







基于Django和深度学习的花分类检测系统
- 一、引言
- 二、Django部分
- 1. 创建Django项目
- 2. 创建APP
- 3. 编写路由
- 4. 编写login请求的视图函数
- 4.2 路由(urls)和视图(views)的对应关系
- 5. 编写处理花分类请求的视图函数
- 三、深度学习模型部分
- 四、前端部分
- 1. 上传图片部分
- 2. 解决发送请求后页面跳转的问题
- 3. 视频识别获取某一帧的图像
- 五、代码获取
一、引言
因为博主本科是软件工程专业,主要搞的是B/S端的开发。研究生转人工智能方向,所以想着把两者结合一下,搞一个小型的分类系统,目前也算是搭了一个框架出来,后续有别的检测分割的任务也可以写进该django框架。
实现效果如下:
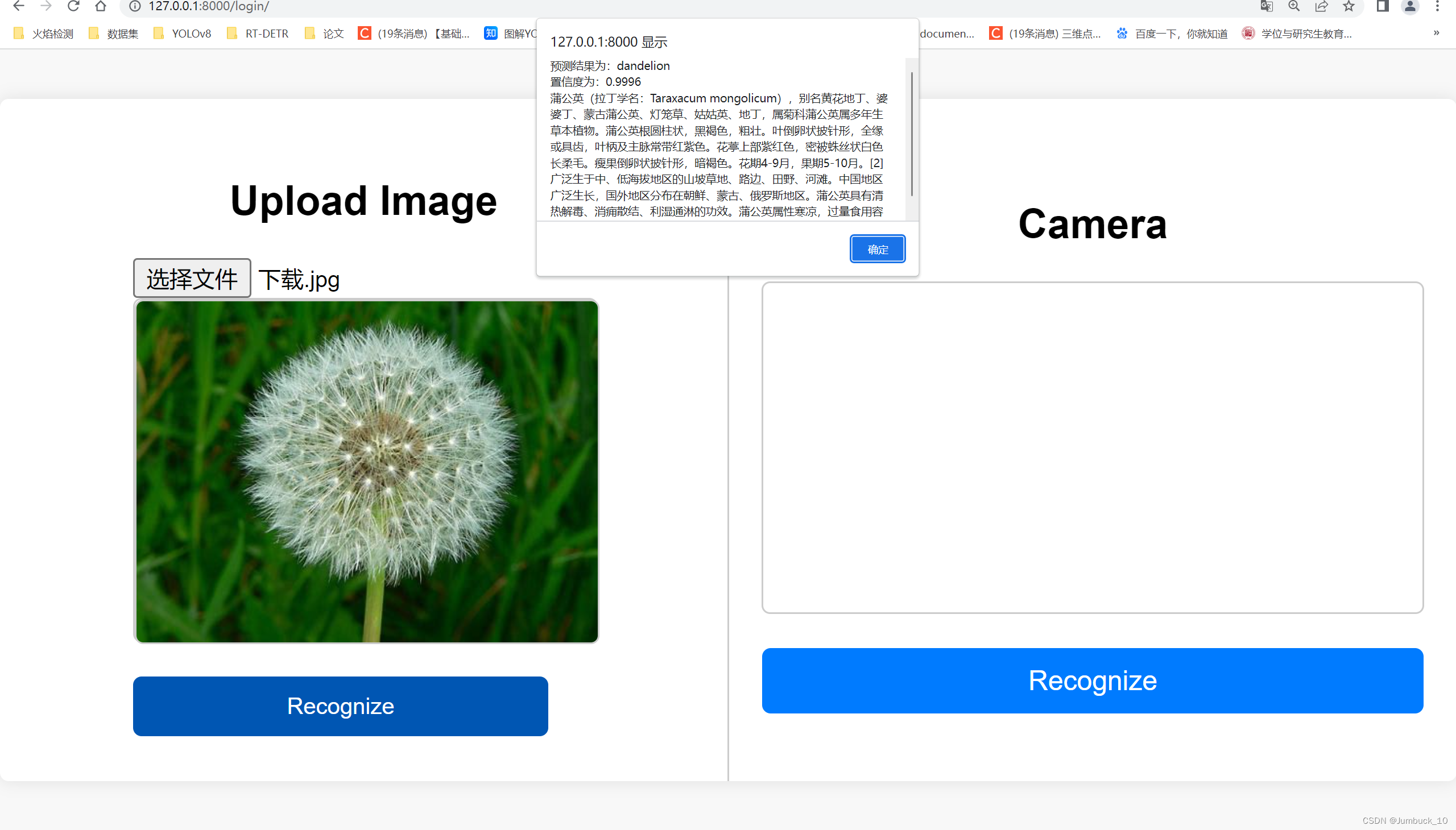
图1、上传需要检测的图像,点击Recognize识别,上方弹出检测结果,显示预测结果,置信度,花的简介
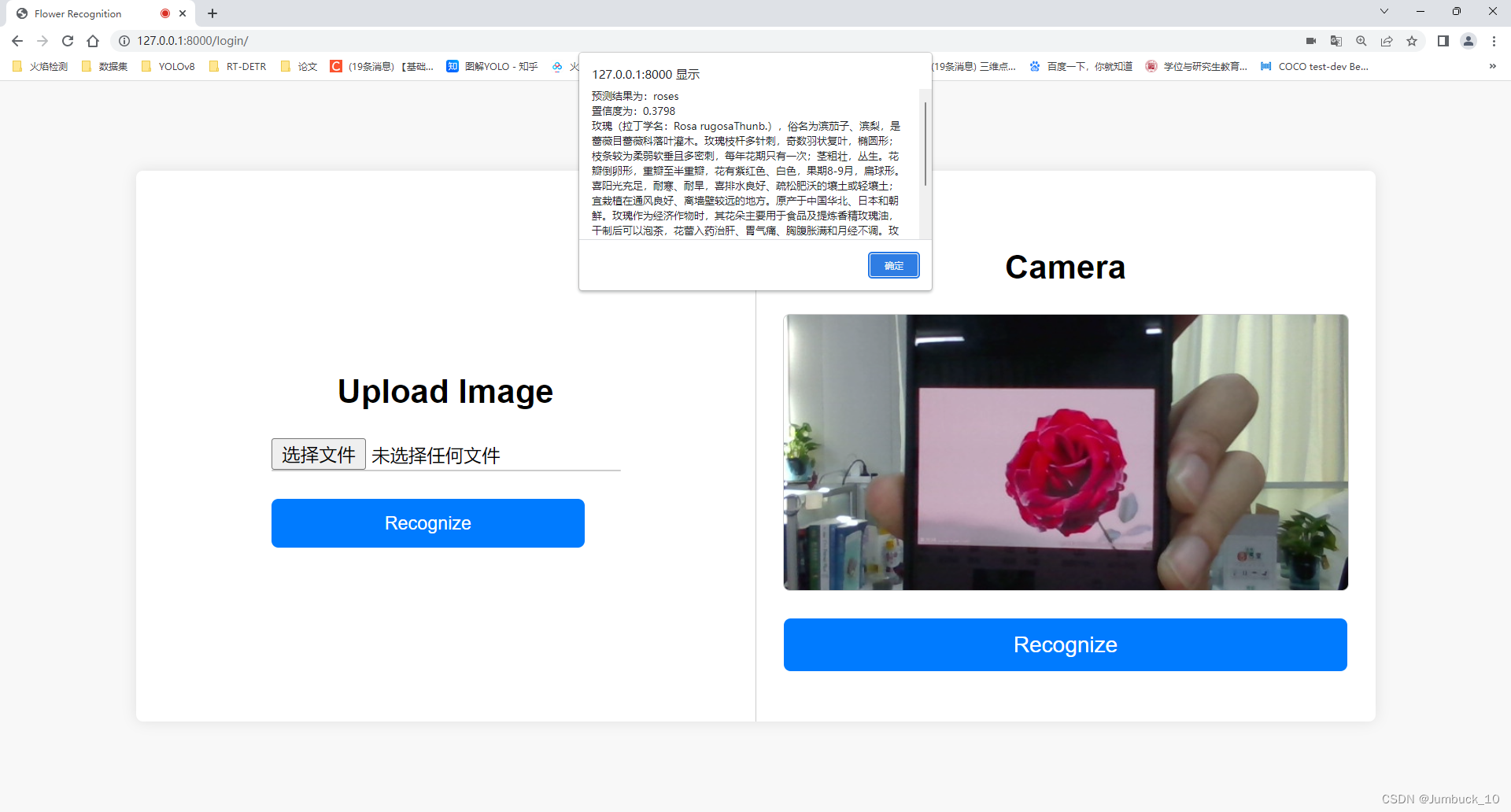 图2、开启电脑摄像头进行检测,点击右侧的Recognize,即可调用摄像头,每隔2秒进行一次检测
图2、开启电脑摄像头进行检测,点击右侧的Recognize,即可调用摄像头,每隔2秒进行一次检测
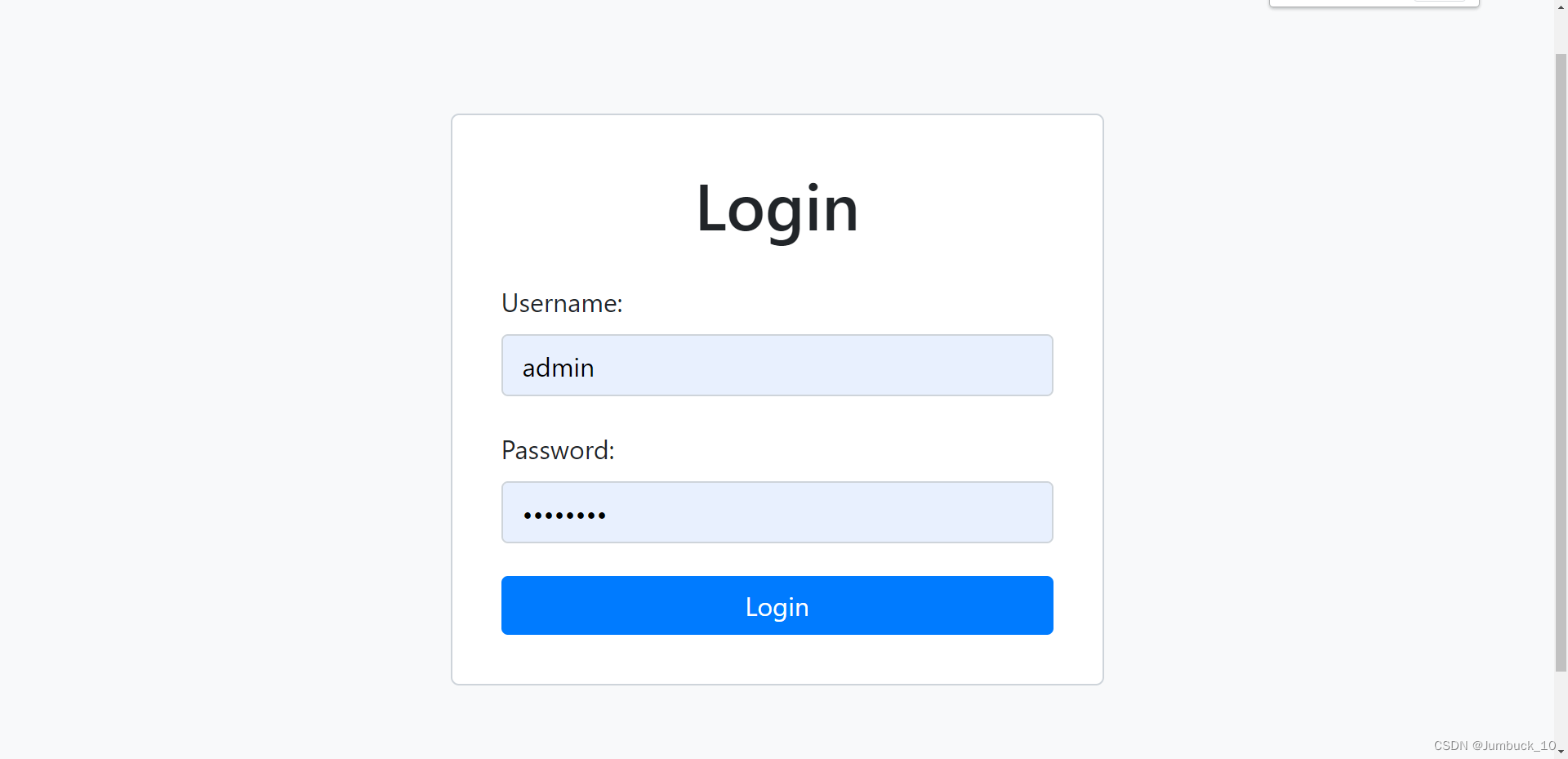
图3、登录界面
二、Django部分
1. 创建Django项目
新建一个文件夹,cmd进入该目录,输入以下命令
django-admin startproject flower_reco
2. 创建APP
在项目根目录中输入命令
python manage.py startapp login
上述命令是创建一个名为login的的App,博主认为App可以理解为项目中的模块,需要后端实现什么功能就可以添加一个对应的模块,博主这里创建了login、recognition,分别实现登录和识别的功能。
注:下方为开启服务指令
python manage.py runserver
3. 编写路由
路由是后端接收请求的url,在Django服务器中,根据请求的url,做对应的后端逻辑处理。路由都写在urls文件里,它将浏览器输入的url映射到相应的业务处理逻辑也就是视图(views.py)。简单的urls编写方法如下图:

为了让urls更清晰明确,django的处理方式如上,在各个App中编写自己的url,然后再主App也就是入口文件中使用include把子App中的url包含进来
4. 编写login请求的视图函数
路由转发用户请求到视图函数。视图函数处理用户请求,也就是编写业务处理逻辑,一般都在views.py文件里。
下面是相应登录请求的views:
from django.shortcuts import render
import os
from django.shortcuts import render
from django.conf import settings
import torch
from torchvision import transforms
from PIL import Image
def login(request):
if request.method == 'POST':
username = request.POST['username']
password = request.POST['password']
# 检查用户名和密码是否匹配
if username == 'admin' and password == 'password':
return render(request, 'success.html', {'username': username})
else:
return render(request, 'login.html', {'error': 'Invalid credentials'})
return render(request, 'login.html')
由于这里做的处理很简单,博主就不过多赘述了。
4.2 路由(urls)和视图(views)的对应关系
细心的读者可能会发现,urls中的path其实就是指向上述login文件的,明白了django中的这种一一对应的关系,编写起来就会很有条理。

5. 编写处理花分类请求的视图函数
处理花分类请求的视图函数步骤大致如下:
- 获取前端传过来的图片文件
- 将文件保存到本地临时文件
- 调用花分类模型进行推断
- 得到模型返回的数据
- 删除临时文件
实现代码如下:
from django.shortcuts import render
from models import predictImage
from django.http import JsonResponse
import tempfile
import os
def image_recognition(request):
if request.method == 'POST':
# 获取上传的图片文件
image_file = request.FILES.get('image')
# 将文件保存到本地临时文件
with tempfile.NamedTemporaryFile(delete=False) as temp_file:
temp_file.write(image_file.read())
temp_file_path = temp_file.name
# 处理图像文件
# 使用你的模型进行推断
prediction, confidence = predictImage.pred(temp_file_path) # 调用模型预测函数
# 删除临时文件
os.remove(temp_file_path)
conf = confidence.split("(")
confidence = conf[1]
conf = confidence.split(")")
confidence = conf[0]
return JsonResponse({'prediction': prediction, 'confidence': confidence,'introduction':introduction})
return render(request, 'success.html') # 返回前端界面
三、深度学习模型部分
深度学习模型需要提前找好网络,得到训练权重并全部保存到创建的django项目目录下,这是一个小坑,如果放在django项目外的话,启动项目后可能会找不到项目外的一些文件,导致预测无法进行。
模型选用经典的AlenNet,这部分就不过多赘述了,已经有很多开源资料可以使用,博主这里只是对处理结果进行了一些定制化的处理,返回的不是原来代码中所有的数据,而是返回置信度最大的花信息。处理方式如下:
confMax = 0
maxIndex = 0
for i in range(len(predict)):
if predict[i] > confMax:
confMax = predict[i]
maxIndex = i
return str(class_indict[str(maxIndex)]),str(predict[maxIndex])
四、前端部分
由于笔者不是很擅长前端,所以踩了很多坑。
1. 上传图片部分
上传图片识别部分,首先是要拿到输入框中的文件,注意这里获取的并不是网页保存的一长串图像字符,而是封装好的文件,获取方式如下:
var fileInput = document.getElementById('image-upload');
var file = fileInput.files[0];
// 创建一个FormData对象,并将图像文件添加到其中
var formData = new FormData();
formData.append('image', file);
····························
中间代码省略一些
····························
xhr.send(formData);
2. 解决发送请求后页面跳转的问题
在使用令牌进行请求后端后,页面会发生跳转,解决这个问题的方法也很简单,在点击请求的处理第一行加入如下代码,阻止页面跳转。
event.preventDefault();
3. 视频识别获取某一帧的图像
代码如下:
// 创建一个 Canvas 元素并设置其尺寸与视频帧相同
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
canvas.width = videoPreview.videoWidth;
canvas.height = videoPreview.videoHeight;
// 在 Canvas 上绘制视频帧
context.drawImage(videoPreview, 0, 0, canvas.width, canvas.height);
// 将 Canvas 的图像数据转换为文件对象
canvas.toBlob(function(blob) {
// 创建一个 File 对象,并将其添加到 FormData
const file = new File([blob], 'video_frame.jpg', { type: 'image/jpeg' });
const formData = new FormData();
formData.append('image', file);
五、代码获取

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









