







Redis高并发经典问题
1. 缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如 DB)。
产生原因:查询缓存中key不存在或者数据库中根本不存在的数据,会穿过缓存查询数据库
解决方案:
-
对查询结果为空的情况也进行缓存,缓存时间(ttl)设置短一点,或者该key对应的数据insert了之后清理缓存。 问题:缓存太多空值占用了更多的空间
-
使用布隆过滤器。在缓存之前在加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回,存在再查缓存和DB。
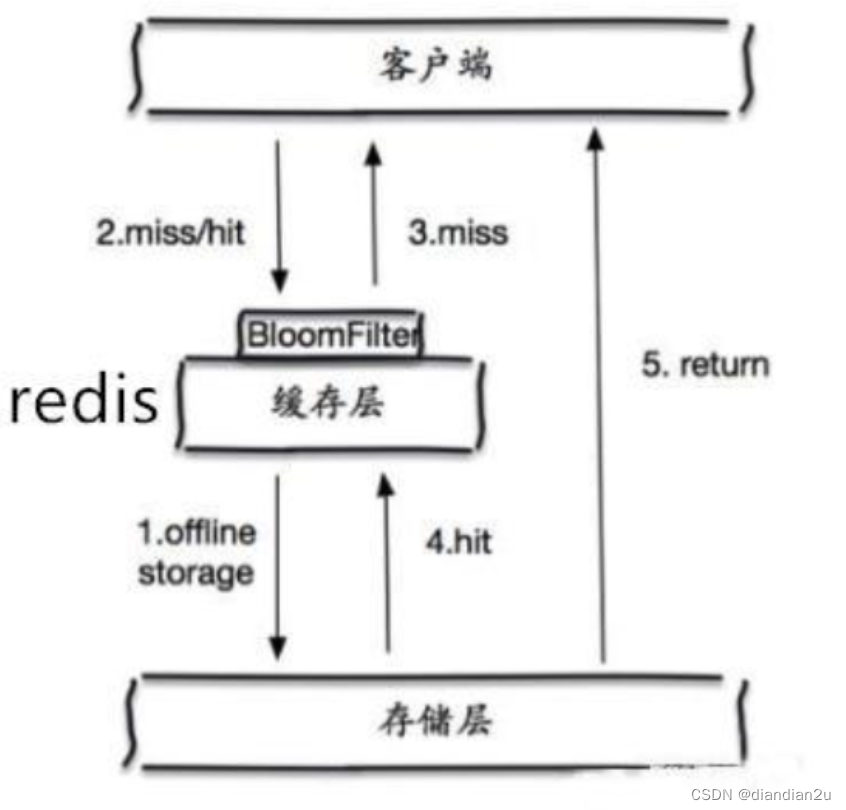
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般
的算法。
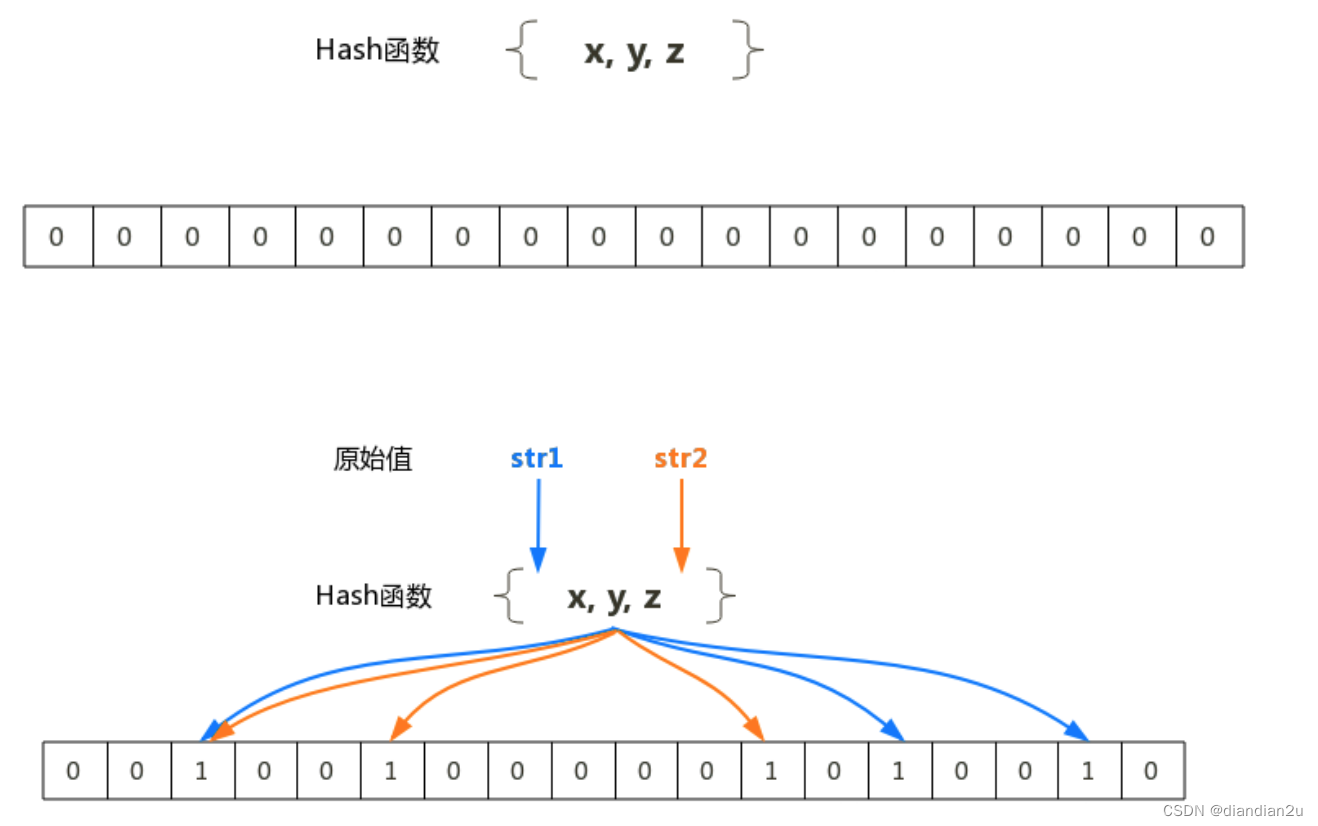
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。
把字符串------>位省空间 (1或0)
不用循环------>比较位置 省时间
注意: 如果数据库更新了,布隆过滤器一定要更新,对应的redis也要更新
2. 缓存击穿
产生原因:设置过期时间的热点key在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,大并发的请求可能会瞬间把后端DB压垮。
解决方案:
1、用分布式锁控制访问的线程
使用redis的setnx互斥锁先进行判断,这样其他线程就处于等待状态,保证不会有大并发操作去操作数据库。
2、不设超时时间,但淘汰策略设置为:volatile-lru的话,会造成写一致问题,可以启用延时双删, “用的不多”
当数据库数据发生更新时,缓存中的数据不会及时更新,这样会造成数据库中的数据与缓存中的数据的不一致,应用会从缓存中读取到脏数据。可采用延时双删策略处理。
产生原因:当缓存服务器重启或者大量key在某一个时间段失效,导致大量的数据库访问
解决方案:
1、 key的失效期分散开,不同的key设置不同的有效期
2、设置二级缓存(数据不一定一致)
3、高可用(脏读)
3. 缓存雪崩
产生原因:当缓存服务器重启或大量缓存集中在某一时间段失效,大量请求访问数据库,造成数据库崩溃
解决方案:
1、key的失效期分散设置,不同key设置不同有效期
2、设置二级缓存,但数据不一定保持一致
3、设计高可用方案,可能会出现脏读
PS:
| 问题 | 产生原因 | 解决方式 |
|---|---|---|
| 缓存穿透 | 数据在缓存或数据库中不存在 | 缓存空值 布隆过滤器 |
| 缓存雪崩 | 大量数据同时过期或缓存宕机 | 数据预热 设置不同的过期时间 服务降级 服务熔断 限流机制 |
| 缓存击穿 | 大量请求访问热点数据,但热点数据过期 | 对于热点数据,不设置过期时间 分布式锁控制访问的线程 |
4. 数据库缓存双写不一致
问题产生的原因
一般来说读缓存是不会有什么问题的,但是一旦涉及到数据更新,也就是数据库和缓存都操作,就容易出现缓存(Redis)和数据库间的数据一致性问题。
在数据更新时,我们需要做以下两步:
- 操作MySQL
- 操作缓存
但是无论是先执行步骤1还是先执行步骤2,都有可能出现数据不一致的情况,主要是因为读写是并发的,我们无法保证他们的先后顺序。那如何更新缓存呢?有如下三种策略:
- 先写缓存,再写数据库
- 先写数据库,再写缓存
- 先删缓存,再写数据库
- 先写数据库,再删缓存
数据库缓存双写相关策略
前提:在高并发业务场景中,写数据库和写缓存的操作都属于远程操作。为避免大事务造成的死锁问题,通常建议写数据库和写缓存不放在同一事务中。任一方操作异常,数据不会同时回滚。
-
先写缓存,再写数据库
场景:某个用户先写缓存,突然网络异常,写数据库失败。
结果:缓存写入,数据库依然是旧值
我们都知道,缓存的主要目的是把数据库的数据临时保存在内存,便于后续的查询,提升查询速度。
但这种情况缓存中是数据库中不存在的“假数据”,没有任何意义。不可取,实际工作中使用的不多。
-
先写数据库,再写缓存
两个写请求a,b,操作如图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5uQGXh0b-1684923160068)(/Users/lmn/IdeaProjects/diandian/document/技术文档/技术资料/Redis/image-20230508113120578.png)]](https://img-blog.csdnimg.cn/991ee4235e394868a198053689dbd201.png)
即两个请求a,b,数据库都写入成功,但缓存可能会写入新值被旧值覆盖,双写不一致。写缓存还有可能是个遍历查找key要求较高的过程,这样多个请求写同一key,也会出现不一致。
所以我们尽量避免写缓存的操作,考虑删除缓存的方案。
-
先删缓存,再写数据库
假设高并发的场景中,同一个用户的同一条数据,一个读数据请求 c,一个写数据请求 d(一个更新操作),同时请求到业务系统。如下图所示:
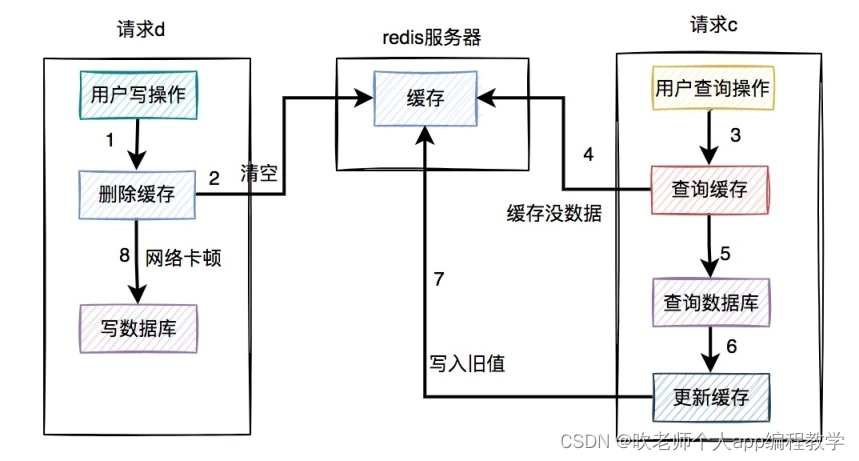
也就是同一用户操作数据,读操作在写操作完成之前,因此读取的是旧值。
这种情况下,考虑如何解决:缓存双删(延时双删):在写数据库之前删除一次缓存,写完数据库再删除一次缓存。
该方案有个非常关键的地方是:第二次删除缓存,并非立马就删,而是要在一定的时间间隔之后。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









