






开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, Sql Server等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,(共2270人左右 1 + 2 + 3 + 4 +5) 新人奖直接分配到5群,5群超过300 已建立6群,另欢迎 OpenGauss 的技术人员加入。

在数据库查询中,无论是NOSQL,还是RDBMS,对于分组查询中的一个问题如在全表的数据中,寻找最大或者最小等数据的,在撰写上基本上我们认为是一定要走全表扫描,性能是极差的。我们以下面的这个例子为
test=# CREATE TABLE test (
sensor_id serial primary key,
datetime_z timestamptz,
num int,
measurement numeric
);
CREATE TABLE
test=# INSERT INTO test (datetime_z,num,measurement) SELECT x, y, random() * 10000
FROM generate_series('2025-01-01',
'2025-01-06',
'1 second'::interval) AS x,
generate_series(1, 20) AS y
ORDER BY random();
INSERT 0 8640020
test=#我们先产生一些数据,如下面的这样的数据
test=# select * from test limit 100;
sensor_id | datetime_z | num | measurement
-----------+------------------------+-----+----------------------
1 | 2025-01-02 19:20:23+00 | 7 | 0.000471084202757766
2 | 2025-01-03 07:52:13+00 | 12 | 0.000842286522750868
3 | 2025-01-02 21:37:53+00 | 19 | 0.00107103788282714
4 | 2025-01-01 09:27:44+00 | 8 | 0.00570652427533958
5 | 2025-01-04 21:41:48+00 | 15 | 0.0061040593646311
6 | 2025-01-05 17:38:42+00 | 19 | 0.00944912972977718
7 | 2025-01-04 04:18:06+00 | 14 | 0.00958140051299239
8 | 2025-01-01 14:49:09+00 | 6 | 0.00976847293054917
9 | 2025-01-04 21:15:55+00 | 11 | 0.0121830278287938
10 | 2025-01-02 21:07:22+00 | 15 | 0.0125664628058964
11 | 2025-01-04 07:27:27+00 | 17 | 0.013415268285133
12 | 2025-01-05 23:06:05+00 | 7 | 0.0143803294139211
13 | 2025-01-03 12:01:46+00 | 6 | 0.017007407975278
14 | 2025-01-04 14:24:31+00 | 9 | 0.0184721889051609
15 | 2025-01-02 17:31:37+00 | 17 | 0.0187292971576269
16 | 2025-01-05 23:33:24+00 | 2 | 0.0206032024063774
17 | 2025-01-02 22:18:22+00 | 1 | 0.0208605214124802
18 | 2025-01-01 23:43:02+00 | 7 | 0.0210473140738188
19 | 2025-01-01 06:57:02+00 | 3 | 0.0219787968758212
20 | 2025-01-04 09:38:41+00 | 6 | 0.0223137095889392
21 | 2025-01-04 08:56:04+00 | 10 | 0.0232475786421382
22 | 2025-01-04 23:18:53+00 | 8 | 0.023416246062169
23 | 2025-01-05 10:48:19+00 | 19 | 0.0279596807217786
24 | 2025-01-04 17:02:34+00 | 5 | 0.0296570113778039
25 | 2025-01-03 18:25:47+00 | 6 | 0.0320354009697432
26 | 2025-01-04 19:23:54+00 | 5 | 0.0338074071248862
27 | 2025-01-02 16:19:15+00 | 17 | 0.0338554437795402
28 | 2025-01-04 06:15:31+00 | 15 | 0.0364875569158762根据这些数据,我们提出需求,我们需要在这些数据中查找到,以mum字段为分组的,其中measurement 中最大的数。
那么一般我们怎么来写这个SQL ,那么我们的SQL可以写成如下的方式,select max(measurement),num from test group by num;
test=# select max(measurement),num from test group by num;
max | num
------------------+-----
9999.96862925846 | 1
9999.99688317849 | 2
9999.98868619483 | 3
9999.99081696655 | 4
9999.96824440433 | 5
9999.95991107692 | 6
9999.97899297738 | 7
9999.98890709368 | 8
9999.98517373538 | 9
9999.95235627681 | 10
9999.9940516991 | 11
9999.97450516039 | 12
9999.98790562357 | 13
9999.99934434015 | 14
9999.98130126717 | 15
9999.9809697677 | 16
9999.99441065245 | 17
9999.98693453146 | 18
9999.99931832066 | 19
9999.9999947002 | 20
(20 rows)
Time: 1321.710 ms (00:01.322)那么具体的SQL的执行计划是怎样的
select max(measurement),num from test group by num;test=# explain (analyze) select max(measurement),num from test group by num;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
-----------
Finalize GroupAggregate (cost=118609.56..118614.62 rows=20 width=36) (actual time=1614.494..1635.016 rows=20 loops=1)
Group Key: num
-> Gather Merge (cost=118609.56..118614.22 rows=40 width=36) (actual time=1614.476..1634.972 rows=60 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=117609.53..117609.58 rows=20 width=36) (actual time=1597.325..1597.330 rows=20 loops=3)
Sort Key: num
Sort Method: quicksort Memory: 26kB
Worker 0: Sort Method: quicksort Memory: 26kB
Worker 1: Sort Method: quicksort Memory: 26kB
-> Partial HashAggregate (cost=117608.90..117609.10 rows=20 width=36) (actual time=1597.249..1597.256 rows=20 loops=3)
Group Key: num
Batches: 1 Memory Usage: 24kB
Worker 0: Batches: 1 Memory Usage: 24kB
Worker 1: Batches: 1 Memory Usage: 24kB
-> Parallel Seq Scan on test (cost=0.00..99608.60 rows=3600060 width=15) (actual time=0.019..356.146 rows=288000
7 loops=3)
Planning Time: 0.134 ms
Execution Time: 1635.238 ms
(18 rows)
Time: 1636.838 ms (00:01.637)这里我们可以看到,首先我们启用了并行,并且也采用了hashaggregate的数据处理的方式.和parallel seq scan 的数据处理方式。
那么我们如果添加索引是否能解决或加速数据处理的速度,下面的截图,可以看到,即使添加了索引对于这样的查询也是无能为力的。
test=# create index idx_num_measurement on test (num,measurement);
CREATE INDEX
Time: 19520.139 ms (00:19.520)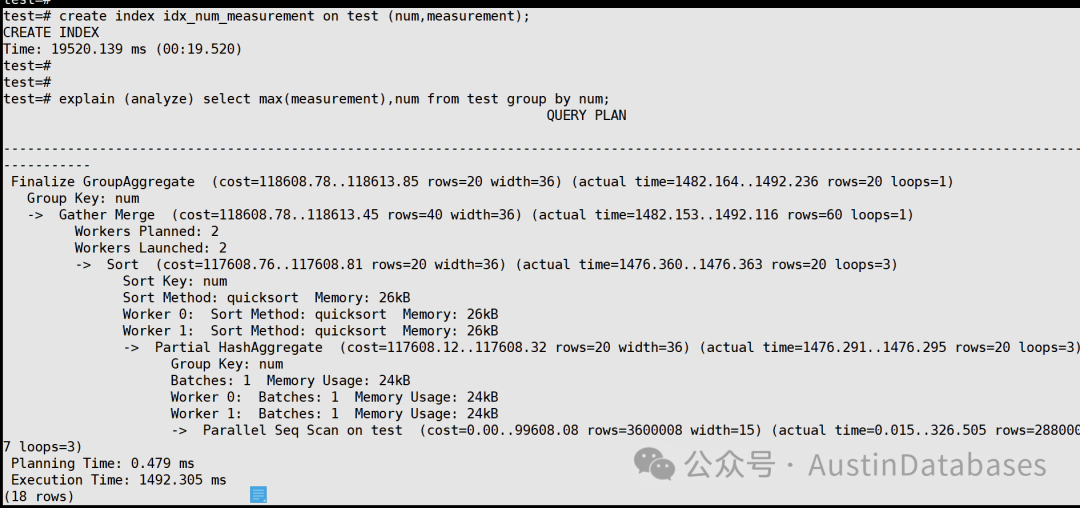
那么我们是不是可以变换一个想法,这个方法就是找规律,通过人为的找到分组查询中的规律,比如这里查询里面的规律是num,num在这里如果你去distinct 他,他只有20个值,那么也就是说我们查找的范围有,值的范围是1-20,那么我们如果缩小范围的或,索引就可以被用上的可能性就很大,果然我们改变了语句,我们不再进行分组,而是将分组变为了指定的值来进行查询,这样的方式下,我们获得速度将是非常快的,从之前得不知道,到我指定的等值进行MAX的数据查询。
test=# SELECT * FROM generate_series(1, 20) AS x,LATERAL (SELECT max(measurement) FROM test WHERE num = x) as subquery_z;
x | max
----+------------------
1 | 9999.96862925846
2 | 9999.99688317849
3 | 9999.98868619483
4 | 9999.99081696655
5 | 9999.96824440433
6 | 9999.95991107692
7 | 9999.97899297738
8 | 9999.98890709368
9 | 9999.98517373538
10 | 9999.95235627681
11 | 9999.9940516991
12 | 9999.97450516039
13 | 9999.98790562357
14 | 9999.99934434015
15 | 9999.98130126717
16 | 9999.9809697677
17 | 9999.99441065245
18 | 9999.98693453146
19 | 9999.99931832066
20 | 9999.9999947002
(20 rows)
Time: 2.918 ms
test=# explain (analyze) SELECT * FROM generate_series(1, 20) AS x,LATERAL (SELECT max(measurement) FROM test WHERE num = x) as subquery_z;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
--------------------------------
Nested Loop (cost=0.47..10.21 rows=20 width=36) (actual time=0.068..0.451 rows=20 loops=1)
-> Function Scan on generate_series x (cost=0.00..0.20 rows=20 width=4) (actual time=0.011..0.016 rows=20 loops=1)
-> Result (cost=0.47..0.48 rows=1 width=32) (actual time=0.021..0.021 rows=1 loops=20)
InitPlan 1 (returns $1)
-> Limit (cost=0.43..0.47 rows=1 width=11) (actual time=0.020..0.020 rows=1 loops=20)
-> Index Only Scan Backward using idx_num_measurement on test (cost=0.43..15312.45 rows=432001 width=11) (actual tim
e=0.019..0.019 rows=1 loops=20)
Index Cond: ((num = $0) AND (measurement IS NOT NULL))
Heap Fetches: 0
Planning Time: 0.273 ms
Execution Time: 0.501 ms
(10 rows)
Time: 2.031 ms最终我们的查询速度由上面展示 1.7秒,变为了0.002秒但查询的结果是一致的。
通过这样的查询的解决方式,我们可以将一些我们之前非常头疼的全表扫描式的分组查询的方式,转变为上面的等值查询模式来进行查询。
当然这样的方式也是有局限性的,但只要你肯想,会有更多的新颖的查询方式来去解决我们之前头疼的问题。
置顶
临时工访谈:无名氏意外到访-- 也祝你好运(管理者PUA DBA现场直播)
往期热门文章:
JunkFood读者说你文章不对,作者被鞭策后,DBA 开始研究JAVA程序锁
PostgreSQL PG_DUMP 工作失败了怎么回事及如何处理
临时工说:经济规律解读ORACLE 工资低 --读 Roger 数据库专栏
PostgreSQL 为什么也不建议 RR隔离级别,MySQL别笑
临时工访谈:OceanBase上海开大会,我们四个开小会 OB 国产数据库破局者
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
PolarDB for PostgreSQL 有意思吗?有意思呀
PostgreSQL 玩PG我们是认真的,vacuum 稳定性平台我们有了
临时工说:裁员裁到 DBA 咋办 临时工教你 套路1 2 3
临时工说:OceanBase 到访,果然数据库的世界很卷,没边
MONGODB ---- Austindatabases 历年文章合集
MYSQL --Austindatabases 历年文章合集
POSTGRESQL --Austindatabaes 历年文章整理
POLARDB -- Ausitndatabases 历年的文章集合
PostgreSQL 查询语句开发写不好是必然,不是PG的锅
SQL SERVER 如何实现UNDO REDO 和PostgreSQL 有近亲关系吗
MongoDB 2023纽约 MongoDB 大会 -- 我们怎么做的新一代引擎 SBE Mongodb 7.0双擎力量(译)
MongoDB 2023年度纽约 MongoDB 年度大会话题 -- MongoDB 数据模式与建模
MongoDB 会丢数据吗?在次补刀MongoDB 双机热备
临时工说:从人性的角度来分析为什么公司内MySQL 成为少数派,PolarDB 占领高处
PostgreSQL 字符集乌龙导致数据查询排序的问题,与 MySQL 稳定 "PG不稳定"
PostgreSQL Patroni 3.0 新功能规划 2023年 纽约PG 大会 (音译)
Austindatabases 公众号,主要围绕数据库技术(PostgreSQL, MySQL, Mongodb, Redis, SqlServer,PolarDB, Oceanbase 等)和职业发展,国外数据库大会音译,国外大型IT信息类网站文章翻译,等,希望能和您共同发展。
















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









