






使用k近邻进行车辆推荐
kNN介绍
kNN是监督学习的一种,监督学习的数据必须有“分类标签”,kNN通过“距离”判定“类别”,通过考虑 k个最近邻的类别,确定“待分类”数据的类别,其中 k 个最近邻的类别可由“简单多数”原则确定。
在 kNN 算法中,除了日常熟悉的平面和三维空间距离外,又扩展了多维空间的距离。多维空间可以表达事物的多重特征,不同于日常习惯的三维空间它是一个逻辑的空间。
在事物拥有多重特征时,可以使用归一化(Normalization)方法,平衡特征权值对结果的影响。同时,归一化有提高训练效率的作用。
通过 kNN 总结人工智能算法的一般求解过程,包括整理数据(特征工程)、通过数据训练模型、验证模型、利用模型生产。如果模型在测试数据上都不能达到令人满意的正确率则称“欠拟合”,但是经常会出现模型在测试数据中可以获得很好效果, 而在泛化中正确率明显降低的“过拟合”情况,其原因是用来求解模型的数据与真实数据对比存在规模小、特征偏颇等不足,所以保证训练数据拥有合理的规模和完备的特征对于人工智能算法而言是十分重要的。
使用 k近邻 进行车辆推荐
代码主要分为引用工具、定义数据、数据处理、建立模型预测并输出共 4 个部分,代码中的“#”表示本行代码为注释,即是说明性文字并不参与程序运行。
另外为了便于说明问题,正文中的代码都有行号,而真实运行的程序中是不应该有行号的。
首先导入需要用的模块:
下列程序代码中的代码说明将用到 numpy 和 KNeighborsClassifier 这两个工具。
import numpy as np
from sklearn.neighbors import KNeighborsClassifier as knn
在代码中,numpy 和 sklearn 是两个 python 语言的“工具模块”,numpy 模块的功能是进行高效计算,其特点是不但支持数字的运算,还支持数据集合的运算(如矩阵运算),这样大大提高了计算的效率。import 的意义是“引入”,其中文含意就是引入 numpy 模块,后面的 as np 是指用 np 这个简称代替 numpy。
sklearn 是一个可以进行人工智能算法的模块,而 sklearn.neighbors 指的是 sklearn 中的 neighbors 工具。该句话的含义是从 sklearn.neighbors 工具中引入 KNeighborsClassi-fier 分类器,并用 knn 这个简称代替之。
接下来根据表格中的数据将程序定义一个数据结构 ar_x,在编程中一般称之为“矩阵”,它用一组嵌套的“[ ]”表达了表格中的数据,这种结构术语称为 array, “[ ]”表达集合的概念,里层的“[ ]”表达表格中的每行数据,最外层的“[ ]”表达了“行的集合”,而对于车型推荐标志“+”和用另一个 array: ar_y 存储,ar_x 存放了训练集和测试集的全部数据, 而将训练集的已知结果放在ar_y中,用 0 表示不推荐,用 1 表示推荐。需要注意的是,测试集的结果并没有存在ar_y 中。
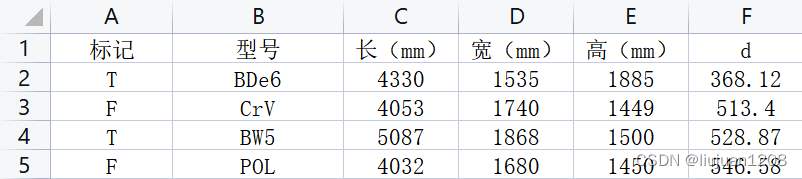
ar_x=[[4032,1680,1450,5.3,5.6],
[4330,1535,1885,7.8,14.5],
[4053,1740,1449,6.2,10.8],
[5087,1868,1500,8.5,25.6],
[4560,1822,1645,7.8,15.8],
[3797,1510,1820,5.5,9.6]]
ar_y=[0,1,0,1]
在 ar_min = np.min(ar_x,0) 中,np.min 是用来求矩阵最小元素的工具,0 是指求每列的最小值,之后将求得的最小值存在 ar_min 中。但是ar_mn = np.max(ar_x,0) -ar_min 中的 np.max 与 np.min 功能相反,求矩阵最大元素,然后计算了最大值和最小值的差存放在 ar_mn 中。
nor_ar =np.around((ar_x-ar_min)/ar_mn,4)按照以下公式形式完成所有数据的归一化。
x ′ = x − m i n X m a x X − m i n X x^{'}=\frac{x-minX}{maxX-minX} x′=maxX−minXx−minX
其中 np.around 的含义是保留小数,后面的参数 4 表示结果保留 4 位小数。
完成了归一化工作,并把数据保存在 nor_ar中,打印这个矩阵并观察结果:
[[0.1822 0.4749 0.0023 1. 0. ]
[0.4132 0.0698 1. 0.0484 0.445 ]
[0.1984 0.6425 0. 0.0147 0.26 ]
[1. 1. 0.117 0.0632 1. ]
[0.5915 0.8715 0.4495 0.0484 0.51 ]
[0. 0. 0.8509 0. 0.2 ]]
model = knn(n_neighbors = 3) 建立了一个 kNN 模型,其中 k = 3,然后用训练集具体化了这个模型 model.fit(nor_ar[:4] ,ar_y),因为训练集只有 4 个数据,所以使用 nor_ar 矩阵的前 4 行数据即可,nor_ar[:4]的含义就是取 nor_ar 的前 4 行的值,由于在 Python 这种编程语言中序列编号从 0 开始,所以实际是 nor_ar[0],nor_ar[l],nor_ ar[2] 和 nor_ar[3] 这 4 行数据,同时将整个 ar_y(0,1,0,1) 也传入模型。
这时模型已经建立,可以计算测试集的分类了,使用 model.predict 方法预测了 nor_ar 后两个数据 (nor_ar[4] ,nor_ar[5]) 的类型,以下代码完成该功能:
pre = model, predict( nor_ar[4:6])
print (pre )
用 print 输出了对测试集 nor_ar 的第4行和第5行两行(nor_ar[4:6 ])的 预测结果:[1,0],可以得知,预测模型在测试集上获得了 100% 的正确率。
完整代码如下:
#引入工具包
import numpy as np
from sklearn.neighbors import KNeighborsClassifier as knn
# 定义数据
ar_x=[[4032,1680,1450,53,5.6],
[4330,1535,1885,7.8,14.5],
[4053,1740,1449,6.2,10.8],
[5087,1868,1500,8.5,25.6],
[4560,1822,1645,7.8,15.8],
[3797,1510,1820,5.5,9.6]]
ar_y=[0,1,0,1]
#利用均一化处理数据
ar_min= np.min(ar_x,0)
ar_mn=np.max(ar_x,0)-ar_min
nor_ar= np.around((ar_x-ar_min)/ar_mn, 4)
#建立模型并预测
model= knn(n_neighbors =3)
model.fit(nor_ar[: 4],ar_y)
pre=model.predict(nor_ar[4: 6])
print(pre)
以上内容参考书本《人工智能应用基础Python版》,并未用于商业用途,仅限知识传载,如侵删。















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









