






word2vec常见模型有Continuous Bag-of-Words 模型(CBOW) 和 Skip-Gram 模型,我们在这只讨论skip-gram模型
Skip-Gram
简单说来,skip-gram模型是一个具有输入输出层和一层隐藏层的简单神经网络
Negative Sampling-负采样
如同上面所说的skip-gram模型,单词表有10000个单词,隐藏层有300个节点,那么一个很现实的问题是–参数过多:输入层和输出层的权重矩阵均将有10000×300个参数!对于使用梯度下降的神经网络来说,计算梯度将相当慢,而且需要比较大的数据量来保证不会过拟合。
所以Word2Vec的作者Tomas Mikolov在其第二篇论文中提出了三点改进:
1. 把一般词组和短语当做一个单词来对待
2. 把出现频繁的单词(比如‘the’‘an’‘a’)分离出来
3. 用‘负采样’优化模型
词组和短语
文章作者提出,比如New York Times(纽约时报)这个词组,就要比单个的单词更具有特别的意义。通过‘短语检测’,把两个单词组成一个常用词组,而生成三个词的常用词组,可以通过两词词组与另外一个单词的组合实现,以此类推。不过该方法仅限于词频相对较低的单词,我们不会去组合and the、this is这样的短语。
Chris McCormick在他的github上贴出了word2vec短语检测的c语言版本。
高频单词采样
还是以“The quick brown fox jumps over the lazy dog.”这句话为例,window的大小为2,蓝色的是输入的单词。
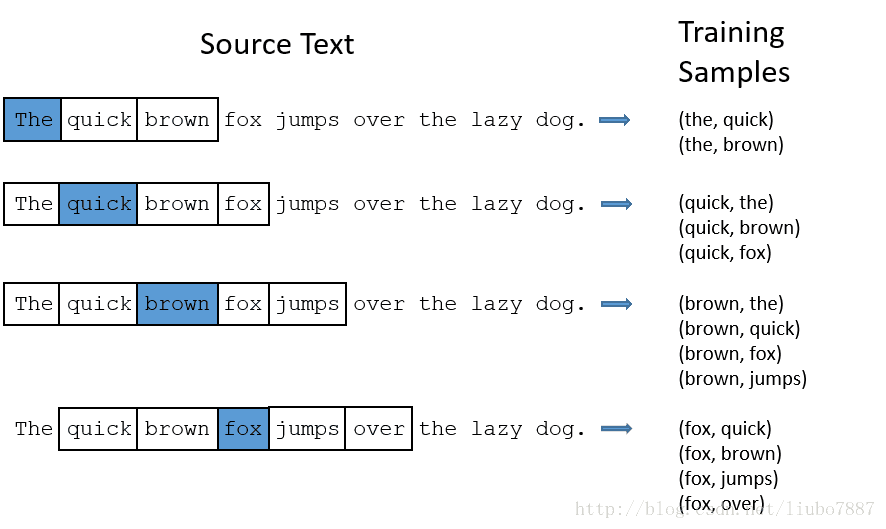
对于单词the,有两个问题:
1. 当查看单词对是,会发现the几乎出现在所有名词附近,但是并不会对名词的信息造成什么影响
2. 会有很多带有the的短语,这样我们的输入向量就多了很多
Word2Vec提供了‘subsampling’的方案来解决这两个问题,可以根据词频来删除训练数据中遇到的单词。比如:
把Window的大小设为10,然后把带有the的训练数据去掉
1. 用剩余词语作为训练数据,Window截取的数据就不再含the
2. 训练样本量也会少10个
这样其实就解决了上述出现的两个问题。有兴趣的可以去看Chris McCormick的word2vec源码关于采样率等是怎么实现的。
负采样
训练神经网络一般是输入一个样本数据,然后调整权重来使模型预测更准确。也就是说,每个样本都会影响所有的权重。对于具有数以亿计的skip-gram模型来说,效率很低。所以,负采样的思想就是:每给一个样本数据,只调整一小部分的权重值。
之前训练词对(fox,quick),输入fox,输出quick,即10000维的one-hot输出向量中,对应quick的是1,其余都是0。
而采用负采样,我们随机选择5-20个输出为0的位置(negative words),以及输出为1的位置(positive word,这里指quick)进行权重更新。对于一般规模的数据集,选择2-5个negative words就够了,这里我们选择5个negative words,也就是说总共更新6个位置的输出。
这样一来,对于之前提到的300×10000的输出矩阵,只需要更新300×6=1800个参数。相当于减少了99.4%的参数更新,效率提升可想而知。
上述提及的negative words 的选择根据是词频:在Chris McCormick的word2vec实现中,用‘unigram’分布,选择negative words,出现频率越高的词汇,越有可能被选中。














 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









