







 本文介绍了Facebook在ICLR会议上提出的Recurrent Entity Network,该模型利用动态记忆网络实时更新世界状态,适用于机器阅读理解和问答系统。模型包括输入模块、动态记忆模块和输出模块,通过TensorFlow实现。文章通过实例解释模型工作原理,并讨论了模型中几个关键问题,如记忆单元的数量、不同记忆间的关系以及记忆的遗忘机制。
本文介绍了Facebook在ICLR会议上提出的Recurrent Entity Network,该模型利用动态记忆网络实时更新世界状态,适用于机器阅读理解和问答系统。模型包括输入模块、动态记忆模块和输出模块,通过TensorFlow实现。文章通过实例解释模型工作原理,并讨论了模型中几个关键问题,如记忆单元的数量、不同记忆间的关系以及记忆的遗忘机制。
这篇论文是facebook在前段时间ICLR会议上发表的论文,提出了一种Recurrent Entity Network的模型用来对world state进行建模,实时的根据模型的输入对记忆单元进行更新,从而得到对world的一个即时的认识。该模型可以用于机器阅读理解、QA等领域。下面对论文所提出的模型架构进行一个简单的概述:
1,论文提出了一种新的动态记忆网络,其使用固定长度的记忆单元来存储世界上的实体,每个记忆单元对应一个实体,主要存储该实体相关的属性(譬如一个人拿了什么东西,在哪里,跟谁等等信息),且该记忆会随着输入内容实时更新。
2,多个记忆单元(memory slot)之间相互独立,由(key,value)组成。key用来标识实体Entity,value用来存储实体相关的属性,也就是记忆。使用Gated RNN来实现该记忆单元的功能,也就是说每个memory slot都是一个单独的一层RNN,对于一个输入st会同时计算m个memory slot,其间相互独立。但是网络的参数相同。可以爸这多个memory slot类比成多层RNN,但是每一层的输入不是上一层的输出或者记忆,而是第一层的输入st。
其架构图如下图所示,方块代表memory cell,一层代表一个recurrent RNN,也就是一个memory slot,用来存储一个实体及其相关属性,共m层,且相互独立,但是每层内、各层间各个方块之间的参数共享,保持一致。key对应于w参数,每一层的w不一样,用来标识不同的实体。(w,h)就是记忆单元。我们可以看到:

我们先用一个简单的例子来通俗的介绍一下模型的工作原理。例如我们模型输入的是下面三句话,前面两句是模型要阅读的材料,最后一句话是问题。我们的模型目的就是根据材料和问题得到答案。
Mary picked up the ball.
Mary went to the garden.
Where is the ball?当模型读入第一句话时,模型会学习到mary和ball两个实体,假设第一个memory slot学习Mary,第二个学习ball,也就是说key w1会学习输入中的mary实体,而key w2会学习到ball实体。这也就是每个memory slot的key的意义,用来标识输入中的实体。那么记忆h是什么呢?第一个会学到mary拿着球,第二个会学到球被mary拿着。接下来读入第二句话,首先第一个memory slot会检测到mary,然后将其记忆更新为mary拿着球,在花园中;第二个虽然并未检测到ball这个实体,但是其memory中有关于mary的记忆,所以也会做出相应的更新(这部分可以参考下面的动态记忆模块),将记忆更新为球被mary拿着,在花园中。同样第三个memory slot会学习到花园这个实体,并将其记忆更新为mary和球都在其中。当读入问题的时候,会先学习到ball这个实体,然后将其跟m个memory slot做Attention,也就是求问题跟m个slot之间的关系,显然第二个实体的重要性更大。然后将m个slot的记忆进行加权得到我们的输出答案。这就是模型的工作流程。主要体现在动态记忆 实时更新 Tracking the World State
下面分别介绍一下模型的三个主要组件,输入模块、动态记忆模块、输出模块。
输入模块
我们的输入是batch_size*story_len*sent_len*embed_size的四维tensor story故事或者去掉story_len的query问题。那么输入层的主要作用是将sent_len这个维度去掉,也就是将句子中的所有单词进行加权得到一个句子的representation 向量。如下:

其中f是一个模型需要学习的变量,其将句子中的每个单词进行加权的到句子的向量表示,也就是Gated RNN记忆单元的输入。f用来学习句子的位置信息,我感觉这里最终f将学习到句子的主谓宾这种位置关系,因为模型需要学习出输入中的实体信息(个人理解)。反正最终通过f参数对句子当中的所有单词进行加权求和我们就能得到句子的向量表示。
动态记忆模块
同样是上面的框架图,这里我们进行详细的介绍:
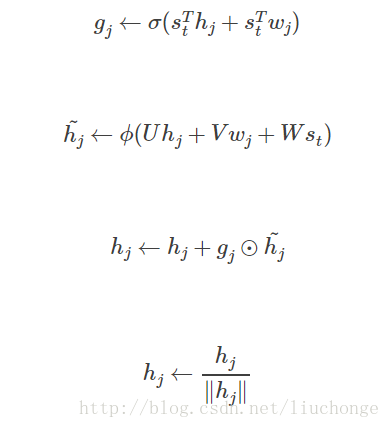
对于每个memory slot j 而言,首先第一个公式,分别使用前一时刻的记忆 h 和该记忆单元的key w与输入s相乘然后经过激活函数得到一个门控单元g,这里w和h分别用于提取s中与本slot相关的实体信息和s与本slot实体属性相关的信息。对应上面那个例子,当输入第二句话时,w与s相乘,因为s中没有ball相关的信息,所以得0,但是h与s相乘时,因为h中有mary相关的信息,所以h与s相乘不等于零,最终仍然会对记忆进行更新。这里门控的概念大家可以仔细看一下架构图,四个单元每个单元门控的符号的方向是不一样的,也就暗示了g的取值会导致h的更新幅度。
第二个公式就是传统的RNN单元,用于计算当输入s时,需要更新的内容,需要注意的是UVW这三个参数在所有的记忆单元当中都是共享的。第三个公式则是根据门控单元g和h来对记忆进行更新,将新的信息写入记忆之中(第二句改成mary拿着球到了花园)。第四个公式是对新的记忆进行归一化,论文中提到该归一化可以达到忘记门的作用(比如说第三句话是mary went bedroom,那么记忆就会忘记mary在花园这个信息),但是这里我不是很明白为什么对记忆进行归一化操作的时候可以实现忘记的功能。这里按照论文中给出的解释梳理一下,如下图,原本的记忆是归一化的在单位域内,然后经过门控之后的新的记忆是上面那个向量,所以二者的和(公式3)是一个比较长的向量,然后将其归一化到单位域内,可以理解为其幅度变小了。接下来有两种理解方式:
- 数值被归一化,则表明其可以编码的信息量变小。
- 幅度变小后,在后面的更新过程中与别的变量相乘或者别的什么操作时,对该变量的影响变小,间接起到忘记的效果
但是这两种想法都是我自己强行靠结论得到的,还希望如果有谁明白其中的数学道理可以解释一下。

输出模块
经过动态记忆模块,我们已经把输入转化为memory存储在各个memory slot里面,那么接下来的工作就是根据Query来产生该问题的答案。第一步要将Query编码成一个向量,使用与输入模块相同的操作去编码问题中的实体(例如上栗中的ball),然后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









