







Spark Streaming简介
spark streaming是构建在spark core之上,提供的可扩展、高吞吐、容错的实时流处理模块,它能接受来自kafka、flume、tcp各种渠道的数据,进行用户定义的各种Map、Reduce计算,最终将数据继承到文件系统、HDFS、Hbase这样的存储平台或者将参数的数据供后端系统消费;今天我们着重介绍下Streaming模块中的类依赖关系以及自己动手写一个Dstream。
类图
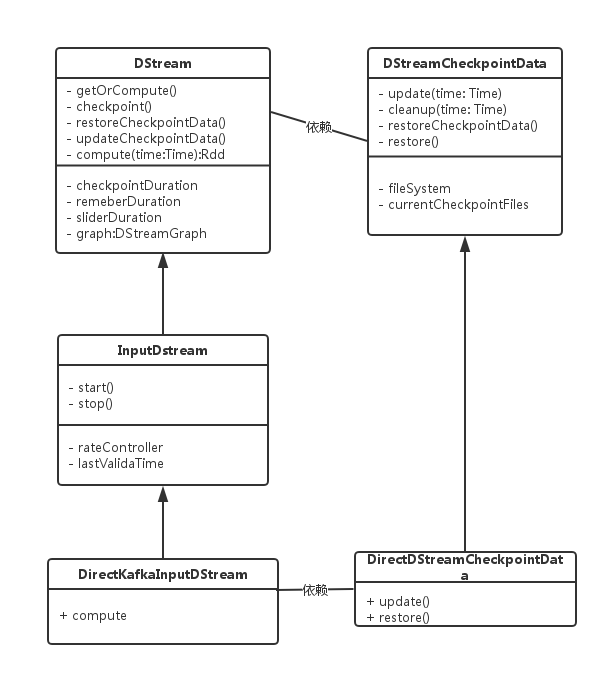
spark streaming的所有类均继承自DStream,DSteam的compute方法定义了创建RDD的挂载点,子类需要实现该方法,提供创建RDD的方式;同时其也提供了一套stream的checkpoint逻辑,用户也可以根据自己的业务逻辑定义自己的DStreamCheckpointData,其包括了更新、清除、恢复等checkpoin操作;
动手写Dstream
我们提供一个基于文件的输入流,每个周期从文件中读取固定的几行生成一个RDD,这个RDD只包含一个Partition,测试方法中为对生成的RDD进行打印操作
文件流的实现
class FileInputDstream(@transient ssc: StreamingContext, file: String) extends InputDStream[String](ssc) with Logging{
private[FileInputDstream] val batchLines = 10
require(file != null, "file could not be null")
var scanner: Scanner = new Scanner(new File(file))
override def start(): Unit = {}
override def stop(): Unit = {}
override def compute(validTime: Time): Option[FileLineRDD]= {
var count = 0
val arrBuffer = ArrayBuffer[String]()
while(scanner.hasNextLine && count < 2){
arrBuffer += scanner.nextLine()
count += 1
}
Some(new FileLineRDD(ssc.sparkContext, arrBuffer.toArray))
}
}
RDD的实现
class FileLineRDD(sc: SparkContext, lineList: Array[String]) extends RDD[String](sc, Nil) with Logging{
@DeveloperApi
override def compute(split: Partition, context: TaskContext): Iterator[String] = {
println(lineList.size)
lineList.iterator
}
override protected def getPartitions: Array[Partition] = {Array(new FileLineRDDPartition("", 0, lineList.size))}
}
class FileLineRDDPartition(
val fileName: String,
val index: Int,
val lines: Int
) extends Partition {
/** Number of messages this partition refers to */
def count(): Long = lines
}测试代码
object FileStreamingTest {
def main(args: Array[String]) {
val sparkConf = new SparkConf
sparkConf.setMaster("local[10]")
sparkConf.setAppName("streaming test")
sparkConf.set("spark.extraListeners", "com.scala.streaming.test.SimpleSparkListener")
val jssc = new JavaStreamingContext(sparkConf, new Duration(2000));
val file = "F:\\code\\product\\scala\\streaming-test\\src\\resource\\streaming.txt"
new FileInputDstream(jssc.ssc, file).foreachRDD((rdd: RDD[String]) => rdd.foreachPartition(_.foreach(println _)))
jssc.start();
jssc.awaitTermination()
}
}














 1232
1232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









