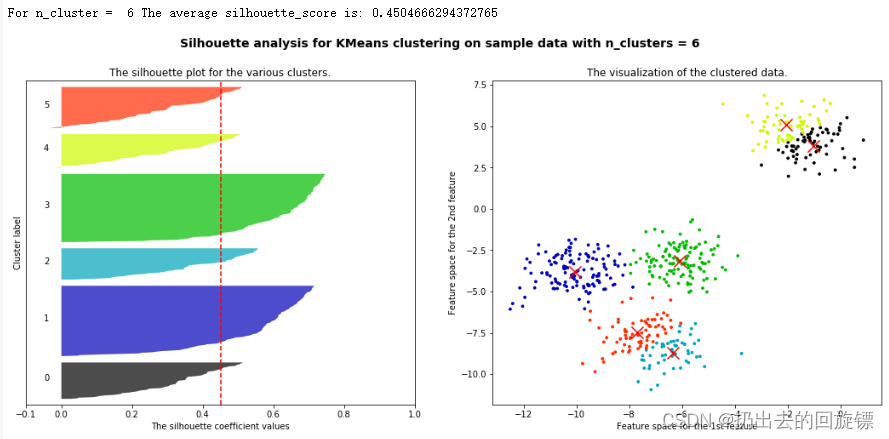
可以看到,n_clusters选择为2时,轮廓系数最高;n_clusters选择为4时,每个簇相对都比较平均;所以两者都能成为备选方案。现实问题中要根据实际问题进行选择,往往要考虑成本来进行选择。
其他重要参数
- init & random_state & n_init
KMeans开始环节就是放置初始质心,Inertia会依据此收敛到局部最小值,但能否收敛到真正的最小值很大程度上取决于质心的初始化。
1.init:可输入"k-means++“,“random"或者一个n维数组。默认"k-means++”。输入"k-means++”:一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心
2.random_state:控制每次质心随机初始化的随机数种子
3.n_init:整数,默认10,使用不同的质心随机初始化的种子来运行k-means算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出 - max_iter & tol
当n_clusters选择不符合数据的自然分布,或者为了业务需求必须要填入与数据分布不合的n_clusters,提前让迭代停下来可以提升模型的标签
1.max_iter:整数,默认300,单次运行的k-means算法的最大迭代次数
2.tol:浮点数,默认1e-4,两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下
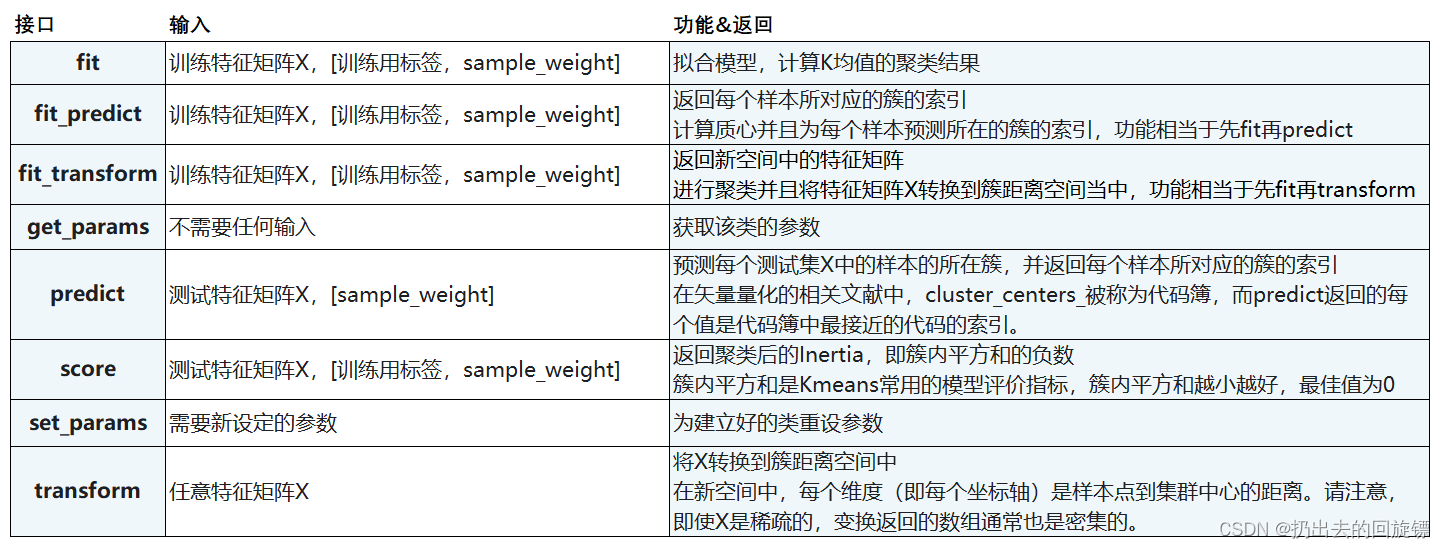
总表:

4.实例:KMeans的矢量量化应用
K-Means经常应用于非结构数据上的矢量量化。由于这类数据通常占用存储空间较大,导致运算缓慢;KMeans在同等样本量上压缩信息的大小,利用计算到的质心来代替原来的数据可以将数据上的信息量压缩到非常小,但又不损失太多信息。
步骤一:导入库和数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import pairwise_distances_argmin
from sklearn.datasets import load_sample_image
from sklearn.utils import shuffle
china = load_sample_image("china.jpg")
china.dtype
china.shape
china[0][0]
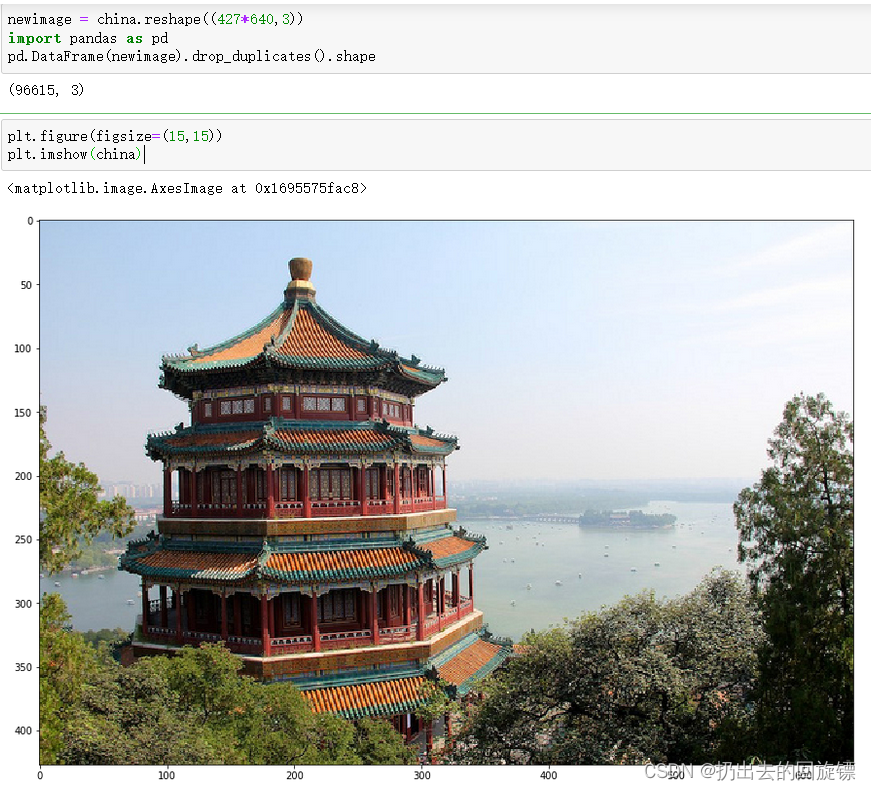
步骤二:查看原始图像以及其颜色数量
newimage = china.reshape((427*640,3))
import pandas as pd
pd.DataFrame(newimage).drop_duplicates().shape
plt.figure(figsize=(15,15))
plt.imshow(china)
步骤三:数据预处理
n_clusters = 64
china = np.array(china, dtype=np.float64) / china.max() #利于imshow,所以归一化
w, h , d = original_shape = tuple(china.shape)
assert d ==3
image_array = np.reshape(china,(w*h,d))
image_array.shape

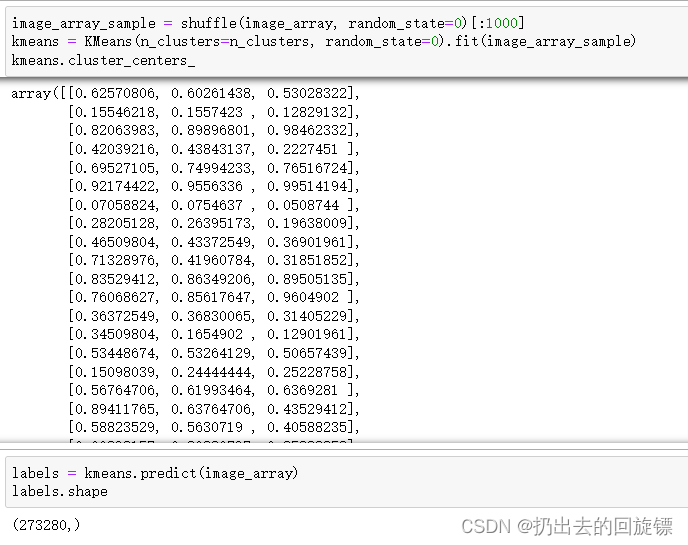
步骤四:分别对数据进行KMeans和随机的矢量量化
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
kmeans.cluster_centers_
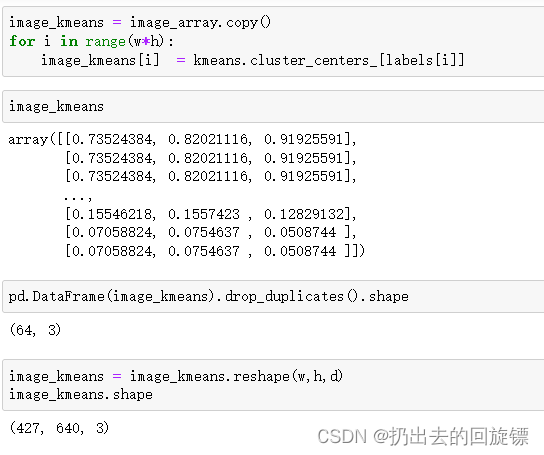
image_kmeans = image_array.copy()
for i in range(w*h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shape
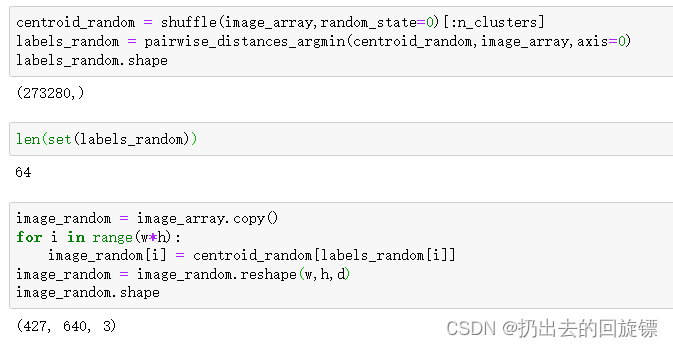
centroid_random = shuffle(image_array,random_state=0)[:n_clusters]
labels_random = pairwise_distances_argmin(centroid_random,image_array,axis=0)
labels_random.shape
image_random = image_array.copy()
for i in range(w*h):
image_random[i] = centroid_random[labels_random[i]]
image_random = image_random.reshape(w,h,d)
image_random.shape
步骤五:绘制图像并对比
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(image_kmeans)
plt.figure(figsize=(10,10))
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(image_random)
plt.show()



很明显,KMeans还原了大多数细节,效果很好。只是天空部分有分隔感。
附录

















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









