






PostgreSQL 数据查询优化一般都是从,语句的撰写方式,或者添加索引来进行优化。对于复杂的业务来说,是一个好办法,但对于简单的查询来说,优化起来就没有什么可以插手的方式了。
从另一个思路考虑,数据的查询一般都会牵扯与磁盘的交互,如果将数据在查询之前尽可能的拿到内存中进行处理,速度应该是比到查询的时候在到内存中拿取更好。
一种方式是提权预读,将需要的数据通过预查询的方式将他提到缓冲中,PG有一个工具通过另一种方式将表提到OS cache中,通过这样的方式来提高读取的数据的速度。

创建一个表,在表中插入100万的数据。我们通过普通查询看看如果进行select count(*) from test; 的结果是多少。
我们通过下面的案例来去看如何从底层来加速数据的加载
select * from pgfadvise_willneed('test');
select * from pgfincore('test');
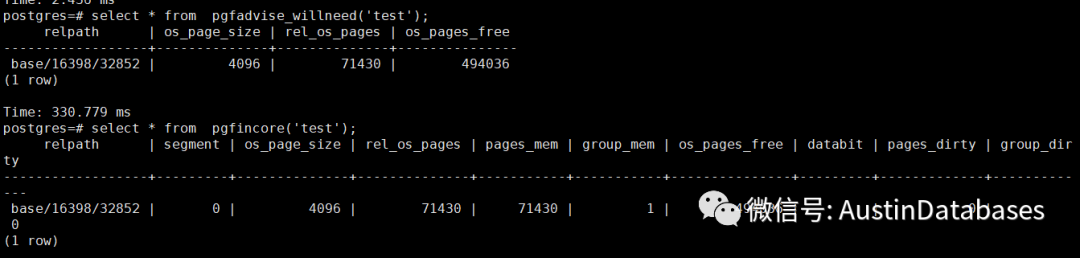
这两个命令是将test 表加入到 OS CACHE 层面, 然后我们查看数据表是否加载到OS CACHE 页面中。
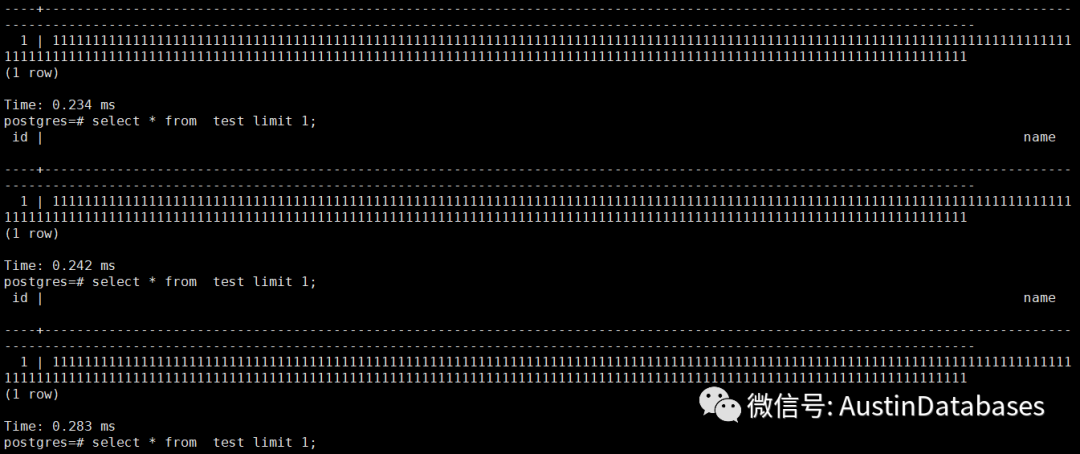
然后我们随便查询, 95%以上全表扫描方式都是在 3毫秒以内
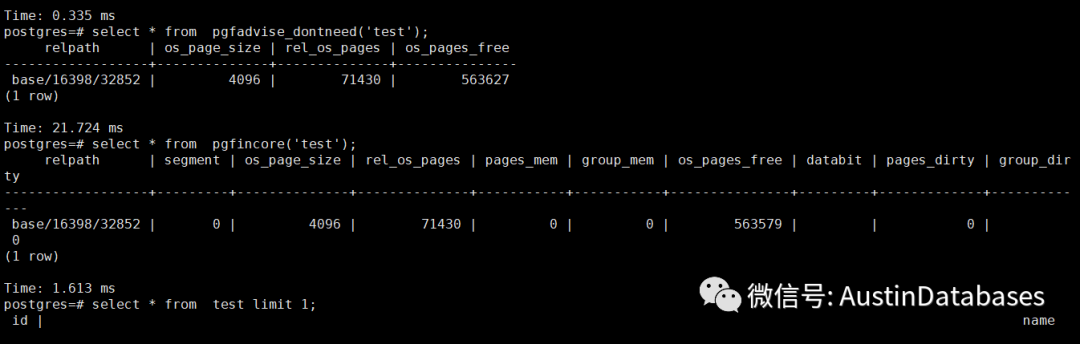
我们将test 表从OS cache中卸载出去
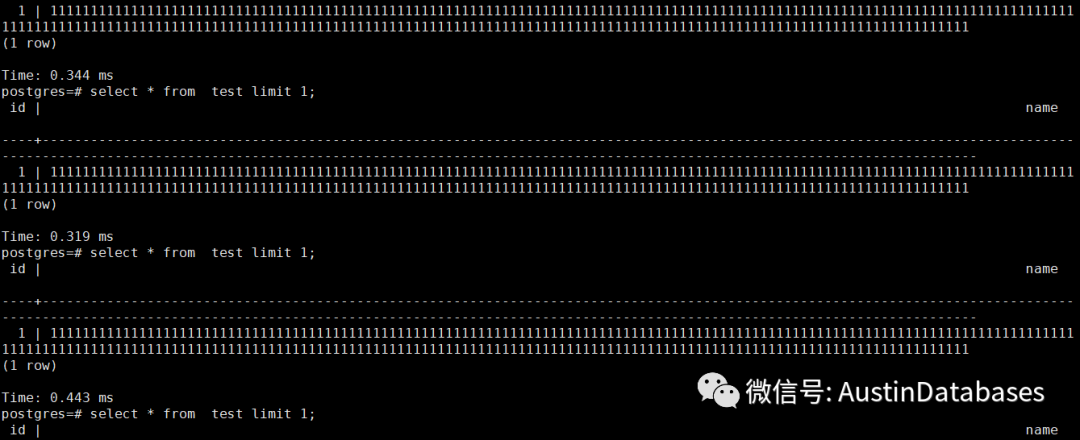
50% 以上的查询均超过3毫秒
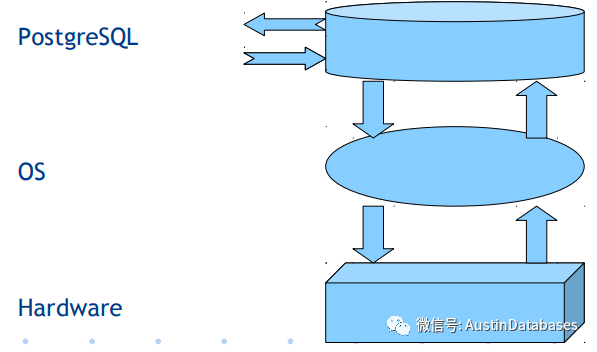
实际上POSTGRESQL 读取数据的方式是下图的方式,中间有一层LINUX的 CACHE作为2级缓冲,这也是SHARE BUFFER 设置中和其他数据库不大一样的地方,不会设置的比较满,而是在内存的25%左右。剩下的需要将他给LINUX 的OS CACHE 让他来从 disk中先加载数据。
上面的命令主要的功能就是提前将所选择的表加载到OS CACHE 中,提高访问的速度,尤其对于全表扫描和count的操作是非常有利的。
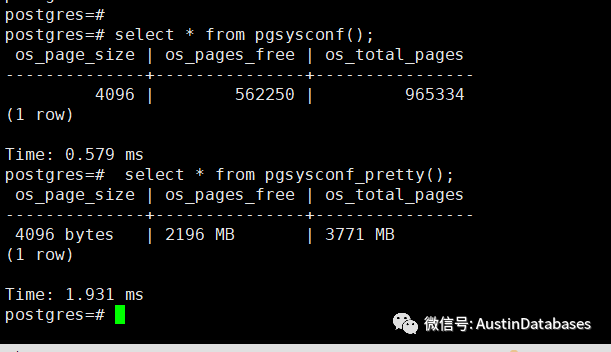
同时组件中的命令pgsysconf() 可以查看整体的OS 的数据页面的使用情况。
插件是 2象限公司开发并维护的, 对于频繁简单的语句查询有明显的性能提升。
至于安装这里就不重复了,之前有介绍相关安装的文字,直接对下载的文件进行make 即可,并且针对数据库 创建 extension 就可以马上使用,OS cache 余热加载的功能了。















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









