







postgresql 的逻辑复制槽估计是一个被说烂的话题,但如果你是在大批量的使用逻辑复制槽作为数据的同步和复制的功能,那这就是一个另外的话题了。
我们从什么是逻辑复制槽,到我们应该什么时候在什么情况下,怎么使用复制槽,到如何检测复制槽的状态和怎么监控他来说说复制槽的问题。
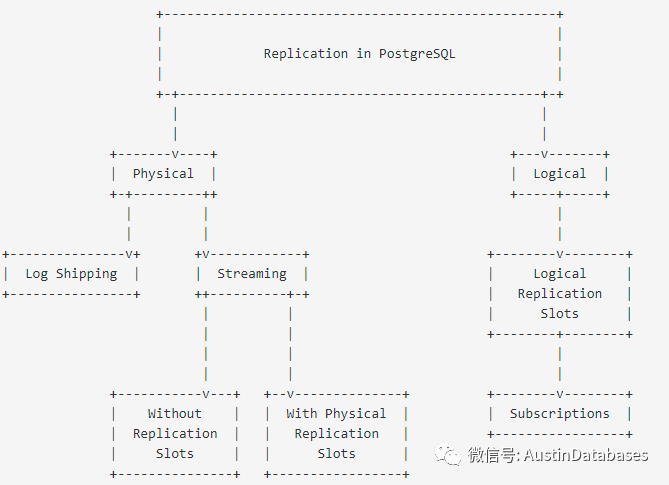
1 什么用户可以建立逻辑复制槽
首先针对逻辑复制的创建者比如有replication的权限,或者一个超级用户,并且针对这些要进行逻辑复制的表来看,我们必须针对这些表有OWNER的权限,如果你在操作的时候,变动了本属于这个表的一些安全策略,那么将会导致复制停止。同时这些用户必须被甚至在你的pg_hba.conf 的访问权限控制列表中。
针对建立一个发布的情况,用户必须有create 和 select 的权限, 当创建一个订阅的时候,则必须具有superuser的权限。所以最简单的情况是,创建一个逻辑复制以及相关的设置,你最好是superuser的权利。
2 逻辑复制是否可以级联
是的逻辑复制是可以通过一级套一级的方式来进行数据的传送,假如我们有三个POSTGRESQL ,那么我们A 为发布,B 为订阅, B 同时为发布 C 为订阅,这样的设计是可以的。
3 逻辑复制到底要解决什么问题
1 发送增量数据到订阅的地方,类似处理DML 操作传递的工作
2 汇聚不同的数据库的表到一个数据库中进行几种处理
3 对于不同版本的数据库的数据进行汇聚,或升级数据库版本
4 不同平台的数据汇聚,如WINDOWS 到 LINUX 的平台
5 针对安全的问题,将不同的表汇聚到一个位置,来控制权限
6 提供比物理复制更细致的粒度,将表作为一个维度进行数据的复制对象使用
7 CDC 数据收集,数据变更的支持
4 基于逻辑复制中的逻辑复制槽对数据库的要求也有一些
1 max_replication_slots = 10 复制槽的数量
2 hot_standby = on
3 wal_level = logical 复制中的 wal 等级必须是 logical
4 hot_standby_feedback = on 数据接收端需要进行回馈
5 max_wal_senders = 10 最大的 wal 的发送者
其中 3 wal _level 是必须的,否则逻辑复制是无法进行工作的,逻辑复制槽的数量也需要注意,否则超过你最大的数据量,无法建立逻辑复制槽。
5 效率与表需求
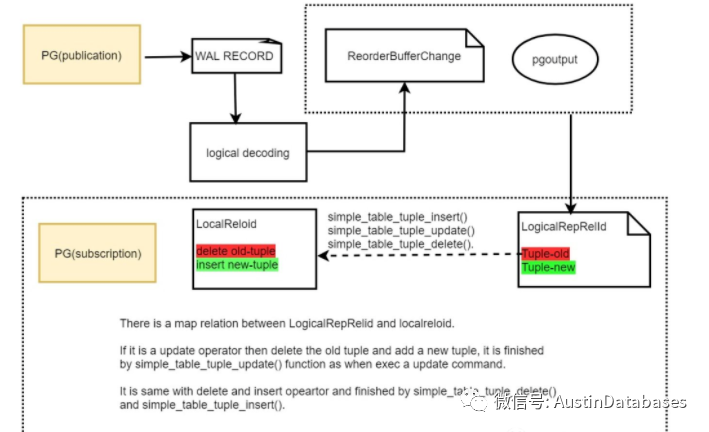
逻辑复制采用的复制的方式和我们的物理的复制方式是不同的,采用的方式是通过逻辑的模块对WAL 日志进行解析,并且将结果存储为堆表的数据,并将这些数据tongguopgoutput plugin 将这些结果进行过滤(对于数据DML操作进行过滤),过滤出 insert delete update , 最终将这些操作重新在目的端再次操作一遍 ,所以逻辑复制的效率对比物理复制是低的,操作的方式类似MYSQL 的binlog 中的数据日志发送,接受,在解析后重新执行的过程。所以逻辑复制中也有 sync work , apply work 这两个 worker 是异步的。
6 逻辑复制槽的理解
逻辑复制中重要的一个问题是数据的顺序,数据操作的顺序是被通过管道进行发送的,一个数据库中的所有操作都是有序的,每一个复制槽有一个唯一的标识,插槽源端记录本身发送数据的位置,源端记录接受到源端槽发来数据库的LSN ,在这样的情况下如果源端出现问题,如果出现重发的情况,目的端也有相关的记录,将重复的数据剥离不在重复进行执行。不同的复制槽在同一个数据库中可以针对不同的数据的消费者和订阅者。可以通过逻辑复制槽将这些订阅进行分离。
7 逻辑复制的概念
1 Publication : 在一个数据库中宏定义一组需要监听 insert ,delete, update ,truncate 操作的表的集合。
2 subscription : 通过在发布者上建立的复制槽,进行数据复制和数据接收的,如不指定逻辑复制槽则自行进行逻辑复制槽的初始化工作
。
在工作中,如果是第一次建立复制,则复制会将源端的数据通过copying 的方式发送给subscriber ,在基础数据完成后,会继续将变化的数据部分通过重放的方式在目的端操作。同时在工作中优于不能传输除DML操作以外的操作, 对原表进行DDL操作前应先对目的表进行DDL 操作,否则会导致复制停止。复制的过程中,对应的表应该有主键,因为复制的过程中,需要通过主键来判断复制中的重复复制数据的可能,并不在执行已经复制过的数据。
在目的端并未对对表有任何限制,如果手动修改目的端的表的数据,则也有可能产生数据复制冲突。
8 开始创建逻辑复制槽
创建逻辑复制槽是通过函数的方式来建立逻辑复制槽,下面的函数
pg_create_physical_replication_slot()就是创建逻辑复制槽的函数。
select pg_create_physical_replication_slot('table_slot');
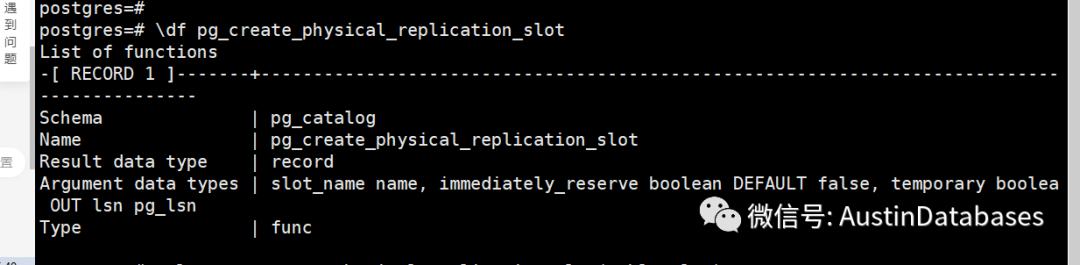
select * from pg_create_logical_replication_slot('table_slot','pgoutput');
查看当前的逻辑复制槽

对于逻辑复制槽的监控通过 pg_create_physical_replication_slot函数进行监控,其中主要的几个目标项
1 slot_name 复制槽的名字
2 plugin 复制槽上是否加有插件
3 slot_type 复制槽的类型是物理的还是逻辑的
4 datoid 物理复制槽此位置为空,逻辑复制槽此位置为所定位的数据库的OID
6 active 物理才在你查看的时候是否正在工作
8 xmin 在复制槽中的事务最老的transaction ID
9 catalog_xmin 这是最老的逻辑复制槽影响数据库本身的最大的事务的ID
10 restart_lsn 最老的WAL 日志的LSN 在复制槽中
12 wal_status 需要注意wal_status 这里如果出现了 unreserved lost 两个状态说明1 复制槽已经无法工作无法捕捉有效数据 2 复制槽已经弃用
13 safe_wal_size 这个部分说明可以写入槽的数据,如果这个位置为NULL 或者说明复制槽中已经无法写入数据了。
删除逻辑复制槽
select pg_drop_replication_slot('table_slot1');
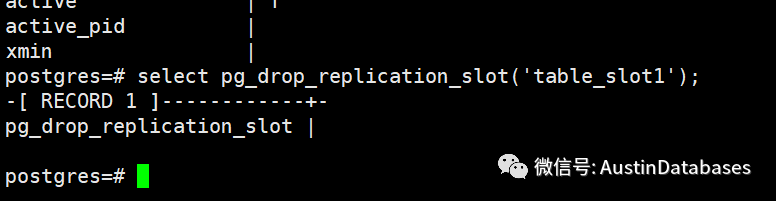
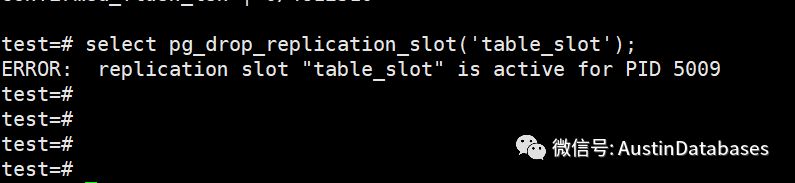
逻辑复制槽在使用的过程中是无法被删除的。
9 创建一个发布
在创建publication 时,需要注意几点
1 创建 publication 是可以针对表进行添加的,也可以设置随时添加的表就包含在publication中。
2 创建的publication 是可以针对操作进行选择性的操作传递和复制的。
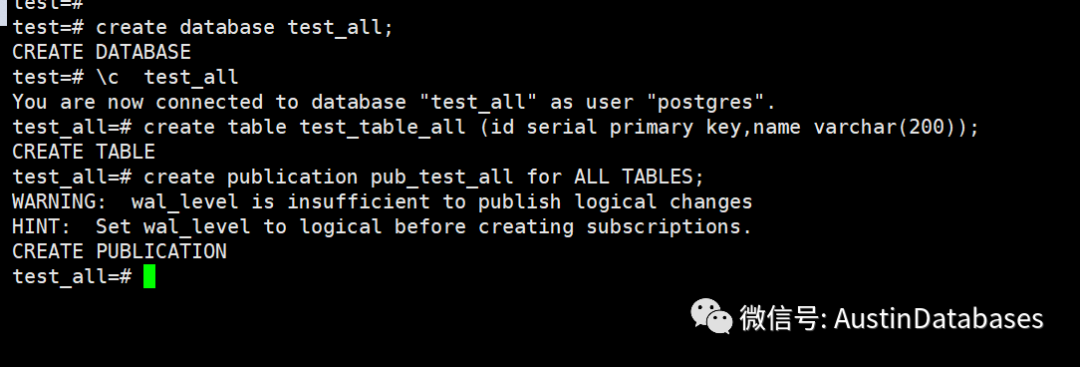
下面我在一个数据库中创建一个表,并且在其中创建一个publication
create databae test;
\c test
create table test (id serial primary key, name varchar(200));
create publication pub_test for table test with (publish = 'insert,update,delete');

create database test_all;
\c test_all
create table test_table_all (id serial primary key,name varchar(200));
create publication pub_test_all for ALL TABLES;
select current_database(),pgtab.tablename,pgpub.pubname,pgpub.puballtables,pgpub.pubinsert,pgpub.pubupdate,pgpub.pubdelete,pgpub.pubtruncate
from pg_publication as pgpub
inner join pg_publication_tables as pgtab on pgpub.pubname = pgtab.pubname;
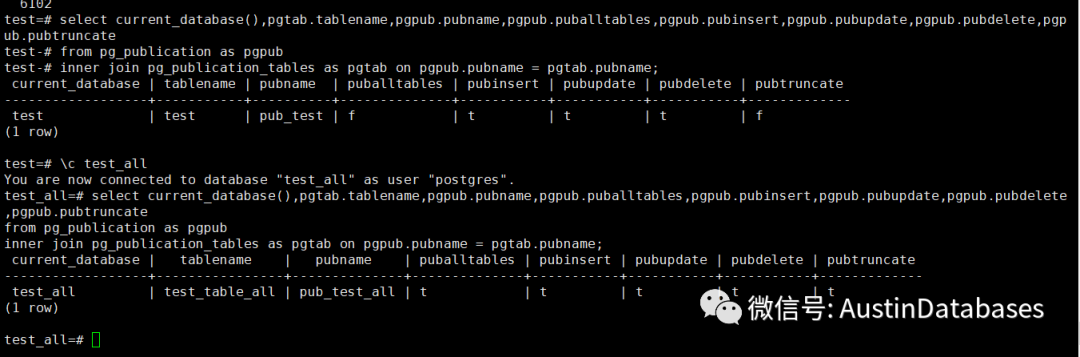
分析当前的postgresql中各个数据库的publication包含的表以及表的发布状态。
10 创建一个基于现有复制槽的subscription
一个逻辑复制中在创建完复制槽,publication 后,需要操作的就是在目的的机器上创建一个subscription, 并且利用现有的复制槽。
1 在目的的机器上配置 .pgpass 密码文件,其中写入源端的服务器的地址,数据库名以及用户名密码,另外文件必须是600的权限
2 在目的库建立同样的数据库名,表名以及表结构。
3 在目的数据库中运行建立subscription
CREATE SUBSCRIPTION mysub CONNECTION 'host=192.168.198.100 port=5432 user=admin dbname=test'
PUBLICATION pub_test with (create_slot = false,slot_name = table_slot);

select * from pg_subscription; 通过 pg_subscription 来监控当前数据库中创建的 subscription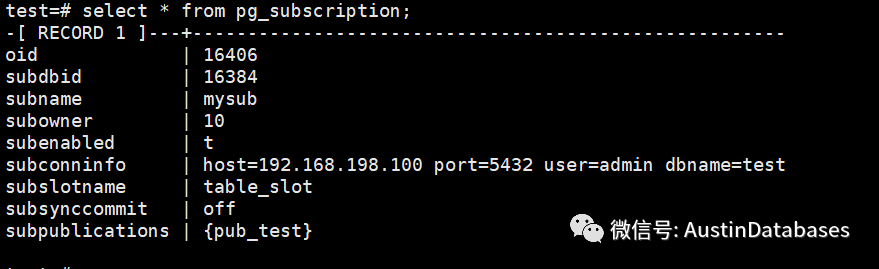
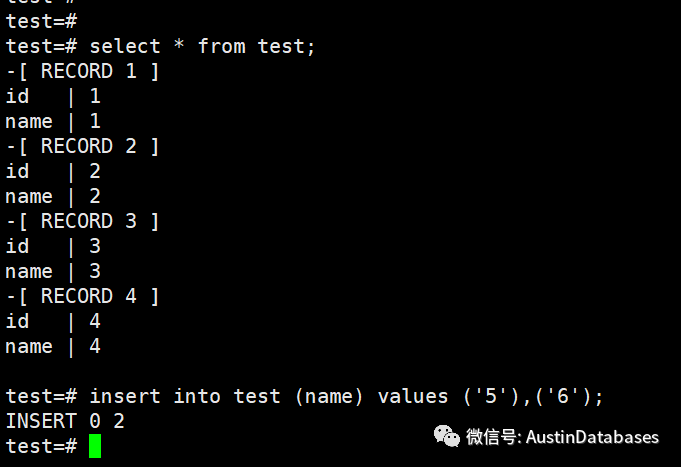
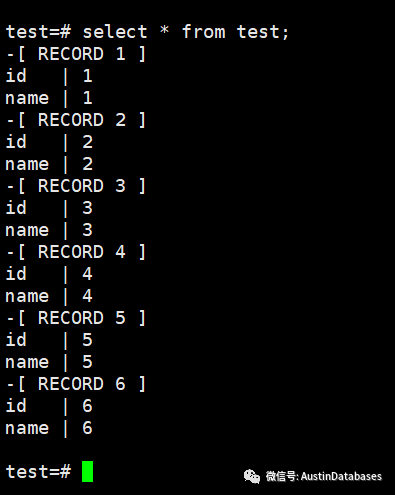
此时在主库输入数据,从库就可以接受数据。
主库
从库
11 监控逻辑复制的状态
通过监控复制的中已经在本地写入的LSN 与 目的端已经接受的 LSN 两个事务的对比,通过pg_wal_lsn_diff来计算之间的查询,表达了Byte
select pg_wal_lsn_diff((select flush_lsn from pg_stat_replication),(select confirmed_flush_lsn from pg_replication_slots)) as delay_Byte;

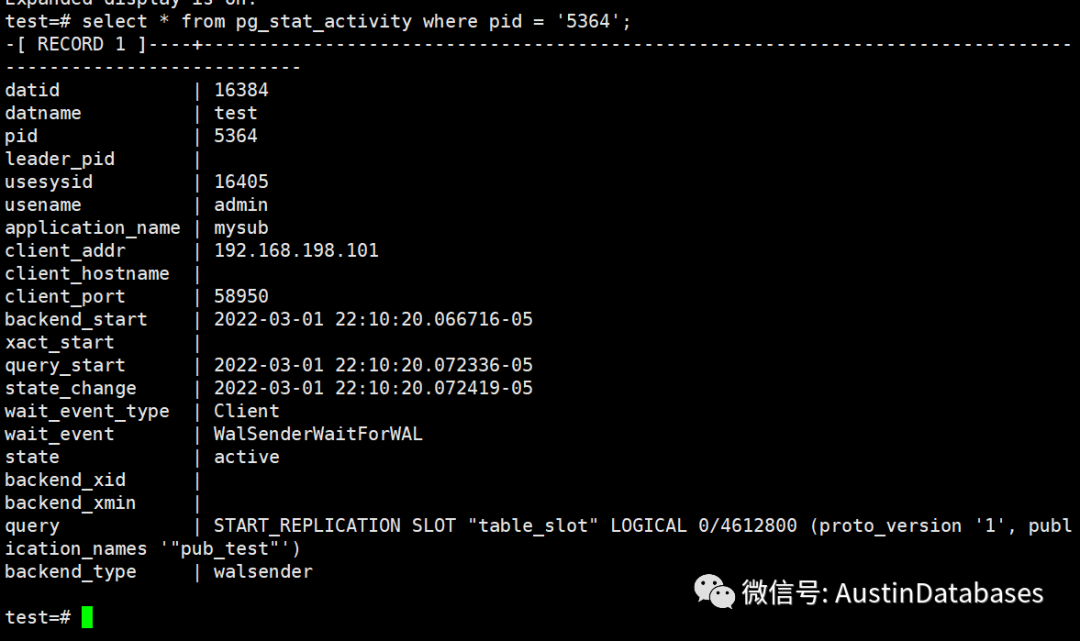
从上图中发现源于目的之间传输的差距。通过持续监控可以发现某些问题,如之间的差异越来越大,说明可能复制中的传输出现问题,需要注意,如果不解决,很有可能导致主库的磁盘空间被无法消费的WAL 日志挤占最终导致主库挂掉。
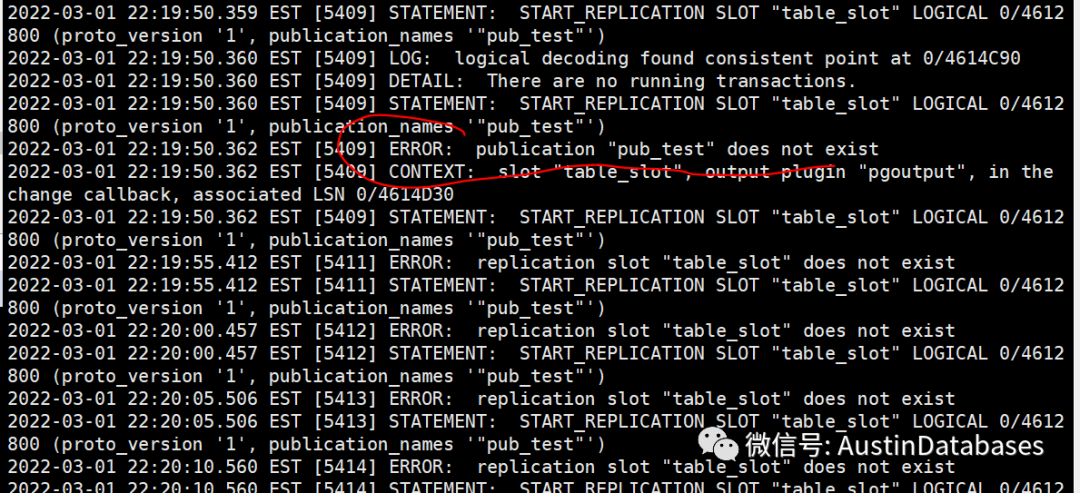
另还有一些问题,如逻辑复制中数据接收端根本就不是PG,而是其他的模拟成PG的消费端,此时这个模拟端出现问题,如网络问题等导致消费数据与数据的产生不成比例,也会造成数据的堆积在WAL日志中,并且此时是无法删除逻辑复制槽的, 如果此时是在是无法通过其他手段删除subscription, 可以直接在紧急的情况下删除publication , 停止复制。















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









