







基于Django实现的(bert)深度学习文本相似度检测系统设计
-
开发语言:Python
- 数据库:MySQL
- 所用到的知识:Django框架
- 工具:pycharm、Navicat、Maven
系统功能实现
-
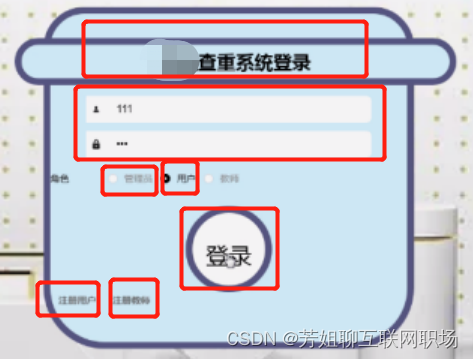
登录页面
注册页面:用户账号,密码,确认密码,用户姓名,联系方式

主页面:文件管理模块
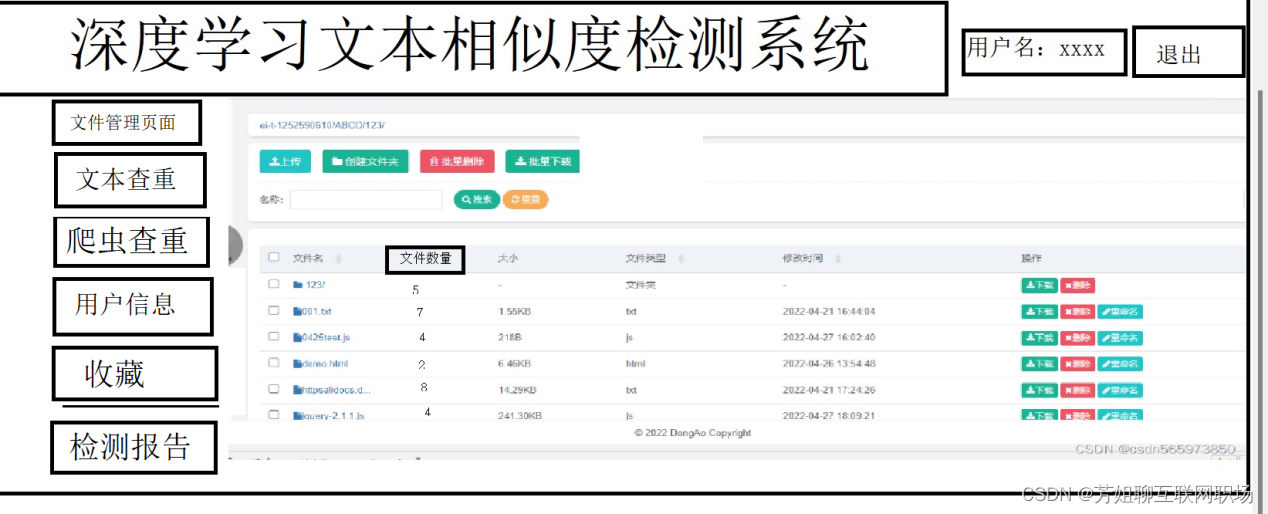

上传功能
(3)批量删除文件夹功能,可选
![]()
(4)批量下载文件夹,可选
(5)搜索功能(文件夹)
(6)单独文件夹按钮下载
(7)收藏功能按钮

文件属性:下载按钮,编辑按钮(文本内增减删),删除按钮,收藏按钮,文本内容查询
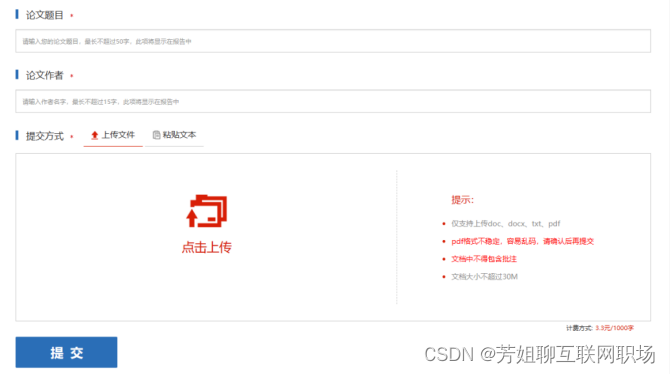
 文本查重模块
文本查重模块
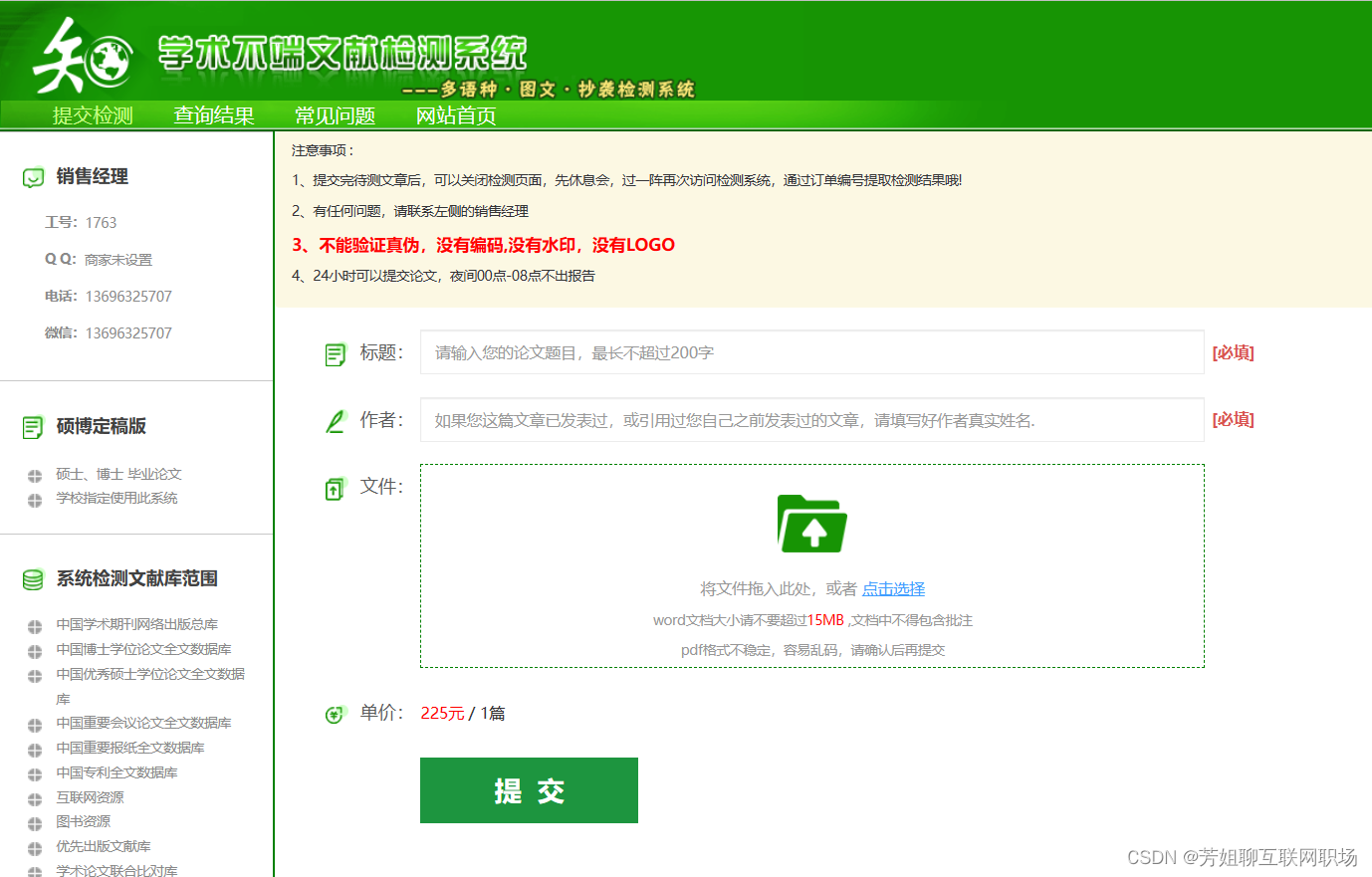
收藏模块;用户收藏的文件夹与文件:
任务栏属性:文本名称,作者名称,文件大小,修改日期,
文件夹属性:本文本查看,删除文件,修改文本内容,并保存修改的内容,下载文本
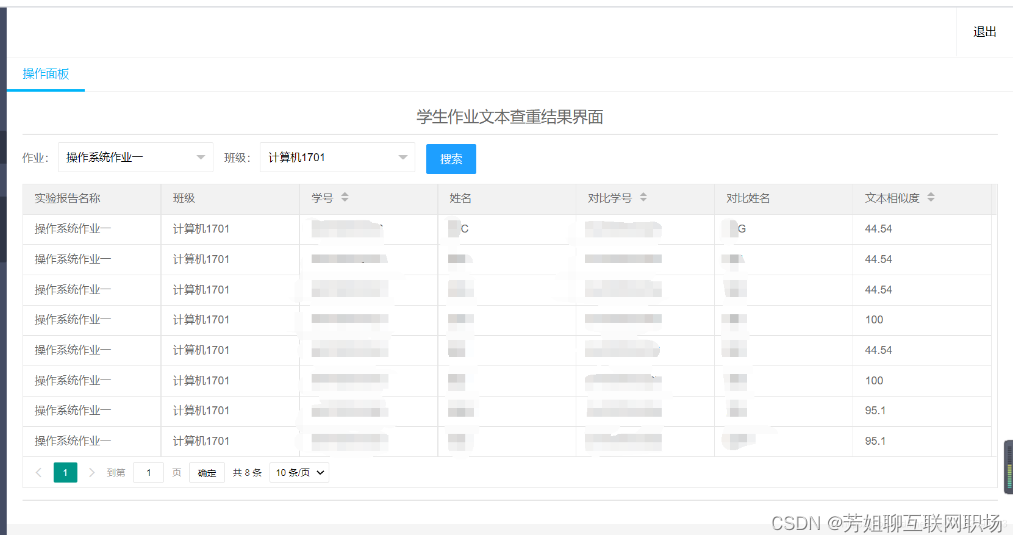
网页查重-(爬虫):文本查重网页版 爬取百度搜索结果页全部链接内容


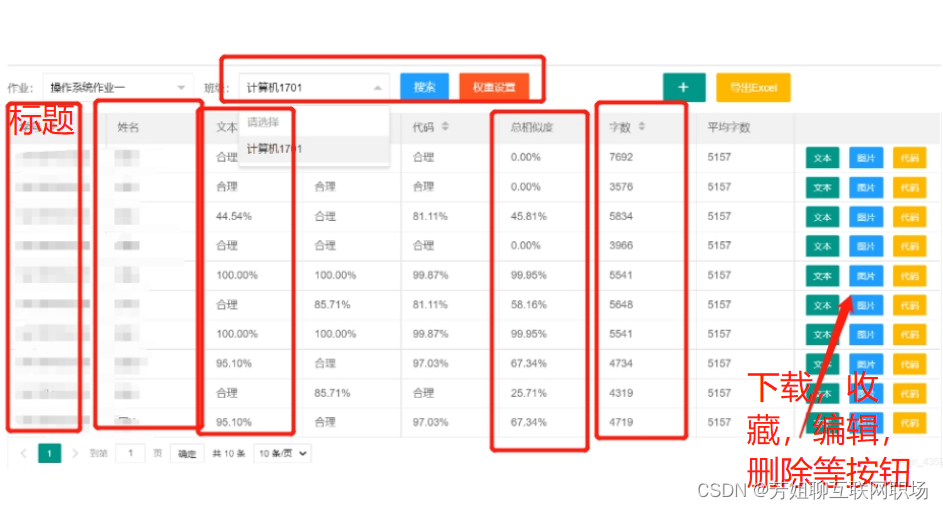
文本相似度的检测报告的pdf格式

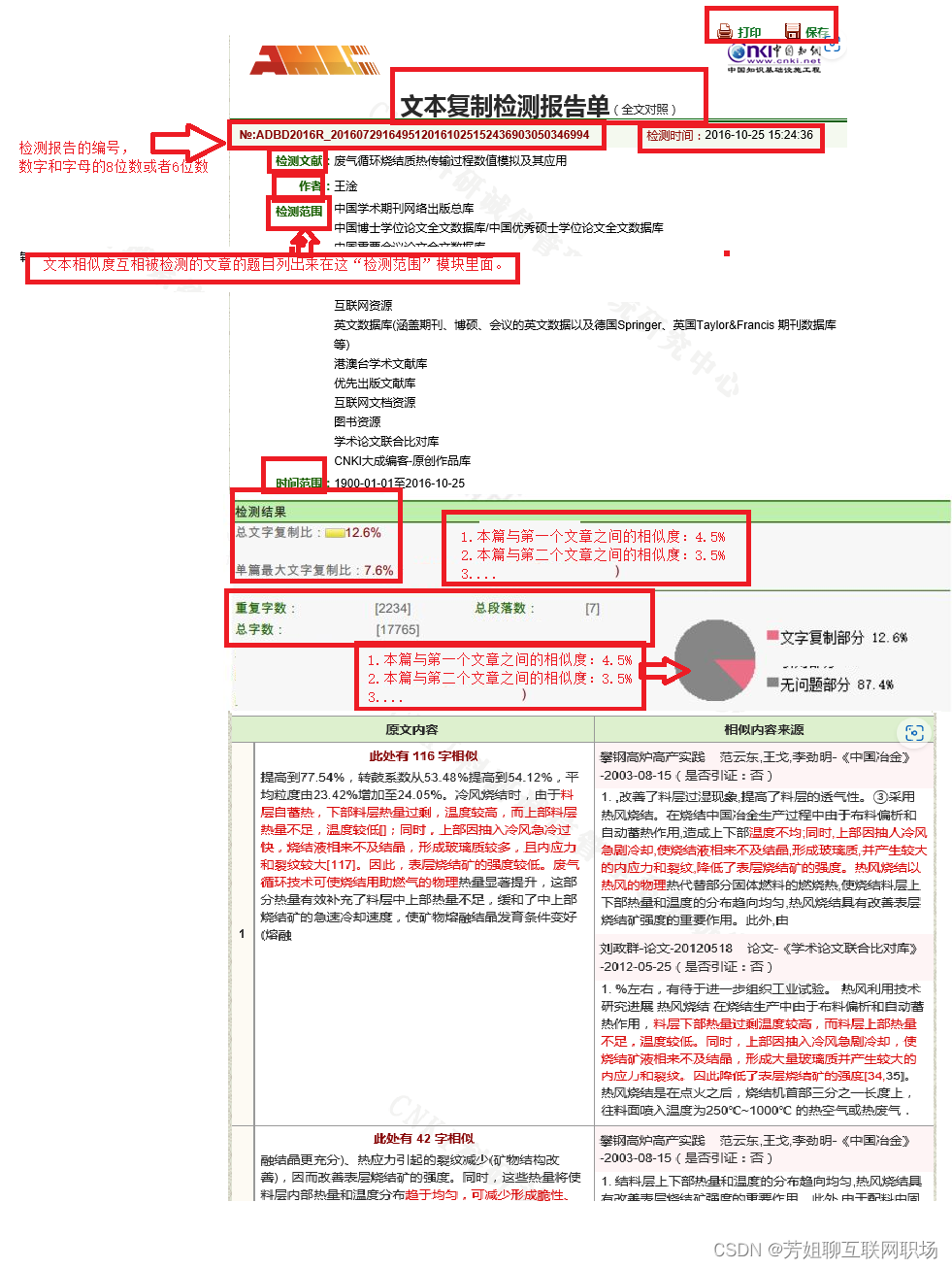
检测报告的形成:pdf格式
检测报告内容是:1.可以打印,2.保存本地;
- 检测报告编号:数字和字母组成,6位数;
- 文本题目,作者,检测范围(互相被检测的文本题目)
- 检测时间,时间范围(有效时间用户自己输入的)
- 检测结果
- 总文本总数相似度:12.6%
- 本篇与第一个文章之间的相似度: 4.5%
- 本篇与第二个文章之间的相似度: 3.5%
- .................
- 统计出各个文本之间相似度的统计图,
- 原文内容与相似度来源的文本之间的对比列出,
以下图片参考:
检测报告的任务栏属性:文本名称,作者名,文件大小,报告生成时间,报告下载按钮,报告搜索框(按照文本名与作者),总文本相似度,报告删除按钮,
检测报告(pdf格式)以下的图片一比一还原,
检测报告内容是:1.可以打印,2.保存本地;
- 检测报告编号:数字和字母组成,6位数;
- 文本题目,作者,检测范围(互相被检测的文本题目)
- 检测时间,时间范围(有效时间用户自己输入的)
- 检测结果
- 总文本总数相似度:12.6%
- 本篇与第一个文章之间的相似度: 4.5%
- 本篇与第二个文章之间的相似度: 3.5%
- .................
- 统计出各个文本之间相似度的统计图,
- 原文内容与相似度来源的文本之间的对比列出,
以下图片参考:
检测报告的任务栏属性:文本名称,作者名,文件大小,报告生成时间,报告下载按钮,报告搜索框(按照文本名与作者),总文本相似度,报告删除按钮,
检测报告(pdf格式)以下的图片一比一还原,
8用户信息:看到个人的基本信息,上传个人图
需要源代码或者二次开发的,请联系
















 1957
1957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









