







1.为什么要引入FIRST集的概念?
- 因为有公共左因子的问题,公共左公因子是指在文法的产生式集合中,某个非终结符的多个候选式具有相同的前缀。
- 一般来说,公共左公因子的产生式为
A→αβ1│αβ2 - 如果有公共左因子的问题,那么只能采取试探的方法来分析每一个候选式,分析的过程很可能产生回溯,回溯分析法是一种不确定的方法。
- 若所有候选式都没有公共左因子就可以选择惟一匹配的候选式,不会产生(公共左公因子引起的)回溯。
- 为了消除回溯,对任何一个非终结符和当前的待匹配符号,期望
- 要么只有一个候选式可用
- 要么没有候选式可用
因此引入以下FIRST集合的概念:
- 对
α∈(VT⋃VN)∗
,有
FIRST(α)={a|α⟹∗a⋅⋅⋅,a∈VT}
特别地,若 α⟹∗ε ,则 ε∈FIRST(α)
因此对于每一文法符号
X∈VT⋃VN
,构造
FIRST(X)
的方法为:
使用下列规则,直至每个FIRST集不再增大为止:
- 若
X∈VT
,则
FIRST(X)={X}
(意思是如果
X
是终结符,则其
FIRST 集合为其自身); 若 X∈VN ,那么 X 的产生式分以下三种情况:
X→ε - 则 ε∈FIRST(X)
- X→a⋅⋅⋅
- 则 a∈FIRST(X)
- X→Y⋅⋅⋅ ,且 Y∈VN
则 FIRST(Y)–{ε}⊆FIRST(X)
特例: X→Y1Y2⋅⋅⋅Yi−1Yi⋅⋅⋅Yk
且 Y1,Y2,⋅⋅⋅Yi−1∈VN
Y1,Y2,⋅⋅⋅Yi−1⟹∗ε- 则 FIRST(Yj)–{ε}⊆FIRST(X)(1≤j≤i−1),FIRST(Yi)⊆FIRST(X)
特别地,当 Y1Y2⋅⋅⋅Yi−1Yi⋅⋅⋅Yk⟹∗ε
- 则 ε∈FIRST(X)
结论:针对无空产生式的文法G,同一非终结符的任两个产生式的右部符号串的FIRST集无交集,即可进行确定的自顶向下分析。
2.为什么要引入FOLLOW集的概念?
考虑文法G[S]:
S→aA
S→d
A→bAS
A→ε
求得各终结符和符号串的FIRST集合如下:
FIRST(S)={a,d}
FIRST(A)={b,ε}
FIRST(aA)={a}
FIRST(d)={d}
FIRST(bAS)={b}
FIRST(ε)={ε}
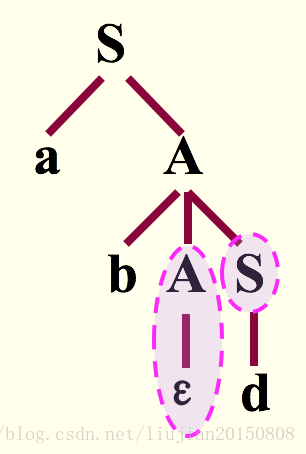
若输入串 W=abd ,则试图推导出abd串的推导过程为 S⇒aA⇒abAS⇒abS⇒abd
从以上推导过程中可以看到,在第2步到第3步的推导中,即 abAS⇒abS 时,因为当前面临的输入符号为 d ,但是最左非终结符A 的产生式右部的开始符号集都不包含 d ,但有ε ,因此对于 d 的匹配自然认为只能依赖于在可能的推导过程中A 的后面的符号,所以这时候选用产生式 A→ε 向下推导。而当前 A 后面的符号为S , S 产生式右部的开始符号集包含了d ,所以例子中可用 S→d 推导得到匹配。
语法树如下所示:
很显然,我们从以上叙述中可以得出:
当某一非终结符的产生式中含有空产生式时,它的非空产生式右部的开始符号集两两不相交,并与在推导过程中紧跟该非终结符右部可能出现的终结符集也不相交,则仍可构造确定的自顶向下分析。因此,引入了一个文法符号的后跟符号集合。
引入以下FOLLOW集的概念:- 对
A∈VN
,有
FOLLOW(A)={a|S⟹∗⋅⋅⋅Aa⋅⋅⋅,a∈VT}
若 S⟹∗⋅⋅⋅A ,则规定 #∈FOLLOW(A)
这里用#作为输入串的结束符,也称为输入串括号。
因此对于每一文法符号 A∈VN ,实际上求 FOLLOW(A)
就是考察A在产生式右端的出现情况,哪些终结符号可以跟随在A后面?使用下列规则,直至每个FOLLOW集不再增大为止:
- 首先,设S为文法的开始符号,把 {#} 加入 FOLLOW(S) 中(这里#为句子括号)
- 若 B→αAβ 是一个产生式,则 FIRST(β)−{ε}⊆FOLLOW(A)
- 如果
B→αA
或者
B→αAβ
且
β⟹∗ε
,则
FOLLOW(B)⊆FOLLOW(A)
- 解释: 因为在推导过程中可能出现如下的句型序列:
- S⇒∗⋅⋅⋅α1Bβ1⋅⋅⋅⇒⋅⋅⋅α1αAββ1⋅⋅⋅⇒⋅⋅⋅α1αAβ1⋅⋅⋅
例题:
A→BCc | gDB
B→bCDE | ε
C→DaB | ca
D→dD | ε
E→gAf | c非终结符 FIRST FOLLOW A {a, b, c, d, g} {f, #} B {b, ε } {a, c, d, g, f, #} C {a, c, d} {c, d, g} D {d, ε } {a, b, c, g, f, #} E {c, g} {a, c, d, g, f, #} 对于FIRST集合,解释其中的FIRST(A)的求解。
-
A→BCc
属于上述产生式的特例情况,很显然
B⇒∗ε,C⇏∗ε
,因此
(FIRST(B)−{ε})⋃FIRST(C)⊆FIRST(A) - A→gDB 属于上述产生式的第二种情况,因此 g∈FIRST(A)
- 最后得出:
FIRST(A)=(FIRST(B)−{ε})⋃FIRST(C)⋃{g} - 而 FIRST(B)={b,ε},FIRST(C)={a,c,d}
- 故 FIRST(A)={a,b,c,d,g}
对于FOLLOW集合,有如下的计算情况:
FOLLOW(A)=(FIRST(f)−{ε})⋃{#}={f,#}FOLLOW(B) =(FIRST(Cc)−{ε})⋃FOLLOW(A)⋃FOLLOW(C)={a,c,d}⋃{f,#}⋃FOLLOW(C)={a,c,d}⋃{f,#}⋃{c,d,g}={a,c,d,g,f,#}FOLLOW(C) =(FIRST(c)−{ε})⋃(FIRST(DE)−{ε})={c}⋃(FIRST(D)−{ε})⋃FIRST(E)={c,d,g}FOLLOW(D) =(FIRST(B)−{ε})⋃FOLLOW(A)⋃(FIRST(E)−{ε})⋃(FIRST(aB)−{ε})={b}⋃{f,#}⋃{c,g}⋃{a}={a,b,c,g,f,#}FOLLOW(E) =FOLLOW(B)={a,c,d,g,f,#}3.为什么要引入SELECT集的概念?
由于从2中我们得出结论:
当某一非终结符的产生式中含有空产生式时,它的非空产生式右部的开始符号集两两不相交,并与在推导过程中紧跟该非终结符右部可能出现的终结符集也不相交,则仍可构造确定的自顶向下分析。
因此当文法中含有形如:
A→αA→β
的产生式时,其中 A∈VN,α、β∈V∗ ,若 α 和 β 不能同时推导出空,假定 α⇏∗ε,β⇒∗ε ,则当
FIRST(α)⋂FOLLOW(A)=∅ FIRST(β)⋂FOLLOW(A)=∅
也即是 FIRST(α)⋂(FIRST(β)⋃FOLLOW(A))=∅ 时,对于非终结符A的替换仍可唯一地确定候选。为了表示和分析方便,因此引入了SELECT集合。
SELECT集合定义如下:一个产生式的选择符号集SELECT。给定上下文无关文法的产生式 A→α,A∈VN,α∈V∗ ,若 α⇏∗ε ,则 SELECT(A→α)=FIRST(α) 。
如果 α⇒∗ε ,则 SELECT(A→α)=(FIRST(α)−{ε})⋃FOLLOW(A) 。
因此一个上下文无关文法是LL(1)文法的充分必要条件是,对每个非终结符A的两个不同产生式, A→α,A→β ,满足
SELECT(A→α)⋂SELECT(A→β)=∅
其中 α、β 不同时能 ⇒∗ε 。再次回到上述例题
A→BCc | gDB
B→bCDE | ε
C→DaB | ca
D→dD | ε
E→gAf | c非终结符 FIRST FOLLOW A {a, b, c, d, g} {f, #} B {b, ε } {a, c, d, g, f, #} C {a, c, d} {c, d, g} D {d, ε } {a, b, c, g, f, #} E {c, g} {a, c, d, g, f, #} 右部产生式 FIRST BCc {a, b, c, d} gDB { g } bCDE { b } ε { ε } DaB {a, d} ca { c } dD { d } gAf { g } c { c } 因此根据以上所求得的FIRST集和FOLLOW集,可求得各产生式的SELECT集合如下:
SELECT(A→BCc)={a,b,c,d}SELECT(A→gDB)={g}SELECT(B→bCDE)={b}SELECT(B→ε)={a,c,d,g,f,#}SELECT(C→DaB)={a,d}SELECT(C→ca)={c}SELECT(D→dD)={d}SELECT(D→ε)={a,b,c,g,f,#}SELECT(E→gAf)={g}SELECT(E→c)={c}
由上可知,有相同左部产生式的SELECT集合的交集为空,所以文法是LL(1)文法。

















 1334
1334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









