







为了理解Spark中一些术语,仔细阅读了官方文档以及查阅了相关资料,现记录如下:
1.Application: 在spark上构建的应用程序,由driver和executors构成;
2.work node:工作节点,在集群中能够运行app的任何节点。
3.driver:运行main函数并创建SparkContext的进程,在Client模式中,在集群外开启driver;cluster中,在集群中随机选择一台机器启动。
4.executor:在一个工作节点上为app开启的进程,每个app都有自己的executor,用于跑tasks和保存数据。
5.tasks:发送到其中一个executor的一个单元工作,rdd一般带有分区,每个分区在一个executor上执行的任务就是一个task。
6.job:由多个task组成的并行计算,响应action(如save,collect等),一个action算子可作为一个job。
7.stage:每个job分为更小并相互依赖的task集合,这里依赖分为宽依赖和窄依赖,而他们的边界就是stage的划分点。通过下图会有一个比较好的理解:
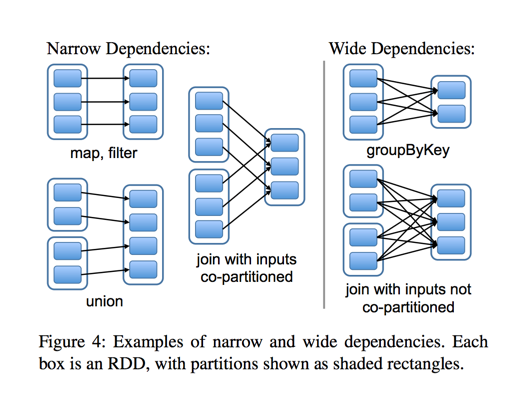
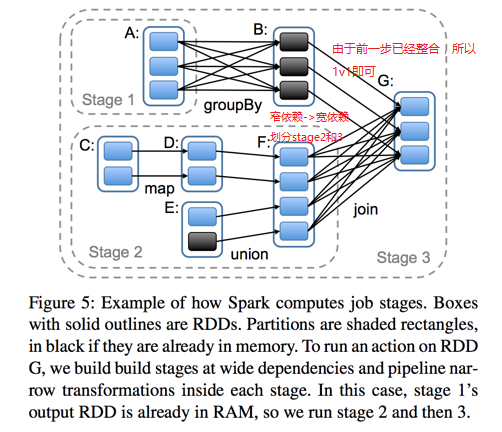
说明:上一步从B---->G由于从A---->B已经进行了groupBy,所以不需要像从F---->G那样。















 1857
1857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









