







基础推荐模型——传送门:
- 推荐系统 | 基础推荐模型 | 协同过滤 | UserCF与ItemCF的Python实现及优化
- 推荐系统 | 基础推荐模型 | 矩阵分解模型 | 隐语义模型 | PyTorch实现
- 推荐系统 | 基础推荐模型 | 逻辑回归模型 | LS-PLM | PyTorch实现
- 推荐系统 | 基础推荐模型 | 特征交叉 | FM | FFM | PyTorch实现
- 推荐系统 | 基础推荐模型 | GBDT+LR模型 | Python实现
文章目录
一、GBDT+LR——特征工程模型化的开端
FFM 模型采用引入特征域的方式增强了模型的特征交叉能力,但无论如何,FFM 只能做二阶的特征交叉,如果继续提高特征交叉的维度,会不可避免地产生组合爆炸和计算复杂度过高的问题。那么,有没有其他方法可以有效地处理高维特征组合和筛选的问题呢? 2014 年, Facebook 提出了基于 GBDT+ LR组合模型的解决方案。
1.GBDT+LR 组合模型的结构
Facebook 提出了一种利用 GBDT 自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作 LR 模型输入,预估 CTR 的模型。其模型结构如下:
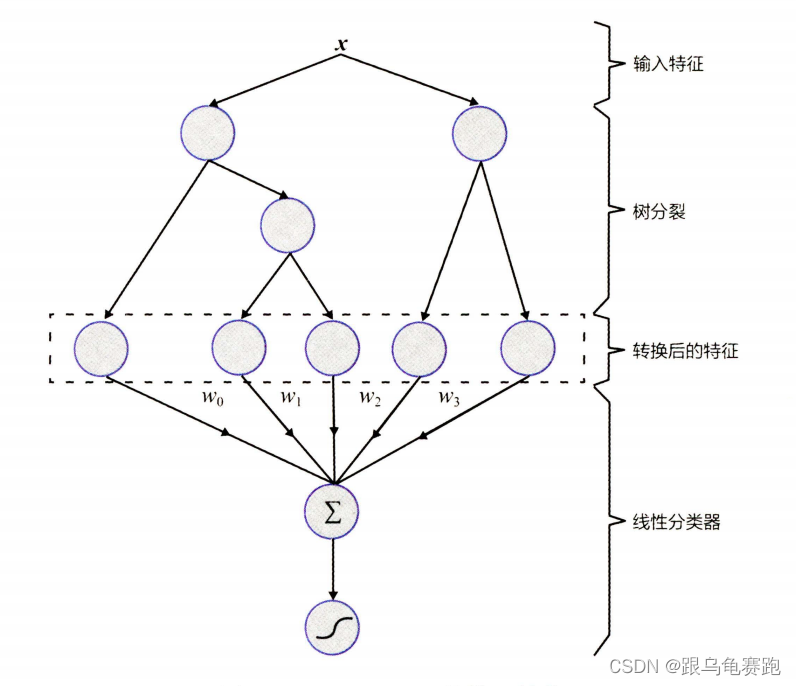
需要强调的是,用 GBDT 构建特征工程 ,利用 LR 预估 CTR 这两步是独立训练的,所以不存在如何将LR的梯度回传到GBDT 类复杂的问题。
2.GBDT 进行特征转换的过程
利用训练集训练好 GBDT 模型之后,就可以利用该模型完成从原始特征向量到新的离散型特征向量的转化。具体过程为:一个训练样本在输入 GBDT 的某一子树后,会根据每个节点的规则最终落入某一叶子节点,把该叶子节点置为1 ,其他叶子节点置为0 ,所有叶子节点组成的向量即形成了该棵树的特征向量,把 GBDT 所有子树的特征向量连接起来,即形成了后续 LR 模型输入的离散型特征向量。
举例来说,如下图所示,GBDT由三棵子树构成,每棵子树有4个叶子节点,输入一个训练样本后,其先后落入"子树1 "的第3个叶节点中,那么特征向量就是[0,0,1,0],“子树 2” 的第1个叶节点,特征向量为 [1,0,0,0] ,"子树 3"的第4个叶节点,特征向量为 [0,0,01] ,最后连接所有特征向量,形成最终的特征向量[0,0,1,0,1,0,0,0,0,0,01]。
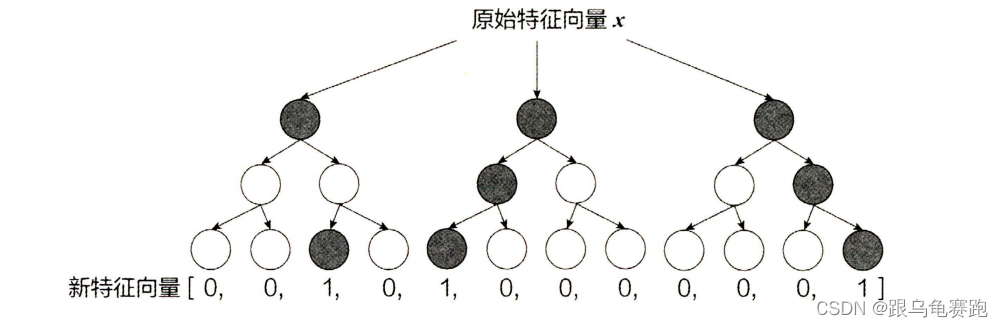
事实上,决策树的深度决定了特征交叉的阶数。如果决策树的深度为 4,则通过3次节点分裂,最终的叶节点实际上是进行三阶特征组合后的结果,如此强的特征组合能力显然是 FM 系的模型不具备的。但 GBDT 容易产生过拟合,以及GBDT的特征转换方式实际上丢失了大量特征的数值信息,因此不能简单地说GBDT 的特征交叉能力强,效果就比FFM 好,在模型的选择和调试上,永远都是多种因素综合作用的结果。
3.GBDT+LR 组合模型开启特征工程新趋势
GBDT+LR 组合模型对于推荐系统领域的重要性在于:它大大推进了特征工程模型化这一重要趋势。 GBDT+LR 组合模型出现之前,特征工程的主要解决方法有两个: 一是进行人工的或半人工的特征组合和特征筛选,二是通过改造目标函数,改进模型结构,增加特征交叉项的方式增强特征组合能力。但这两种方法都有弊端,第一种方法对算法工程师的经验和精力投入要求较高;第二种方法
则要求从根本上改变模型结构,对模型设计能力的要求较高。
GBDT+LR 组合模型的提出,意味着特征工程可以完全交由一个独立的模型来完成,模型的输入可以是原始的特征向量 ,不必在特征工程上投入过多的人筛选和模型设计的精力,实现真正的端到端( End to End) 训练。
广义上讲,深度学习模型通过各类网络结构 Embedding 层等方法完成特征工程的自动化,都是 GBDT+LR 开启的特征工程模型化这一趋势的延续。
二、GBDT+LR模型在criteo数据集上的实验
1.数据集介绍
criteo数据集每行对应一个由 Criteo 提供的展示广告。有如下特征:
Label:待预测广告,被点击是1,没有被点击是0I1-I13:共有 13 列数值型特征(主要是计数特征)C1-C26:共有 26 列类别型特征
数据集下载地址为:https://www.kaggle.com/c/criteo-display-ad-challenge/data。我这里采用前100k个样本进行实验。
2.Python实现
FM推荐模型在criteo数据集上的Python实现,分为以下几个步骤:
- 数据预处理:
dataProcess.py - 数据加载:
dataSet.py - 模型搭建:
LR_Model.py - 主函数:训练及预测-
main.py
2.1 数据预处理
#!usr/bin/env python
# -*- coding:utf-8 -*-
"""
@author: liujie
@file: dataProcess.py
@time: 2022/09/05
@desc:
数据预处理流程:
1.特征处理
2.数据分割
"""
import torch
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder, OrdinalEncoder, KBinsDiscretizer
from sklearn.model_selection import train_test_split
class DataProcess():
def __init__(self, file, nrows, sizes, device):
# 特征列名
names = ['label', 'I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9', 'I10', 'I11',
'I12', 'I13', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11',
'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'C22',
'C23', 'C24', 'C25', 'C26']
self.device = device
# 读取数据
self.data_df = pd.read_csv(file, sep="\t", names=names, nrows=nrows)
self.data = self.feature_process()
def feature_process(self):
# 连续特征
dense_features = ['I' + str(i) for i in range(1, 14)]
# 离散特征
sparse_features = ['C' + str(i) for i in range(1, 27)]
features = dense_features + sparse_features
# 缺失值填充:连续特征缺失值填充0;离散特征缺失值填充'-1'
self.data_df[dense_features] = self.data_df[dense_features].fillna(0)
self.data_df[sparse_features] = self.data_df[sparse_features].fillna( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











