







核心目标
把词表vocabulary中每个词用固定维度的Embedding向量表示出来,且相似词的Embedding尽量相近。核心手段是利用训练预料中词语的上下文之间的关系,对构建的模型进行训练,从而使得模型预测出的相似词语的Embedding向量距离比较相近。
基本原理
训练语料的raw数据一般是从vocabulary中提取的sentence集合,集合的每一个item是一个sentence,每个sentence由若干个词组成。从训练语料的raw数据用于训练的数据获取方式分为两种,CBOW和SkipGram。CBOW是通过sentence的中心词的上下文来预测中心词,SkipGram的基本思想是通过中心词来预测上下文(具体计算过程可以参考这里),下图为诠释了两个获取训练数据的思想的区别。
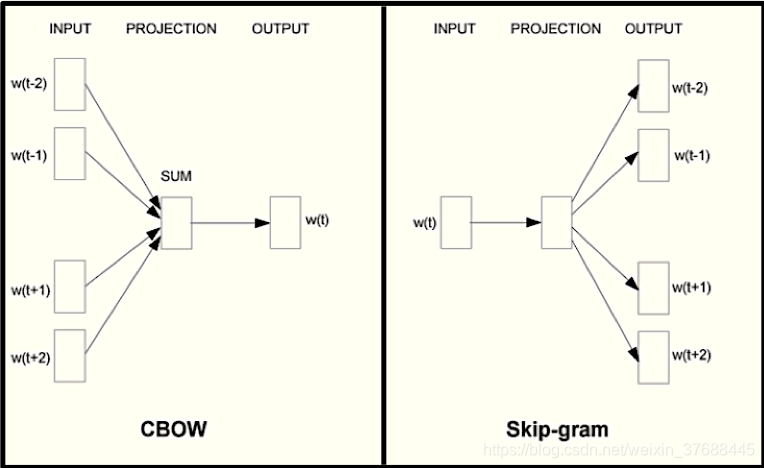
这里需要说明的是,SkipGram的效果要比CBOW好,原因如下所示:
CBOW:反向传播时,是用中心词更新周围词,相当于一个老师教一堆学生,那么每个学生接受的教育都是一样的,有可能学习的不好。
SkipGram:反向传播时,用周围词更新中心词,相当于一个一堆老师教一个学生,那么这个学生学习肯定比CBOW要好,因为这一堆老师会从各个方面教会他。
模型构建
为了方便公式推导查看示意图,这里借鉴了Word2Vec公式推导的画法,

损失函数
这里统一设输入侧权重层的标识符号为 v v v,输出侧权重层的标识符号为 u u u,单词的符号为 w w w,窗口滑动过程中迭代变量为 t t t。
原始损失函数
SkipGram
SkipGram的中心思想为通过中心词
w
t
w^t
wt预测周围词
w
t
+
j
w^{t+j}
wt+j的联合概率值最大,即
∏
t
=
1
T
∏
−
m
≤
j
≤
m
j
≠
0
P
(
w
t
+
j
∣
w
t
)
\prod_{t=1}^T \prod_{-m\leq j \leq m \ j\neq 0}P(w^{t+j}|w^t)
t=1∏T−m≤j≤m j=0∏P(wt+j∣wt)
其对应的损失函数如下,目标是令损失函数最小。
−
1
T
∑
t
=
1
T
∑
−
m
≤
j
≤
m
j
≠
0
l
o
g
P
(
w
t
+
j
∣
w
t
)
-\frac{1}{T}\sum_{t=1}^T \sum_{-m\leq j \leq m \ j\neq 0}log P(w^{t+j}|w^t)
−T1t=1∑T−m≤j≤m j=0∑logP(wt+j∣wt)
上述公式中的
P
(
w
t
+
j
∣
w
t
)
P(w^{t+j}|w^t)
P(wt+j∣wt)通过
P
(
w
0
∣
w
c
)
P(w_{0}|w_c)
P(w0∣wc)来代替,目的是方便书写,
w
c
w^c
wc代表的是中心词,
w
0
w^0
w0代表的是周围词。根据<模型构建>一节内容,可以得出如下公式,
P
(
w
0
∣
w
c
)
=
e
x
p
(
u
0
T
v
c
)
∑
i
∈
v
e
x
p
(
u
i
T
v
c
)
P(w_{0}|w_c)=\frac{exp(u^T_0v_c)}{\sum_{i\in v} exp(u^T_iv_c)}
P(w0∣wc)=∑i∈vexp(uiTvc)exp(u0Tvc)
对于
v
c
v_c
vc,其导数为
∂
l
o
g
P
(
w
0
∣
w
c
)
∂
v
c
=
u
0
−
∑
j
∈
v
e
x
p
(
u
j
T
v
c
)
∑
i
∈
v
e
x
p
(
u
i
T
v
c
)
u
j
=
u
0
−
∑
j
∈
v
P
(
w
j
∣
w
c
)
u
j
\frac{\partial logP(w_0|w_c)}{\partial v_c}=u_0-\sum_{j\in v}\frac{exp(u^T_jv_c)}{\sum_{i\in v}exp(u^T_iv_c)u_j}=u_0-\sum_{j\in v}P(w_j|w_c)u_j
∂vc∂logP(w0∣wc)=u0−j∈v∑∑i∈vexp(uiTvc)ujexp(ujTvc)=u0−j∈v∑P(wj∣wc)uj
可以看出每计算一次 v c v_c vc的梯度,都需要遍历整个词表来计算累加值。
CBOW
CBOW的核心思想为通过周围词
[
w
t
−
m
,
.
.
.
,
w
t
−
1
,
w
t
+
1
,
.
.
.
,
w
t
+
m
]
[w^{t-m}, ..., w^{t-1}, w^{t+1}, ..., w^{t+m}]
[wt−m,...,wt−1,wt+1,...,wt+m]预测中心词
w
t
w^t
wt,因而其目标为如下的联合概率值最大,即
∏
t
=
1
T
P
(
w
t
∣
w
t
−
m
,
.
.
.
,
w
t
−
1
,
w
t
+
1
,
.
.
.
,
w
t
+
m
)
\prod_{t=1}^TP(w^t|w^{t-m},...,w^{t-1}, w^{t+1}, ..., w^{t+m})
t=1∏TP(wt∣wt−m,...,wt−1,wt+1,...,wt+m)
损失函数为如下公式,
−
∑
t
=
1
T
P
(
w
t
∣
w
t
−
m
,
.
.
.
,
w
t
−
1
,
w
t
+
1
,
.
.
.
,
w
t
+
m
)
-\sum_{t=1}^TP(w^t|w^{t-m},...,w^{t-1}, w^{t+1}, ..., w^{t+m})
−t=1∑TP(wt∣wt−m,...,wt−1,wt+1,...,wt+m)
上述公式中的
w
t
+
j
w^{t+j}
wt+j用
w
o
x
w_{o_x}
wox来代替,
w
t
w^t
wt用
w
c
w_c
wc来代替,目的为了方便书写,上述损失函数中
P
(
w
t
∣
w
t
−
m
,
.
.
.
,
w
t
−
1
,
w
t
+
1
,
.
.
.
,
w
t
+
m
)
P(w^t|w^{t-m},...,w^{t-1}, w^{t+1}, ..., w^{t+m})
P(wt∣wt−m,...,wt−1,wt+1,...,wt+m)的具体表达形式如下:
P
(
w
c
∣
w
o
1
,
.
.
.
,
w
o
2
m
)
=
e
x
p
(
u
c
T
(
v
o
1
+
.
.
.
+
v
o
2
m
)
/
2
m
)
∑
i
∈
v
e
x
p
(
u
i
T
(
v
o
1
+
.
.
.
+
v
o
2
m
)
/
2
m
)
P(w_c|w_{o_1},...,w_{o_{2m}})=\frac{exp(u^T_c(v_{o_1}+...+v_{o_{2m}})/2m)}{\sum_{i\in v}exp(u^T_i(v_{o_1}+...+v_{o_{2m}})/2m)}
P(wc∣wo1,...,wo2m)=∑i∈vexp(uiT(vo1+...+vo2m)/2m)exp(ucT(vo1+...+vo2m)/2m)
对于
v
o
1
v_{o_1}
vo1,其导数为
∂
l
o
g
P
(
w
c
∣
w
o
1
,
.
.
.
,
w
o
2
m
)
∂
v
o
1
=
1
2
m
(
u
c
−
∑
j
∈
v
e
x
p
(
u
j
T
(
v
o
1
+
.
.
.
+
v
o
2
m
)
/
2
m
)
∑
i
∈
v
e
x
p
(
u
i
T
(
v
o
1
+
.
.
.
+
v
o
2
m
)
/
2
m
)
u
j
)
=
1
2
m
(
u
c
−
∑
j
∈
v
P
(
w
j
∣
w
o
1
,
.
.
.
,
w
o
2
m
)
u
j
)
\frac{\partial log P(w_c|w_{o_1},...,w_{o_{2m}})}{\partial v_{o_1}}= \frac{1}{2m}(u_c-\sum_{j\in v}\frac{exp(u^T_j(v_{o_1}+...+v_{o_{2m}})/2m)}{\sum_{i\in v}exp(u^T_i(v_{o_1}+...+v_{o_{2m}})/2m)}u_j)=\frac{1}{2m}(u_c-\sum_{j\in v}P(w_j|w_{o_1},...,w_{o_{2m}})u_j)
∂vo1∂logP(wc∣wo1,...,wo2m)=2m1(uc−j∈v∑∑i∈vexp(uiT(vo1+...+vo2m)/2m)exp(ujT(vo1+...+vo2m)/2m)uj)=2m1(uc−j∈v∑P(wj∣wo1,...,wo2m)uj)
而对于CBOW,计算损失函数依然免除不了每迭代一步就要计算整个词表的命运,因而两种算法的原始损失函数计算过程都比较耗时。
NCE 损失
核心思想
word2vec中负样本的意义在于计算SoftMax时分母的数量,具体而言,计算SoftMax损失函数核心思想是利用一个正样本和其他所有的负样本来对模型做训练,NCE损失计算的基本思想为提取一个正样本,且按照某种分布P提取k个负样本(而不是全部的负样本),针对这k+1个样本进行梯度的学习,这k+1个样本的类别数即为这一次采样过后SoftMax计算的类别数,这样能节省很多计算量。
具体而言,以SkipGram为例,用中心词
w
c
w_c
wc预测周围词
w
0
w_0
w0(在滑动窗口中出现),且从分布
P
(
w
)
P(w)
P(w)中独立采集没有进入滑动窗口的K个词
w
k
∣
k
=
1
K
w_k|_{k=1}^K
wk∣k=1K,让这k+1词采样的联合分布概率最大,公式如下,
l
o
g
P
(
w
0
∣
w
c
)
=
l
o
g
[
P
(
D
=
1
∣
w
0
,
w
c
)
∏
k
=
1
K
P
(
D
=
0
∣
w
k
,
w
c
)
]
=
l
o
g
P
(
D
=
1
∣
w
0
,
w
c
)
+
∑
k
=
1
K
l
o
g
P
(
D
=
0
∣
w
k
,
w
c
)
log P(w_0|w_c)=log[P(D=1|w_0,w_c)\prod_{k=1}^KP(D=0|w_k,w_c)]=logP(D=1|w_0,w_c)+\sum_{k=1}^K log P(D=0|w_k,w_c)
logP(w0∣wc)=log[P(D=1∣w0,wc)k=1∏KP(D=0∣wk,wc)]=logP(D=1∣w0,wc)+k=1∑KlogP(D=0∣wk,wc)
上述公式中 P ( D = 1 ∣ w 0 , w c ) = σ ( u 0 T v c ) P(D=1|w_0,w_c)=\sigma(u^T_0v_c) P(D=1∣w0,wc)=σ(u0Tvc), P ( D = 0 ∣ w k , w c ) = 1 − σ ( u k T v c ) = σ ( − u k T v c ) P(D=0|w_k,w_c)=1-\sigma(u^T_kv_c)=\sigma(-u^T_kv_c) P(D=0∣wk,wc)=1−σ(ukTvc)=σ(−ukTvc),其中 σ \sigma σ代表sigmoid函数。
实现手段
实际使用中,分布P即为整个语料的词频分布。gensim库具体实现负采样时的逻辑如下:
如果词汇表的大小为V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词
w
w
w的线段长度由下式决定:
l
e
n
(
w
)
=
c
o
u
n
t
(
w
)
3
/
4
∑
u
∈
v
o
c
a
b
c
o
u
n
t
(
u
)
3
/
4
len(w)=\frac{count(w)^{3/4}}{\sum_{u\in vocab}count(u)^{3/4}}
len(w)=∑u∈vocabcount(u)3/4count(w)3/4
在采样前,我们将这段长度为1的线段划分成M等份,这里M >> V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。具体代码如下所示:
# 生成累积表
def make_cum_table(self, wv, domain=2**31 - 1):
"""Create a cumulative-distribution table using stored vocabulary word counts for
drawing random words in the negative-sampling training routines.
To draw a word index, choose a random integer up to the maximum value in the table (cum_table[-1]),
then finding that integer's sorted insertion point (as if by `bisect_left` or `ndarray.searchsorted()`).
That insertion point is the drawn index, coming up in proportion equal to the increment at that slot.
Called internally from :meth:`~gensim.models.word2vec.Word2VecVocab.build_vocab`.
"""
vocab_size = len(wv.index2word)
self.cum_table = zeros(vocab_size, dtype=uint32)
# compute sum of all power (Z in paper)
train_words_pow = 0.0
for word_index in range(vocab_size):
train_words_pow += wv.vocab[wv.index2word[word_index]].count**self.ns_exponent
cumulative = 0.0
for word_index in range(vocab_size):
cumulative += wv.vocab[wv.index2word[word_index]].count**self.ns_exponent
# 实际记录的是单词对应线段从左到右数的index,高频词汇比其左侧的词对应的index大很多
self.cum_table[word_index] = round(cumulative / train_words_pow * domain)
if len(self.cum_table) > 0:
assert self.cum_table[-1] == domai
# 从累积表中抽样
word_indices = [word.index]
while len(word_indices) < model.negative + 1:
# 生成一个随机数,找到其应该插入的位置,这样能够实现高频词汇被抽中的机会大很多
# 因为该词对应的index比其左侧词对应的index大很多
w = model.cum_table.searchsorted(model.random.randint(model.cum_table[-1]))
if w != word.index:
word_indices.append(w)
NCE 损失 vs sampled_softmax 损失
与NCE 损失比较类似的是sampled_softmax,两个损失的区别在于:NCE建立了
K
+
1
K+1
K+1个二分类器来构建损失函数,而sampled_softmax只建立一个
K
+
1
K+1
K+1维多分类器,sampled_softmax对应损失函数公式如下:
l
o
s
s
=
−
l
o
g
e
x
p
(
u
0
T
v
c
)
e
x
p
(
u
0
T
v
c
)
+
∑
k
=
1
K
e
x
p
(
u
k
T
v
c
)
loss = - log\frac{exp(u_0^Tv_c)}{exp(u_0^Tv_c)+\sum_{k=1}^{K}exp(u_k^Tv_c)}
loss=−logexp(u0Tvc)+∑k=1Kexp(ukTvc)exp(u0Tvc)
NCE损失更注重每个样本的分类准确性;sampled_softmax损失更侧重整体概率分布的准确性,其更具有大局观,因而一般情况下,sampled_softmax损失的效果要好一些。
层次SoftMax
层次SoftMax的做法比NCE损失更为简单,即直接改变SoftMax的计算,如下会对层次SoftMax进行讲解。
构造霍夫曼树
首先根据单词出现的词频构建哈夫曼树,树的每个叶子节点代表的是词典中的一个单词。算法的伪代码如下所示:
while (单词列表长度>1) {
从单词列表中挑选出出现频率最小的两个单词 ;
创建一个新的中间节点,其左右节点分别是之前的两个单词节点 ;
从单词列表中删除那两个单词节点并插入新的中间节点 ;
}
构造霍夫曼树的目的在于从根节点到高频词所走的路径最少。
训练模型
构造完霍夫曼树后,从根节点到每一个叶子节点的路径已经知晓,如下图所示:

这里依然以SkipGram为例,层次SoftMax的目标在于将SoftMax替换为路径乘积。树的每一个非叶子节点都是一个二分类器,预测的是结果落入该节点的左子树的概率,公式如下所示,其中
L
(
w
)
L(w)
L(w)为由这个二叉树的根到这个w词的路径上的节点数,例如
L
(
w
3
)
L(w_3)
L(w3)=4,
P
(
w
∣
w
i
)
=
∏
j
=
1
L
(
w
)
−
1
σ
(
[
n
(
w
,
j
+
1
)
=
l
e
f
t
c
h
i
l
d
(
n
(
w
,
j
)
)
]
⋅
u
n
(
w
,
j
)
T
v
i
)
P(w|w_i)=\prod_{j=1}^{L(w)-1}\sigma([n(w,j+1)=leftchild(n(w,j))]\cdot u_{n(w,j)}^Tv_i)
P(w∣wi)=j=1∏L(w)−1σ([n(w,j+1)=leftchild(n(w,j))]⋅un(w,j)Tvi)
举例说明,通过中心词
w
i
w_i
wi预测周围词
w
3
w_3
w3,这时的概率为
P
(
w
3
∣
w
i
)
=
σ
(
u
n
(
w
3
,
1
)
T
v
i
)
⋅
σ
(
−
u
n
(
w
3
,
2
)
T
v
i
)
⋅
σ
(
u
n
(
w
3
,
3
)
T
v
i
)
P(w_3|w_i)=\sigma(u^T_{n(w_3,1)}v_i)\cdot \sigma(-u^T_{n(w_3,2)}v_i)\cdot \sigma(u^T_{n(w_3,3)}v_i)
P(w3∣wi)=σ(un(w3,1)Tvi)⋅σ(−un(w3,2)Tvi)⋅σ(un(w3,3)Tvi)
反向传播时,只需要计算3个节点对应的梯度,可以看出,反向传播的时间复杂度从 O ( N ) O(N) O(N)变为 O ( l o g N ) O(logN) O(logN)。
embedding vs one-hot
word2vec的核心思想为训练得到每一个word的embedding稠密表示,且训练的核心思想为有相似上下文的单词embedding足够相似,这一核心思想决定了embedding的one-hot的核心区别:
- one-hot虽然可读性较强,但是无法表示单词之间的相似性,即使利用两个单词的共现关系来衡量两个单词的相似性,如果两个单词在语料中没有出现过,则无法判断出这两个单词的相似,但embedding表示就能够很好地表述。
- one-hot没有利用上下文信息,信息不足,而且无法进行embedding之间的推衍,比如man-woman = king - queen。
- one-hot向量比较长,embedding比较短,从而能够节省计算量和存储量。
word2vec总结
通过训练模型得到每个词的词向量,使语义相关的词向量距离足够相近。通常有两种训练方式:skip-gram和cbow。以skip-gram为例,输入当前词的one-hot表示,输出上下文的预测。具体来说,模型分为输入层、隐藏层和输出层三层(核心环节为隐藏层),从输入层到隐藏层核心操作为找到当前词的embedding向量,从隐藏层到输出层通过矩阵相乘会得到整个词表每个词作为上下文的概率,之后与one-hot表示上下文label进行交叉熵损失函数学习,迭代一些step后得到训练好的模型。
word2vec本身算不上深度学习模型,只因为它不够深,而且它并没有针对输入提取更加高阶的特征。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









