







 Google DatasetSearch利用schema.org/Dataset标准,整合多样化的数据集元数据,增强数据发现能力。通过协调元数据、连接重复数据集及利用Google知识图谱,DatasetSearch提升搜索体验,促进数据引用文化,支持开放数据生态系统。
Google DatasetSearch利用schema.org/Dataset标准,整合多样化的数据集元数据,增强数据发现能力。通过协调元数据、连接重复数据集及利用Google知识图谱,DatasetSearch提升搜索体验,促进数据引用文化,支持开放数据生态系统。
https://toolbox.google.com/datasetsearch
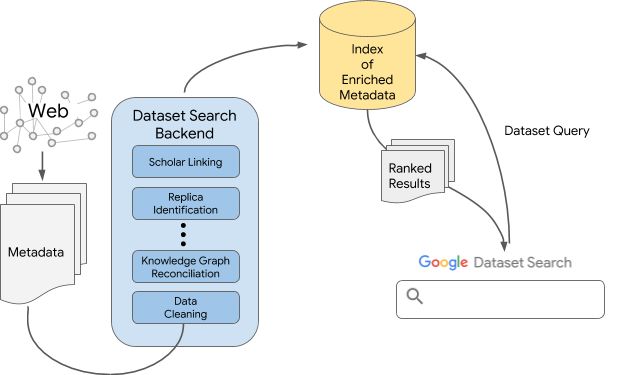
Google Dataset Search 高度依赖各种大小的数据集提供者,并使用开放的 schema.org/Dataset 标准在其网站上添加结构化的元数据。元数据指定了各个数据集的显著属性:名称和描述、空间和时间覆盖范围、来源信息等。Dataset Search 利用这些元数据,将其与 Google 上的其他可用资源连接起来(详情请见下图!),并为这个丰富的元数据语料库构建索引。构建好索引之后,我们就可以开始回应用户查询,并找出最符合查询的结果。
使用来自数据提供者的结构化元数据
在处理带有 schema.org/Dataset 标记的网页时,Google 的搜索引擎知道其中存在数据集元数据,并会处理此结构化元数据,以创建描述页面上每个标注数据集的 “记录”。由于使用 schema.org,开发者可以将此结构化信息嵌入到 HTML 中,并使信息语义对所有搜索引擎可见,而不影响网页的外观。
然而,无论 schema.org 的定义或指引有多精确(https://developers.google.com/search/docs/data-types/dataset),有些元数据还是不可避免地会不完整、存在错误或完全缺失。此外,某些字段之间的区别可能模糊不清:数据集存储区是数据集的发布者还是提供者?我们如何区分所引用的是描述数据集创建的科学论文,还是描述数据集使用的论文?事实上,许多此类问题经常会引发激烈的学术讨论(https://www.biorxiv.org/content/early/2017/10/09/097196)。
尽管存在这些问题,Dataset Search 还是必须在前端提供可预测的统一用户体验。因此,在某些情况下,我们转而使用更通用的字段名称(如 “提供者”)来显示来自多个其他字段的值(如 “发布者”、“创建者” 等)。在其他情况下,我们根本无法使用某些字段:如果数据集提供者在阐释某个特定字段时有各种各样的错误,我们会暂时绕过该字段,并与社区一起理清指引。在作出每个决定时,我们都会提出一个特定问题来帮助我们解决困难,即 “什么对数据发现最有助益?” 这种对正在处理的任务的关注,使有些问题比最初看起来更简单。
连接重复数据集
对于数据集,特别是热门数据集来说,在多个存储区中重复出现是很常见的事情。我们通过多种信号来确定两个数据集是否互相重复。例如,schema.org 可通过 schema.org/sameAs 明确指出两个数据集之间的联系,这是将不同重复内容关联起来并指向数据集规范来源的最佳方法。其他信号还包括两个数据集描述指向相同的规范页面,具有相同的数字对象识别码 (DOI),共享数据集的下载链接,或在其他元数据字段中有大量重叠。这些信号并非完全独立,因此我们将其结合起来,以获得两个数据集可能相同的最明显提示。
使用 “Google 知识图谱” 进行协调
“Google 知识图谱” 是一个强大的平台,其中描述和连接了有关许多实体的信息,包括出现在数据集元数据中的实体:提供数据集的机构、数据空间覆盖范围的位置和资助机构等。因此,我们尝试使用 “知识图谱” 中的条目来协调元数据字段中提及的信息。基于两个主要原因,我们能够以良好的精确度实现这种协调。首先,我们知道 “知识图谱” 中的条目类型和我们期望在元数据字段中显示的实体类型。因此,我们可以限制 “知识图谱” 中用于匹配特定元数据字段值的实体类型。例如,数据集的提供者应该与 “知识图谱” 中的机构实体匹配,而不应该与位置匹配。其次,网页本身的语境可以帮助减少选择的数量,这对于区分拥有相同首字母缩略词的机构特别有用。例如,首字母缩略词 CAMRA 可以代表 “Chilbolton Advanced Meteorological Radar”(奇尔波顿高级气象雷达)或“Campaign for Real Ale”(真麦酒运动组织)。如果使用来自网页的词条,当页面上出现 “云”、“水汽” 和 “水” 等词汇时,我们就会更容易确定 CAMRA 实际上是指奇尔波顿雷达。
这种协调带来改善用户搜索体验的诸多可能。例如,Dataset Search 可以使用与页面其他内容相同的语言来显示元数据的协调值,从而定位搜索结果。此外,它还可以使用同义词、纠正拼写错误、扩展首字母缩略词,或通过 “知识图谱” 中的其他关联进行查询扩展。
连接到其他 Google 资源
Google 有许多其他数据资源可用于增加数据集元数据,例如 “Google 学术搜索”。了解发布内容中参考和引用了哪些数据集有助于实现至少两个目的:
-
提供有关数据集重要性和知名度的有价值信号。
-
为数据集作者提供查看对其数据的引用和获得荣誉的简便方式。
实际上,我们希望突出显示使用数据的发布内容能够带来更健康的数据引用生态系统。目前,由于缺少描述用户如何引用数据的良好模型,我们到 “Google 学术搜索” 的链接还不太精确。我们尝试使用 DOI 以外的方式以提供稍好一些的覆盖范围,但会导致引用某个数据集的文章数量变得不太精确。我们希望能够在这个方面取得更多进展,以获得更高的精确度。
搜索和结果排序
当用户进行查询时,我们会搜索数据集语料库,而所采用的方式与 “Google 搜索” 搜索网页没有什么差别。与进行任何搜索一样,我们需要确定某个文档是否与查询相关,然后对相关文档进行排序。由于目前没有针对用户如何搜索数据集的大规模研究,作为首个近似研究,我们采用了 Google 网页排序方法。然而,数据集排序与网页排序有所不同,因此我们添加了一些涉及元数据质量和引用等方面的额外信号。随着用户更频繁地使用 Dataset Search,以及我们更好地了解用户搜索数据集的方式,我们希望能够显著改善数据集排序的质量。
更好的开放数据生态系统
我们构建 Dataset Search 的目的是创建一个有助于数据发现的工具。由于 Dataset Search 仅能达到与其支持的开放数据生态系统一样好的水平,所以我们有意让此工具的标记决策依赖开放标准(schema.org、W3C DCAT、JSON-LD 等)。因此,Google Dataset Search 旨在通过鼓励以下做法,支持强大的开放数据生态系统:
-
广泛采用描述已发布数据的开放元数据格式。
-
进一步开发描述更多数据类型和更多细节的开放元数据格式。
-
打造类似于引用研究出版物的数据引用文化,给予数据创建者和发布者应得的荣誉。
-
开发利用此元数据的工具,以实现更多数据发现或更好的数据利用。
开放元数据标准的更广泛采用加上 Dataset Search 的持续发展(希望能加入其他工具),应该会打造出更健康的开放数据生态系统。而在这个系统中,数据是研究的第一类对象。
1.对于数据分析师来说有了这个工具不用花大量的时间用在找数据上,节省了大量的时间用在更有意义的分析上面。
2.对于产品经理、运营岗位的人来说也是一个非常有用的工具,产品经理、运营岗位的人其实很多时候也是需要一些宏观的数据去进行产品判断,比方说根据某个地方的消费水平去判断某个价格的产品是否适合在这个地区上线。
3.对于爬虫工程师来说,在做爬虫前先搜一下看看有没有自己想要的数据,这样就不需要重复「造轮子」了。
4.对于普通人来说,在这个数据说话的时代里,大家都相信一个数据。这个数据集合搜索引擎无疑帮助大家一个大忙,想要数据证明自己观点?搜一搜就能搜到了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









