









在业务开发中,大量场景需要唯一ID来进行标识:用户需要唯一身份标识、商品需要唯一标识、消息需要唯一标识、事件需要唯一标识等,都需要全局唯一ID,尤其是复杂的分布式业务场景中全局唯一ID更为重要。
那么,分布式唯一ID有哪些特性或要求呢?
① 唯一性:生成的ID全局唯一,在特定范围内冲突概率极小。
② 有序性:生成的ID按某种规则有序,便于数据库插入及排序。
③ 可用性:可保证高并发下的可用性, 确保任何时候都能正确的生成ID。
④ 自主性:分布式环境下不依赖中心认证即可自行生成ID。
⑤ 安全性:不暴露系统和业务的信息, 如:订单数,用户数等。
分布式唯一ID有哪些生成方法呢?
总的来说,大概有三大类方法,分别是:数据库自增ID、UUID生成、snowflake雪花算法。
下面分别说下这三大类及其优化方案:
一、数据库自增ID
核心思想:使用数据库的id自增策略(如: Mysql的auto_increment)。
优点:
① 简单,天然有序。
缺点:
① 并发性不好。
② 数据库写压力大。
③ 数据库故障后不可使用。
④ 存在数量泄露风险。
针对以上缺点,有以下几种优化方案:
1. 数据库水平拆分,设置不同的初始值和相同的自增步长
核心思想:将数据库进行水平拆分,每个数据库设置不同的初始值和相同的自增步长。
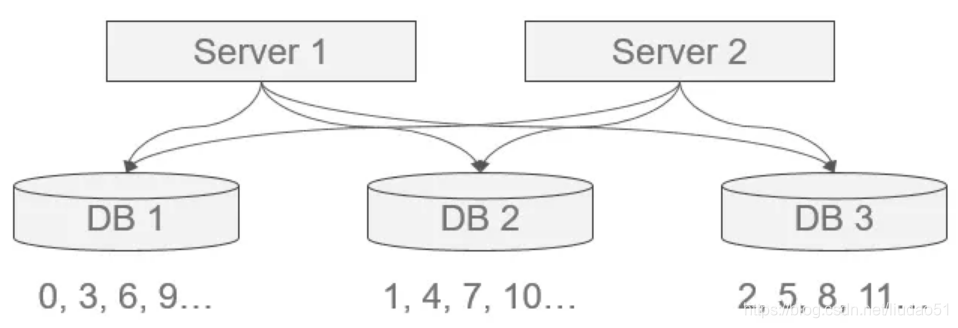
如图所示,可保证每台数据库生成的ID是不冲突的,但这种固定步长的方式也会带来扩容的问题,很容易想到当扩容时会出现无ID初始值可分的窘境,解决方案有:
① 根据扩容考虑决定步长。
② 增加其他位标记区分扩容。
这其实都是在需求与方案间的权衡,根据需求来选择最适合的方式。
2. 批量缓存自增ID
核心思想:如果使用单台机器做ID生成,可以避免固定步长带来的扩容问题(方案1的缺点)。
具体做法是:每次批量生成一批ID给不同的机器去慢慢消费,这样数据库的压力也会减小到N分之一,且故障后可坚持一段时间。
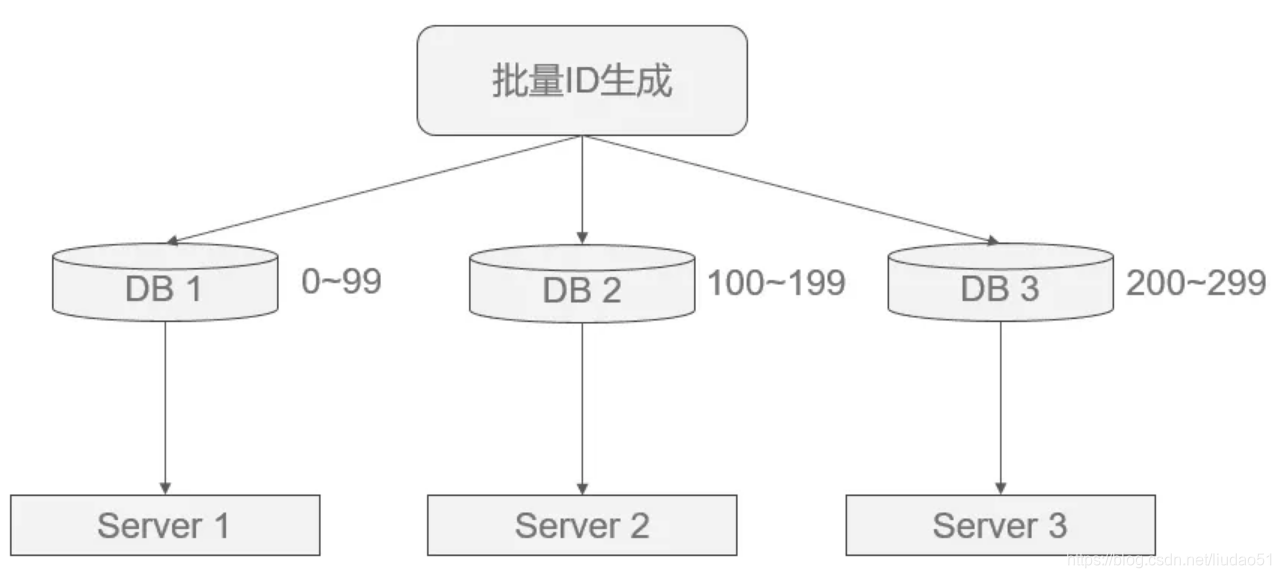
如图所示,但这种做法的缺点是服务器重启、单点故障会造成ID不连续。
还是那句话,没有最好的方案,只有最适合的方案。
3. Redis生成ID
核心思想:Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:
① 不依赖于数据库,灵活方便,且性能优于数据库。
② 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
① 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
② 需要编码和配置的工作量比较大。
优化方案:
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量,并利用上面的方案(①数据库水平拆分,设置不同的初始值和相同的步长; ②批量缓存自增ID)来配置集群。
PS:比较适合使用 Redis 来生成每天从0开始的流水号。比如:“订单号=日期+当日自增长号”,则可以每天在Redis中生成一个Key,使用INCR进行累加。
二、UUID生成
核心思想:结合机器的网卡(基于名字空间/名字的散列值MD5/SHA1)、当地时间(基于时间戳&时钟序列)、一个随记数来生成UUID。
其结构如下:
aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee(即包含32个16进制数字,以连字号-分为五段,最终形成“8-4-4-4-12”的36个字符的字符串,即32个英数字母+4个连字号)。例如:550e8400-e29b-41d4-a716-446655440000
优点:
① 本地生成,没有网络消耗,生成简单,没有高可用风险。
缺点:
① 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
② 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
③ 无序查询效率低:由于生成的UUID是无序不可读的字符串,所以其查询效率低。
◆ 到目前为止业界一共有5种方式生成UUID:
①版本1 - 基于时间的UUID(date-time & MAC address):
规则:主要依赖当前的时间戳及机器mac地址,因此可以保证全球唯一性。
优点:能基本保证全球唯一性。
缺点:使用了Mac地址,因此会暴露Mac地址和生成时间。
②版本2 - 分布式安全的UUID(date-time & group/user id):
规则:将版本1的时间戳前四位换为POSIX的UID或GID,很少使用。
优点:能保证全球唯一性。
缺点:很少使用,常用库基本没有实现。
③版本3 - 基于名字空间的UUID-MD5版(MD5 hash & namespace):
规则:基于指定的名字空间/名字生成MD5散列值得到,标准不推荐。
优点:不同名字空间或名字下的UUID是唯一的;相同名字空间及名字下得到的UUID保持重复。
缺点:MD5碰撞问题,只用于向后兼容,后续不再使用。
④版本4 - 基于随机数的UUID(pseudo-random number):
规则:基于随机数或伪随机数生成。
优点:实现简单。
缺点:重复几率可计算。机率也与随机数产生器的质量有关。若要避免重复机率提高,必须要使用基于密码学上的强伪随机数产生器来生成值才行。
⑤版本5 - 基于名字空间的UUID-SHA1版(SHA-1 hash & namespace):
规则:将版本3的散列算法改为SHA1。
优点:不同名字空间或名字下的UUID是唯一的;相同名字空间及名字下得到的UUID保持重复。
缺点:SHA1计算相对耗时。
总得来说:
①版本 1/2 适用于需要高度唯一性且无需重复的场景。
②版本 3/5 适用于一定范围内唯一且需要或可能会重复生成UUID的环境下。
③版本 4 适用于对唯一性要求不太严格且追求简单的场景。
相关伪代码如下:
// 版本 1 - 基于时间的UUID:
gen_uuid() {
struct uuid uu;
// 获取时间戳
get_time(&clock_mid, &uu.time_low);
uu.time_mid = (uint16_t) clock_mid; // 时间中间位
uu.time_hi_and_version = ((clock_mid >> 16) & 0x0FFF) | 0x1000; // 时间高位 & 版本号
// 获取时钟序列。在libuuid中,尝试取时钟序列+1,取不到则随机;在python中直接使用随机
get_clock(&uu.clock_seq);// 时钟序列+1 或 随机数
uu.clock_seq |= 0x8000;// 时钟序列位 & 变体值
// 节点值
char node_id[6];
get_node_id(node_id);// 根据mac地址等获取节点id
uu.node = node_id;
return uu;
}
// 版本4 - 基于随机数的UUID:
gen_uuid() {
struct uuid uu;
uuid_t buf;
random_get_bytes(buf, sizeof(buf));// 获取随机出来的uuid,如libuuid根据进程id、当日时间戳等进行srand随机
uu.clock_seq = (uu.clock_seq & 0x3FFF) | 0x8000;// 变体值覆盖
uu.time_hi_and_version = (uu.time_hi_and_version & 0x0FFF) | 0x4000;// 版本号覆盖
return uu;
}
// 版本5 - 基于名字空间的UUID(SHA1版):
gen_uuid(name) {
struct uuid uu;
uuid_t buf;
sha_get_bytes(name, buf, sizeof(buf));// 获取name的sha1散列出来的uuid
uu.clock_seq = (uu.clock_seq & 0x3FFF) | 0x8000;// 变体值覆盖
uu.time_hi_and_version = (uu.time_hi_and_version & 0x0FFF) | 0x5000;// 版本号覆盖
return uu;
}
三、雪花算法
核心思想:把64-bit分别划分成多段,分开来标示机器、时间、某一并发序列等,从而使每台机器及同一机器生成的ID都是互不相同。
PS:这种结构是雪花算法提出者Twitter的分法,但实际上这种算法使用可以很灵活,根据自身业务的并发情况、机器分布、使用年限等,可以自由地重新决定各部分的位数,从而增加或减少某部分的量级。比如:百度的UidGenerator、美团的Leaf等,都是基于雪花算法做一些适合自身业务的变化。
下面介绍雪花算法的几种不同优化方案:
1. Twitter的snowflake算法
核心思想是:采用bigint(64bit)作为id生成类型,并将所占的64bit 划分成多段。
其结构如下:
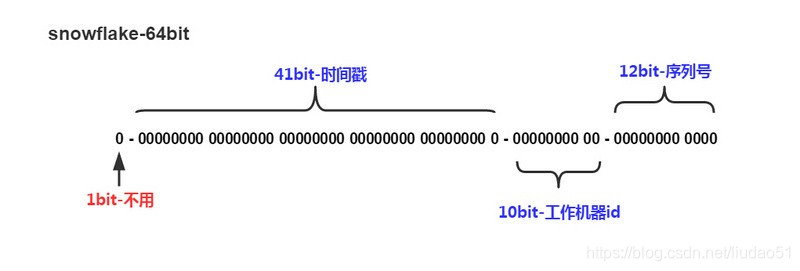
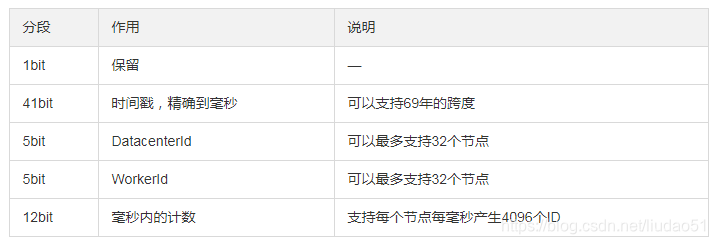
说明:
①1位标识:由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0。
②41位时间截(毫秒级):需要注意的是,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)得到的值,这里的开始时间截,一般是指我们的id生成器开始使用的时间截,由我们的程序来指定。41位的毫秒时间截,可以使用69年(即T =(1L << 41)/(1000 * 60 * 60 * 24 * 365)= 69)。
③10位的数据机器位:包括5位数据中心标识Id(datacenterId)、5位机器标识Id(workerId),最多可以部署1024个节点(即1 << 10 = 1024)。超过这个数量,生成的ID就有可能会冲突。
④12位序列:毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号(即1 << 12 = 4096)。
PS:全部结构标识(1+41+10+12=64)加起来刚好64位,刚好凑成一个Long型。
优点:
①整体上按照时间按时间趋势递增,后续插入索引树的时候性能较好。
②整个分布式系统内不会产生ID碰撞(由数据中心标识ID、机器标识ID作区分)
③本地生成,且不依赖数据库(或第三方组件),没有网络消耗,所以效率高(每秒能够产生26万ID左右)。
缺点:
①由于雪花算法是强依赖于时间的,在分布式环境下,如果发生时钟回拨,很可能会引起ID重复、ID乱序、服务会处于不可用状态等问题。
解决方案有:
a. 将ID生成交给少量服务器,并关闭时钟同步。
b. 直接报错,交给上层业务处理。
c. 如果回拨时间较短,在耗时要求内,比如5ms,那么等待回拨时长后再进行生成。
d. 如果回拨时间很长,那么无法等待,可以匀出少量位(1~2位)作为回拨位,一旦时钟回拨,将回拨位加1,可得到不一样的ID,2位回拨位允许标记3次时钟回拨,基本够使用。如果超出了,可以再选择抛出异常。
Twitter_SnowFlake的源代码(JAVA版):
核心运算逻辑(右移运算&位运算): (timestamp << 22) | (datacenterId << 17) | (workerId << 12) | sequence;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class TwitterUidGeneratorUtil {
// ==============================Fields===========================================
/**
* 开始时间截 (2015-01-01 00:00:00) 毫秒级时间戳
*/
private final long twepoch = 1420041600000L;
/**
* 机器id所占的位数
*/
private final long workerIdBits = 5L;
/**
* 数据标识id所占的位数
*/
private final long datacenterIdBits = 5L;
/**
* 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
*/
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/**
* 支持的最大数据标识id,结果是31
*/
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/**
* 序列在id中占的位数
*/
private final long sequenceBits = 12L;
/**
* 机器ID向左移12位
*/
private final long workerIdShift = sequenceBits;
/**
* 数据标识id向左移17位(12+5)
*/
private final long datacenterIdShift = sequenceBits + workerIdBits;
/**
* 时间截向左移22位(5+5+12)
*/
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/**
* 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
*/
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long datacenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public TwitterUidGeneratorUtil(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
*
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
*
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
*
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/**
* 测试
*/
public static void main(String[] args) {
// 构造方法设置机器码:第9个机房的第20台机器
TwitterUidGeneratorUtil idWorker = new TwitterUidGeneratorUtil(9, 20);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}2. Mongo的ObjectId算法
核心思想是:使用12字节(24bit)的BSON 类型字符串作为ID,并将所占的24bit 划分成多段。
其结构如下:

说明:
①4字节(8位)timeStamp:UNIX时间戳(精确到秒)。
②3字节(6位)machine:所在主机的唯一标识符(一般是机器主机名的散列值)。
③2字节(4位)pid:同一台机器不同的进程产生objectid的进程标识符 。
④3字节(6位)increment:由一个随机数开始的计数器生成的自动增加的值,用来确保在同一秒内产生的objectid也不会发现冲突,允许256^3(16777216)条记录的唯一性。
如:ObjectID(为了方便查看,每部分使用“-”分隔)格式为:5dba76a3-d2c366-7f99-57dfb0
①timeStamp:5dba76a3(对应十进制为:1572501155)。
②machine:d2c366(对应十进制为:13812582)。
③pid:7f99(对应十进制为:32665)。
④increment:57dfb0(对应十进制为:5758896)。
优点:
①本地生成,没有网络消耗,生成简单,没有高可用风险。
②所生成的ID包含时间信息,可以提取时间信息。
缺点:
①不易于存储:12字节24位长度的字符串表示,很多场景不适用。
◆ 新版ObjectId中“机器标识码+进程号” 改为用随机数作为机器标识和进程号的值
mark:从 MongoDB 3.4 开始(最早发布于 2016 年 12 月),ObjectId 的设计被修改了,中间 5 字节的值由原先的 “机器标识码+进程号” 改为用随机数作为机器标识和进程号的值。
那问题来了,为什么不继续使用“机器标识+进程号”呢?
问题就在于,在这个物理机鲜见,虚拟机、云主机、容器横行的时代,机器标识和进程号不太可靠。
①机器标识码:
ObjectId 的机器标识码是取系统 hostname 哈希值的前几位。那么问题来了,准备了几台虚拟机,hostname 都是默认的 localhost,谁都想着这玩意儿能有什么用,还得刻意给不同机器起不同的 hostname? 此外,hostname 在容器、云主机里一般默认就是随机数,也不会检查同一集群里是否有hostname 重名。
②进程号:
这个问题就更大了,要知道,容器内的进程拥有自己独立的进程空间,在这个空间里只用它自己这一个进程(以及它的子进程),所以它的进程号永远都是 1。也就是说,如果某个服务(既可以是 mongo 实例也可以是 mongo 客户端)是使用容器部署的,无论部署多少个实例,在这个服务上生成的 ObjectId,第八第九个字节恒为 0000 0001,相当于说这两个字节废了。
综上,与其使用一个固定值来“区分不同进程实例”,且这个固定值还是人类随意设置或随机生成的 hostname 加上一个可能恒为 1 的进程号,倒不如每次都随机生成一个新值。
可见,这是平台层面的架构变动影响了应用层面的设计方案,随着云、容器的继续发展,这样的故事还会继续上演。
1)旧版:使用主机名的散列值作用machine、使用进程标识符作为pid
Java版代码:
import com.google.common.base.Objects;
import java.net.NetworkInterface;
import java.nio.ByteBuffer;
import java.util.Date;
import java.util.Enumeration;
import java.util.Random;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* MongoDB的ObjectId对象的全局唯一标识符。
* 由12个字节组成,划分如下:
* 1)4字节(8位)timeStamp:UNIX时间戳(精确到秒)。
* 2)3字节(6位)machine:所在主机的唯一标识符(一般是机器主机名的散列值)。
* 3)2字节(4位)pid:同一台机器不同的进程产生objectid的进程标识符 。
* 4)3字节(6位)increment:由一个随机数开始的计数器生成的自动增加的值,用来确保在同一秒内产生的objectid也不会发现冲突,允许256^3(16777216)条记录的唯一性。
* <p>
* 2次生成的结果为:
* 5dbbd4c3 d2c335 d03a c768fd
* 5dbbd555 d2c3b5 315c 045c13
*/
public class OldMongoUidGeneratorUtil implements Comparable<OldMongoUidGeneratorUtil>, java.io.Serializable {
private final int _time;
private final int _machine;
private final int _inc;
private boolean _new;
private static final int _genmachine;
private static AtomicInteger _nextInc = new AtomicInteger((new Random()).nextInt());
private static final long serialVersionUID = -4415279469780082174L;
private static final Logger LOGGER = Logger.getLogger("org.bson.ObjectId");
/**
* Create a new object id.
*/
public OldMongoUidGeneratorUtil() {
_time = (int) (System.currentTimeMillis() / 1000);
_machine = _genmachine;
_inc = _nextInc.getAndIncrement();
_new = true;
}
public static String id() {
return get().toHexString();
}
/**
* Gets a new object id.
*
* @return the new id
*/
public static OldMongoUidGeneratorUtil get() {
return new OldMongoUidGeneratorUtil();
}
/**
* Checks if a string could be an {@code ObjectId}.
*
* @param s a potential ObjectId as a String.
* @return whether the string could be an object id
* @throws IllegalArgumentException if hexString is null
*/
public static boolean isValid(String s) {
if (s == null)
return false;
final int len = s.length();
if (len != 24)
return false;
for (int i = 0; i < len; i++) {
char c = s.charAt(i);
if (c >= '0' && c <= '9')
continue;
if (c >= 'a' && c <= 'f')
continue;
if (c >= 'A' && c <= 'F')
continue;
return false;
}
return true;
}
/**
* Converts this instance into a 24-byte hexadecimal string representation.
*
* @return a string representation of the ObjectId in hexadecimal format
*/
public String toHexString() {
final StringBuilder buf = new StringBuilder(24);
for (final byte b : toByteArray()) {
buf.append(String.format("%02x", b & 0xff));
}
return buf.toString();
}
/**
* Convert to a byte array. Note that the numbers are stored in big-endian order.
*
* @return the byte array
*/
public byte[] toByteArray() {
byte b[] = new byte[12];
ByteBuffer bb = ByteBuffer.wrap(b);
// by default BB is big endian like we need
bb.putInt(_time);
bb.putInt(_machine);
bb.putInt(_inc);
return b;
}
private int _compareUnsigned(int i, int j) {
long li = 0xFFFFFFFFL;
li = i & li;
long lj = 0xFFFFFFFFL;
lj = j & lj;
long diff = li - lj;
if (diff < Integer.MIN_VALUE)
return Integer.MIN_VALUE;
if (diff > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
return (int) diff;
}
public int compareTo(OldMongoUidGeneratorUtil id) {
if (id == null)
return -1;
int x = _compareUnsigned(_time, id._time);
if (x != 0)
return x;
x = _compareUnsigned(_machine, id._machine);
if (x != 0)
return x;
return _compareUnsigned(_inc, id._inc);
}
/**
* Gets the timestamp (number of seconds since the Unix epoch).
*
* @return the timestamp
*/
public int getTimestamp() {
return _time;
}
/**
* Gets the timestamp as a {@code Date} instance.
*
* @return the Date
*/
public Date getDate() {
return new Date(_time * 1000L);
}
/**
* Gets the current value of the auto-incrementing counter.
*
* @return the current counter value.
*/
public static int getCurrentCounter() {
return _nextInc.get();
}
static {
try {
// build a 2-byte machine piece based on NICs info
int machinePiece;
{
try {
StringBuilder sb = new StringBuilder();
Enumeration<NetworkInterface> e = NetworkInterface.getNetworkInterfaces();
while (e.hasMoreElements()) {
NetworkInterface ni = e.nextElement();
sb.append(ni.toString());
}
machinePiece = sb.toString().hashCode() << 16;
} catch (Throwable e) {
// exception sometimes happens with IBM JVM, use random
LOGGER.log(Level.WARNING, e.getMessage(), e);
machinePiece = (new Random().nextInt()) << 16;
}
LOGGER.fine("machine piece post: " + Integer.toHexString(machinePiece));
}
// add a 2 byte process piece. It must represent not only the JVM but the class loader.
// Since static var belong to class loader there could be collisions otherwise
final int processPiece;
{
int processId = new Random().nextInt();
try {
processId = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().hashCode();
} catch (Throwable t) {
}
ClassLoader loader = OldMongoUidGeneratorUtil.class.getClassLoader();
int loaderId = loader != null ? System.identityHashCode(loader) : 0;
StringBuilder sb = new StringBuilder();
sb.append(Integer.toHexString(processId));
sb.append(Integer.toHexString(loaderId));
processPiece = sb.toString().hashCode() & 0xFFFF;
LOGGER.fine("process piece: " + Integer.toHexString(processPiece));
}
_genmachine = machinePiece | processPiece;
LOGGER.fine("machine : " + Integer.toHexString(_genmachine));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
OldMongoUidGeneratorUtil that = (OldMongoUidGeneratorUtil) o;
return Objects.equal(this.serialVersionUID, that.serialVersionUID) &&
Objects.equal(this.LOGGER, that.LOGGER) &&
Objects.equal(this._time, that._time) &&
Objects.equal(this._machine, that._machine) &&
Objects.equal(this._inc, that._inc) &&
Objects.equal(this._new, that._new) &&
Objects.equal(this._nextInc, that._nextInc) &&
Objects.equal(this._genmachine, that._genmachine);
}
@Override
public int hashCode() {
return Objects.hashCode(serialVersionUID, LOGGER, _time, _machine, _inc, _new,
_nextInc, _genmachine);
}
public static void main(String[] args) {
System.out.println(new OldMongoUidGeneratorUtil().toHexString());
System.out.println(new OldMongoUidGeneratorUtil().toHexString());
System.out.println(new OldMongoUidGeneratorUtil().toHexString());
}
}2)新版:使用随机数作为machine、pid的值
Java版代码:
import java.io.Serializable;
import java.nio.ByteBuffer;
import java.security.SecureRandom;
import java.util.Date;
import java.util.concurrent.atomic.AtomicInteger;
/**
* MongoDB的ObjectId对象的全局唯一标识符。
* 由12个字节组成,划分如下:
* 1)4字节(8位)timeStamp:UNIX时间戳(精确到秒)。
* 2)3字节(6位)machine:所在主机的唯一标识符(这里使用随机值)。
* 3)2字节(4位)pid:同一台机器不同的进程产生objectid的进程标识符(这里使用随机值) 。
* 4)3字节(6位)increment:由一个随机数开始的计数器生成的自动增加的值,用来确保在同一秒内产生的objectid也不会发现冲突,允许256^3(16777216)条记录的唯一性。
*
* @mongodb.driver.manual core/object-id ObjectId
* <p>
* 2次生成的结果为:
* 5dbbd598 8dd521 6733 04ca5c
* 5dbbd5a7 5350a9 3c97 3a1692
*/
public final class NewMongoUidGeneratorUtil implements Comparable<NewMongoUidGeneratorUtil>, Serializable {
private static final long serialVersionUID = 3670079982654483072L;
private static final int OBJECT_ID_LENGTH = 12;
private static final int LOW_ORDER_THREE_BYTES = 0x00ffffff;
// Use primitives to represent the 5-byte random value.
private static final int RANDOM_VALUE1;
private static final short RANDOM_VALUE2;
private static final AtomicInteger NEXT_COUNTER = new AtomicInteger(new SecureRandom().nextInt());
private static final char[] HEX_CHARS = new char[]{
'0', '1', '2', '3', '4', '5', '6', '7',
'8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
private final int timestamp;
private final int counter;
private final int randomValue1;
private final short randomValue2;
/**
* Gets a new object id.
*
* @return the new id
*/
public static NewMongoUidGeneratorUtil get() {
return new NewMongoUidGeneratorUtil();
}
/**
* Checks if a string could be an {@code ObjectId}.
*
* @param hexString a potential ObjectId as a String.
* @return whether the string could be an object id
* @throws IllegalArgumentException if hexString is null
*/
public static boolean isValid(final String hexString) {
if (hexString == null) {
throw new IllegalArgumentException();
}
int len = hexString.length();
if (len != 24) {
return false;
}
for (int i = 0; i < len; i++) {
char c = hexString.charAt(i);
if (c >= '0' && c <= '9') {
continue;
}
if (c >= 'a' && c <= 'f') {
continue;
}
if (c >= 'A' && c <= 'F') {
continue;
}
return false;
}
return true;
}
/**
* Create a new object id.
*/
public NewMongoUidGeneratorUtil() {
this(new Date());
}
/**
* Constructs a new instance using the given date.
*
* @param date the date
*/
public NewMongoUidGeneratorUtil(final Date date) {
this(dateToTimestampSeconds(date), NEXT_COUNTER.getAndIncrement() & LOW_ORDER_THREE_BYTES, false);
}
/**
* Constructs a new instances using the given date and counter.
*
* @param date the date
* @param counter the counter
* @throws IllegalArgumentException if the high order byte of counter is not zero
*/
public NewMongoUidGeneratorUtil(final Date date, final int counter) {
this(dateToTimestampSeconds(date), counter, true);
}
/**
* Constructs a new instances using the given date, machine identifier, process identifier, and counter.
*
* @param date the date
* @param machineIdentifier the machine identifier
* @param processIdentifier the process identifier
* @param counter the counter
* @throws IllegalArgumentException if the high order byte of machineIdentifier or counter is not zero
* @deprecated Use {@link #NewMongoUidGeneratorUtil(Date, int)} instead
*/
@Deprecated
public NewMongoUidGeneratorUtil(final Date date, final int machineIdentifier, final short processIdentifier, final int counter) {
this(dateToTimestampSeconds(date), machineIdentifier, processIdentifier, counter);
}
/**
* Creates an ObjectId using the given time, machine identifier, process identifier, and counter.
*
* @param timestamp the time in seconds
* @param machineIdentifier the machine identifier
* @param processIdentifier the process identifier
* @param counter the counter
* @throws IllegalArgumentException if the high order byte of machineIdentifier or counter is not zero
* @deprecated Use {@link #NewMongoUidGeneratorUtil(int, int)} instead
*/
@Deprecated
public NewMongoUidGeneratorUtil(final int timestamp, final int machineIdentifier, final short processIdentifier, final int counter) {
this(timestamp, machineIdentifier, processIdentifier, counter, true);
}
/**
* Creates an ObjectId using the given time, machine identifier, process identifier, and counter.
*
* @param timestamp the time in seconds
* @param counter the counter
* @throws IllegalArgumentException if the high order byte of counter is not zero
*/
public NewMongoUidGeneratorUtil(final int timestamp, final int counter) {
this(timestamp, counter, true);
}
private NewMongoUidGeneratorUtil(final int timestamp, final int counter, final boolean checkCounter) {
this(timestamp, RANDOM_VALUE1, RANDOM_VALUE2, counter, checkCounter);
}
private NewMongoUidGeneratorUtil(final int timestamp, final int randomValue1, final short randomValue2, final int counter,
final boolean checkCounter) {
if ((randomValue1 & 0xff000000) != 0) {
throw new IllegalArgumentException("The machine identifier must be between 0 and 16777215 (it must fit in three bytes).");
}
if (checkCounter && ((counter & 0xff000000) != 0)) {
throw new IllegalArgumentException("The counter must be between 0 and 16777215 (it must fit in three bytes).");
}
this.timestamp = timestamp;
this.counter = counter & LOW_ORDER_THREE_BYTES;
this.randomValue1 = randomValue1;
this.randomValue2 = randomValue2;
}
/**
* Constructs a new instance from a 24-byte hexadecimal string representation.
*
* @param hexString the string to convert
* @throws IllegalArgumentException if the string is not a valid hex string representation of an ObjectId
*/
public NewMongoUidGeneratorUtil(final String hexString) {
this(parseHexString(hexString));
}
/**
* Constructs a new instance from the given byte array
*
* @param bytes the byte array
* @throws IllegalArgumentException if array is null or not of length 12
*/
public NewMongoUidGeneratorUtil(final byte[] bytes) {
this(ByteBuffer.wrap(bytes));
}
/**
* Creates an ObjectId
*
* @param timestamp time in seconds
* @param machineAndProcessIdentifier machine and process identifier
* @param counter incremental value
*/
NewMongoUidGeneratorUtil(final int timestamp, final int machineAndProcessIdentifier, final int counter) {
this(legacyToBytes(timestamp, machineAndProcessIdentifier, counter));
}
/**
* Constructs a new instance from the given ByteBuffer
*
* @param buffer the ByteBuffer
* @throws IllegalArgumentException if the buffer is null or does not have at least 12 bytes remaining
* @since 3.4
*/
public NewMongoUidGeneratorUtil(final ByteBuffer buffer) {
if (buffer == null) {
throw new IllegalArgumentException("buffer can not be null");
}
if (!(buffer.remaining() >= OBJECT_ID_LENGTH)) {
throw new IllegalArgumentException("state should be: buffer.remaining() >=12");
}
// Note: Cannot use ByteBuffer.getInt because it depends on tbe buffer's byte order
// and ObjectId's are always in big-endian order.
timestamp = makeInt(buffer.get(), buffer.get(), buffer.get(), buffer.get());
randomValue1 = makeInt((byte) 0, buffer.get(), buffer.get(), buffer.get());
randomValue2 = makeShort(buffer.get(), buffer.get());
counter = makeInt((byte) 0, buffer.get(), buffer.get(), buffer.get());
}
private static byte[] legacyToBytes(final int timestamp, final int machineAndProcessIdentifier, final int counter) {
byte[] bytes = new byte[OBJECT_ID_LENGTH];
bytes[0] = int3(timestamp);
bytes[1] = int2(timestamp);
bytes[2] = int1(timestamp);
bytes[3] = int0(timestamp);
bytes[4] = int3(machineAndProcessIdentifier);
bytes[5] = int2(machineAndProcessIdentifier);
bytes[6] = int1(machineAndProcessIdentifier);
bytes[7] = int0(machineAndProcessIdentifier);
bytes[8] = int3(counter);
bytes[9] = int2(counter);
bytes[10] = int1(counter);
bytes[11] = int0(counter);
return bytes;
}
/**
* Convert to a byte array. Note that the numbers are stored in big-endian order.
*
* @return the byte array
*/
public byte[] toByteArray() {
ByteBuffer buffer = ByteBuffer.allocate(OBJECT_ID_LENGTH);
putToByteBuffer(buffer);
return buffer.array(); // using .allocate ensures there is a backing array that can be returned
}
/**
* Convert to bytes and put those bytes to the provided ByteBuffer.
* Note that the numbers are stored in big-endian order.
*
* @param buffer the ByteBuffer
* @throws IllegalArgumentException if the buffer is null or does not have at least 12 bytes remaining
* @since 3.4
*/
public void putToByteBuffer(final ByteBuffer buffer) {
if (buffer == null) {
throw new IllegalArgumentException("buffer can not be null");
}
if (!(buffer.remaining() >= OBJECT_ID_LENGTH)) {
throw new IllegalArgumentException("state should be: buffer.remaining() >=12");
}
buffer.put(int3(timestamp));
buffer.put(int2(timestamp));
buffer.put(int1(timestamp));
buffer.put(int0(timestamp));
buffer.put(int2(randomValue1));
buffer.put(int1(randomValue1));
buffer.put(int0(randomValue1));
buffer.put(short1(randomValue2));
buffer.put(short0(randomValue2));
buffer.put(int2(counter));
buffer.put(int1(counter));
buffer.put(int0(counter));
}
/**
* Gets the timestamp (number of seconds since the Unix epoch).
*
* @return the timestamp
*/
public int getTimestamp() {
return timestamp;
}
/**
* Gets the timestamp as a {@code Date} instance.
*
* @return the Date
*/
public Date getDate() {
return new Date((timestamp & 0xFFFFFFFFL) * 1000L);
}
/**
* Converts this instance into a 24-byte hexadecimal string representation.
*
* @return a string representation of the ObjectId in hexadecimal format
*/
public String toHexString() {
char[] chars = new char[OBJECT_ID_LENGTH * 2];
int i = 0;
for (byte b : toByteArray()) {
chars[i++] = HEX_CHARS[b >> 4 & 0xF];
chars[i++] = HEX_CHARS[b & 0xF];
}
return new String(chars);
}
@Override
public boolean equals(final Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
NewMongoUidGeneratorUtil objectId = (NewMongoUidGeneratorUtil) o;
if (counter != objectId.counter) {
return false;
}
if (timestamp != objectId.timestamp) {
return false;
}
if (randomValue1 != objectId.randomValue1) {
return false;
}
if (randomValue2 != objectId.randomValue2) {
return false;
}
return true;
}
@Override
public int hashCode() {
int result = timestamp;
result = 31 * result + counter;
result = 31 * result + randomValue1;
result = 31 * result + randomValue2;
return result;
}
@Override
public int compareTo(final NewMongoUidGeneratorUtil other) {
if (other == null) {
throw new NullPointerException();
}
byte[] byteArray = toByteArray();
byte[] otherByteArray = other.toByteArray();
for (int i = 0; i < OBJECT_ID_LENGTH; i++) {
if (byteArray[i] != otherByteArray[i]) {
return ((byteArray[i] & 0xff) < (otherByteArray[i] & 0xff)) ? -1 : 1;
}
}
return 0;
}
@Override
public String toString() {
return toHexString();
}
// Deprecated methods
/**
* <p>Creates an ObjectId using time, machine and inc values. The Java driver used to create all ObjectIds this way, but it does not
* match the <a href="http://docs.mongodb.org/manual/reference/object-id/">ObjectId specification</a>, which requires four values, not
* three. This major release of the Java driver conforms to the specification, but still supports clients that are relying on the
* behavior of the previous major release by providing this explicit factory method that takes three parameters instead of four.</p>
* <p>
* <p>Ordinary users of the driver will not need this method. It's only for those that have written there own BSON decoders.</p>
* <p>
* <p>NOTE: This will not break any application that use ObjectIds. The 12-byte representation will be round-trippable from old to new
* driver releases.</p>
*
* @param time time in seconds
* @param machine machine ID
* @param inc incremental value
* @return a new {@code ObjectId} created from the given values
* @since 2.12.0
* @deprecated Use {@link #NewMongoUidGeneratorUtil(int, int)} instead
*/
@Deprecated
public static NewMongoUidGeneratorUtil createFromLegacyFormat(final int time, final int machine, final int inc) {
return new NewMongoUidGeneratorUtil(time, machine, inc);
}
/**
* Gets the current value of the auto-incrementing counter.
*
* @return the current counter value.
* @deprecated
*/
@Deprecated
public static int getCurrentCounter() {
return NEXT_COUNTER.get() & LOW_ORDER_THREE_BYTES;
}
/**
* Gets the generated machine identifier.
*
* @return an int representing the machine identifier
* @deprecated
*/
@Deprecated
public static int getGeneratedMachineIdentifier() {
return RANDOM_VALUE1;
}
/**
* Gets the generated process identifier.
*
* @return the process id
* @deprecated
*/
@Deprecated
public static int getGeneratedProcessIdentifier() {
return RANDOM_VALUE2;
}
/**
* Gets the machine identifier.
*
* @return the machine identifier
* @deprecated
*/
@Deprecated
public int getMachineIdentifier() {
return randomValue1;
}
/**
* Gets the process identifier.
*
* @return the process identifier
* @deprecated
*/
@Deprecated
public short getProcessIdentifier() {
return randomValue2;
}
/**
* Gets the counter.
*
* @return the counter
* @deprecated
*/
@Deprecated
public int getCounter() {
return counter;
}
/**
* Gets the time of this ID, in seconds.
*
* @return the time component of this ID in seconds
* @deprecated Use #getTimestamp instead
*/
@Deprecated
public int getTimeSecond() {
return timestamp;
}
/**
* Gets the time of this instance, in milliseconds.
*
* @return the time component of this ID in milliseconds
* @deprecated Use #getDate instead
*/
@Deprecated
public long getTime() {
return (timestamp & 0xFFFFFFFFL) * 1000L;
}
/**
* @return a string representation of the ObjectId in hexadecimal format
* @see NewMongoUidGeneratorUtil#toHexString()
* @deprecated use {@link #toHexString()}
*/
@Deprecated
public String toStringMongod() {
return toHexString();
}
static {
try {
SecureRandom secureRandom = new SecureRandom();
RANDOM_VALUE1 = secureRandom.nextInt(0x01000000);
RANDOM_VALUE2 = (short) secureRandom.nextInt(0x00008000);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private static byte[] parseHexString(final String s) {
if (!isValid(s)) {
throw new IllegalArgumentException("invalid hexadecimal representation of an ObjectId: [" + s + "]");
}
byte[] b = new byte[OBJECT_ID_LENGTH];
for (int i = 0; i < b.length; i++) {
b[i] = (byte) Integer.parseInt(s.substring(i * 2, i * 2 + 2), 16);
}
return b;
}
private static int dateToTimestampSeconds(final Date time) {
return (int) (time.getTime() / 1000);
}
// Big-Endian helpers, in this class because all other BSON numbers are little-endian
private static int makeInt(final byte b3, final byte b2, final byte b1, final byte b0) {
// CHECKSTYLE:OFF
return (((b3) << 24) |
((b2 & 0xff) << 16) |
((b1 & 0xff) << 8) |
((b0 & 0xff)));
// CHECKSTYLE:ON
}
private static short makeShort(final byte b1, final byte b0) {
// CHECKSTYLE:OFF
return (short) (((b1 & 0xff) << 8) | ((b0 & 0xff)));
// CHECKSTYLE:ON
}
private static byte int3(final int x) {
return (byte) (x >> 24);
}
private static byte int2(final int x) {
return (byte) (x >> 16);
}
private static byte int1(final int x) {
return (byte) (x >> 8);
}
private static byte int0(final int x) {
return (byte) (x);
}
private static byte short1(final short x) {
return (byte) (x >> 8);
}
private static byte short0(final short x) {
return (byte) (x);
}
public static void main(String[] args) {
System.out.println(new NewMongoUidGeneratorUtil().toHexString());
System.out.println(new NewMongoUidGeneratorUtil().toHexString());
System.out.println(new NewMongoUidGeneratorUtil().toHexString());
}
}
3. 百度UidGenerator算法
UidGenerator是百度开源的分布式ID生成器,是基于snowflake算法的实现,看起来感觉还行,但是需要借助数据库,配置起来比较复杂。
具体可以参考官网说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4. 美团Leaf算法
Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明: Leaf——美团点评分布式ID生成系统 - 美团技术团队
小结:这篇文章和大家分享了全局id生成服务的几种常用方案,同时对比了各自的优缺点和适用场景。在实际工作中,大家可以结合自身业务和系统架构体系进行合理选型。
微信公众号 - 稻哥说编程(RedCode1024)博主,从事程序开发10余年,分享有用的行业解决方案,欢迎留言交流。

















 1858
1858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









