







apache历史项目下载地址:http://archive.apache.org/dist/
准备
1. 3台虚拟机:
192.168.31.110
192.168.31.111
192.168.31.1122. 安装jdk1.7 64位
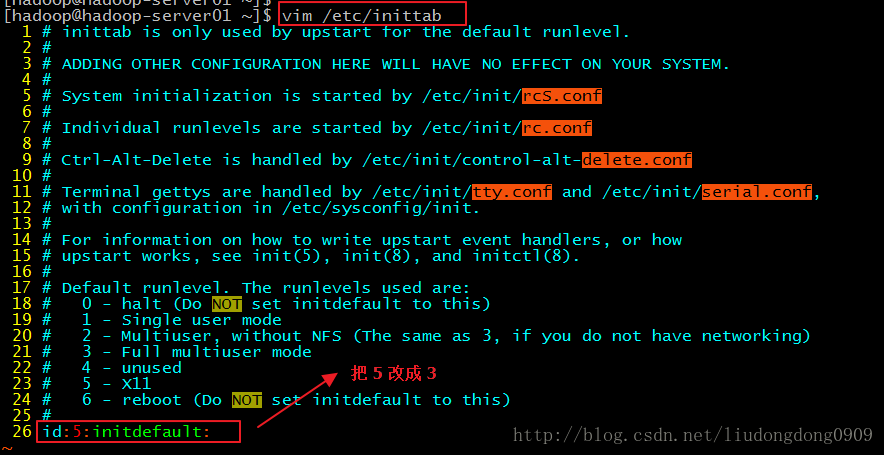
永久显示行号vim:

虚拟机命令行启动:
centos安装jdk :http://blog.csdn.net/liudongdong0909/article/details/51048788
3. 修改主机名和IP的映射关系:

(上图可以不用配置,个人爱好)

(三台机子相同)
4. 关闭防火墙
--查看防火墙状态
service iptables status
--关闭防火墙
service iptables stop
-- 查看防火墙开机启动状态
chkconfig iptables --list
-- 关闭防火墙开机启动
chkconfig iptables off
5. 创建一个 app 文件夹
[root@localhost /]# mkdir /home/hadoop/app -p
安装Hadoop
先上传hadoop的安装包到服务器 /home/hadoop/app
解压
[donggua@localhost /]$ tar -zxvf hadoop-2.4.1.tar.gz -C app/修改5个配置文件:
第一个:修改 hadoop-env.sh
cd /home/donggua/app/hadoop-2.4.1/etc/hadoop
vim hadoop-env.sh

export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/local/jdk
第二个:修改 core-site.xml
[donggua@localhost hadoop]$ vim core-site.xml
<configuration>
<!-- 指定Hadoop所使用的文件系统schema(URI),HDFS的 namenode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-server01:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/donggua/app/worktmp</value>
</property>
</configuration>

第三个:修改 hdfs-site.xml
[donggua@localhost hadoop]$ vim hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>

第四个:修改 mapred-site.xml
[donggua@localhost hadoop]$ mv mapred-site.xml.template mapred-site.xml
[donggua@localhost hadoop]$ vim mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

第五个:修改yarn-site.xml
[donggua@localhost hadoop]$ vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定yarn 的resource manager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-server01</value>
</property>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

将hadoop添加到环境变量
vim /etc/profile
#hadoop2.4.1
export HADOOP_HOME=/home/donggua/app/hadoop-2.4.1
export PATH=$HADOOP_HOME/bin:$PATH

远程复制 hadoop-2.4.1 文件夹到 其他连个机器
[root@localhost app]# scp -r hadoop-2.4.1/ hadoop-server02:/home/donggua/app/
[root@localhost app]# scp -r hadoop-2.4.1/ hadoop-server03:/home/donggua/app/
注意:
格式化 namenode
[root@localhost bin]# ./hadoop namenode -format

启动节点(多个节点多次启动)
hadoop-server01 :启动namenode
[root@localhost sbin]# ./hadoop-daemon.sh start namenode

hadoop-server02 : 启动datanode
[root@localhost sbin]# ./hadoop-daemon.sh start datanode

hadoop-server03 : 启动datanode
[root@hadoop-server03 sbin]# ./hadoop-daemon.sh start datanode

访问web页面
HDFS管理界面 : http://192.168.31.110:50070
设置 slaves
// 查看 salves.sh
[hadoop@hadoop-server01 sbin]$ vim slaves.sh
[hadoop@hadoop-server01 hadoop]$ pwd
/home/hadoop/app/hadoop-2.4.1/etc/hadoop
[root@localhost hadoop]# vim slaves
hadoop-server01
hadoop-server02
hadoop-server03配置SSH免登录
ssh-keygen
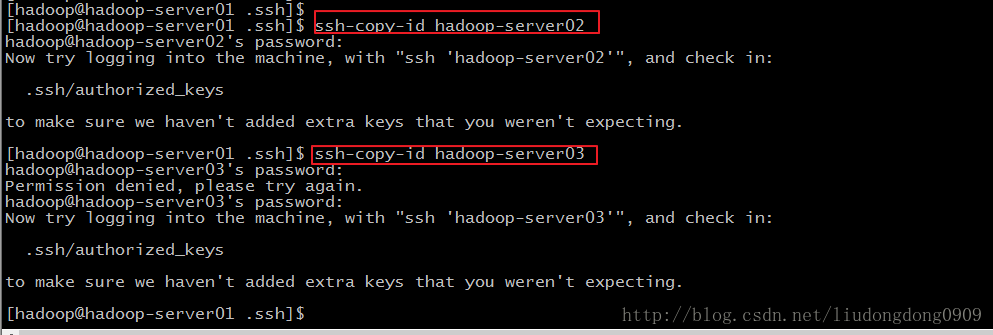
ssh-copy-id hadoop-server01
ssh-copy-id hadoop-server02
ssh-copy-id hadoop-server03
启动hadoop(多个节点一次启动)
启动hadoop
先启动HDFS
sbin/start-dfs.sh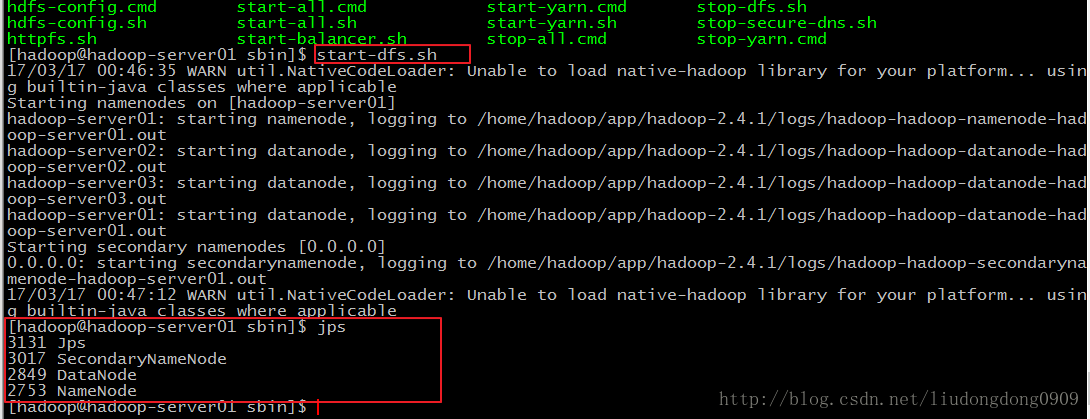
再启动YARN
sbin/start-yarn.sh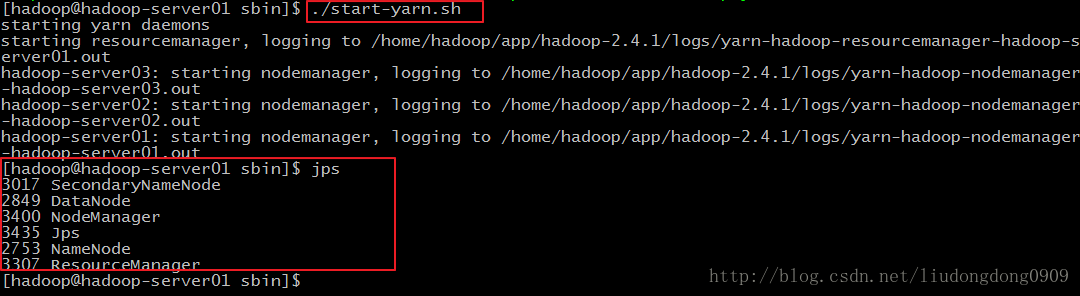
MR管理界面 : http://192.168.31.110:8088
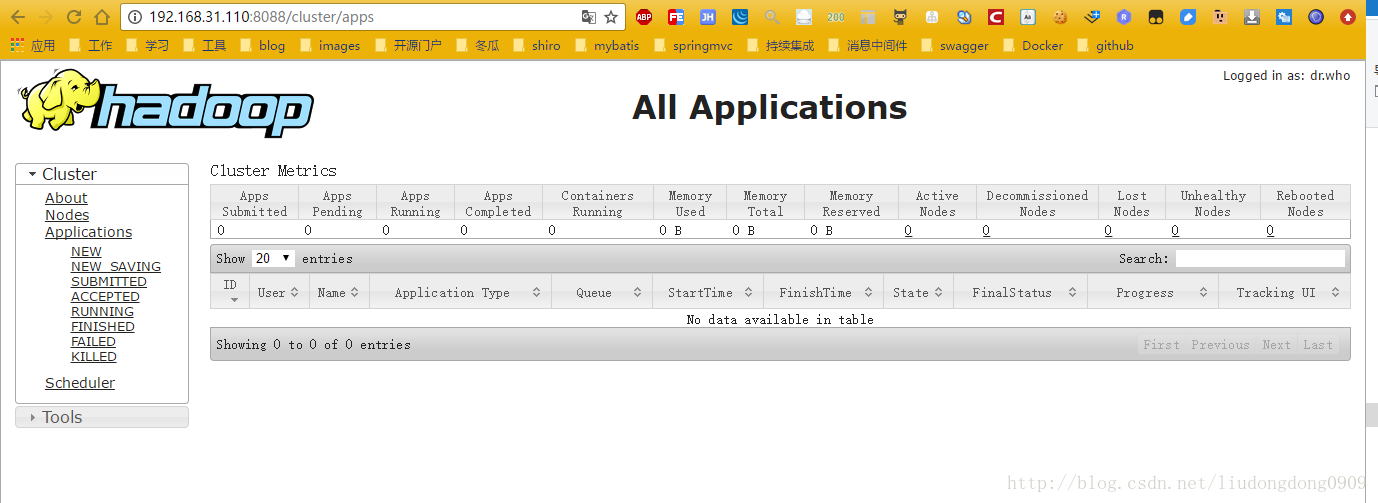
错误解决
第一个错误:
1.centos 虚拟机克隆硬盘后网卡无法启动的情况
用虚拟机安装了一个Centos系统,后来想用安装的vmdk文件重新克隆一个虚拟系统。clone成功后发现网卡无法启动成功,报错说:
Bringing up interface eth0: Device eth0 does not seem to be present, delaying initialization. [FAILED]
后来查找资料才发现,这是因为虚拟机非配给操作系统的虚拟网卡地址是不一样的。第一个系统的网卡地址记录在了/etc/udev/rules.d/70-persistent-net.rules,命名为eth0。新分配的系统的网卡地址也记录在了该文件当中,因此有了冲突。
解决方法:
1 修改/etc/udev/rules.d/70-persistent-net.rules文件,删除第一个网卡记录,并将第二个的NAME=”eth1”改为NAME=”eth0”
2 如果在/etc/sysconfig/network-scripts/ifcfg-eth0中有配置网卡信息的话,如:#HWADDR=”00:0C:29:C8:1A:92”,将其注释。
3重启系统。
第二个错误:
17/03/16 23:45:43 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [Java HotSpot(TM) 64-Bit Server VM warning: You have loaded library /home/hadoop/app/hadoop-2.4.1/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
hadoop-server01]
sed: -e expression #1, char 6: unknown option to `s'
Server: ssh: Could not resolve hostname Server: Name or service not known
You: ssh: Could not resolve hostname You: No address associated with hostname
disabled: ssh: Could not resolve hostname disabled: Name or service not known
warning:: ssh: Could not resolve hostname warning:: Name or service not known
VM: ssh: Could not resolve hostname VM: Name or service not known
to: ssh: Could not resolve hostname to: No address associated with hostname
have: ssh: Could not resolve hostname have: Name or service not known
-c: Unknown cipher type 'cd'
解决办法(方法二亲测可行,其他两个方法没有测试 不知道):
解决办法一:
hadoop@master~: sudo gedit ~/.bash_profile 然后输入如下内容并保存:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
解决办法二:
打开$HADOOP_HOME/etc/hadoop/hadoop-env.sh文件,输入如下内容并保存
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
解决办法三:
打开$HADOOP_HOME/etc/hadoop/yarn-env.sh,在任意位置输入如下内容
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
最后在运行$HADOOP_HOME/sbin/start-all.sh















 5081
5081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









