







 本文提供了一个简单的Python爬虫代码示例,用于爬取网页中的图片。通过正则表达式匹配图片URL并下载,适用于学习用途,未包含复杂的错误处理机制。
本文提供了一个简单的Python爬虫代码示例,用于爬取网页中的图片。通过正则表达式匹配图片URL并下载,适用于学习用途,未包含复杂的错误处理机制。
这里贴上py源码,这个爬虫很简单,爬取网页的图片,通过正则表达式匹配对应的图片的url 然后下载之,基本上也没有什么容错处理,仅供学习之用
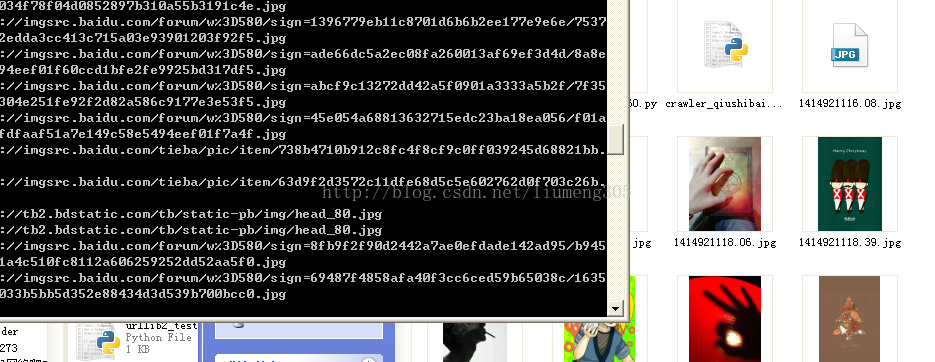
# -*- coding: utf-8 -*-
import urllib2
import urllib
import re
import time
#通过 url 获取网页源码 html
def getHtml(url):
page = urllib2.urlopen(url)
html = page.read()
return html
#在html中找到匹配的 url
def getImg(html):
#修改这里的匹配模式,适用于不同的网页
reg = r'src="(http://.+?\.jpg)" ' # +号后面加上? --->非贪婪模式
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
i = 0
for imgurl in imglist:
print imgurl
urllib.urlretrieve(imgurl,'%s.jpg'%time.time() )#下载imgurl的图片并且用当前时间戳命名
i+=1
#return imglist
url = "http://tieba.baidu.com/p/2772656630"
html = getHtml(url)
print getImg(html)















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









