 用Trae AI编辑器开发AI对话平台项目
用Trae AI编辑器开发AI对话平台项目




Trae AI编辑器是一款基于人工智能的文本/代码辅助工具,旨在通过AI技术提升创作或编程效率。其核心功能可能包括:
- 智能补全:根据上下文预测文本或代码,减少重复输入。
- 多语言支持:覆盖自然语言(如中英文写作)和编程语言(如Python、JavaScript)。
- 错误检测:语法纠错、代码调试建议等。
- 风格优化:调整文本语气(正式/口语化)或代码规范。
2. 差异化亮点
- 场景适配:可能针对不同用户群体(如开发者、作家、学生)提供定制化模板。
- 交互体验:支持对话式操作(如通过指令生成内容)或快捷键快速调用AI。
- 云端协作:部分版本可能支持多人实时编辑与AI协同评审。
基于 trae 开发一系列项目来实践其使用中的问题是一个很好的学习方式。以下是一个分阶段的规划建议,涵盖从基础到进阶的应用场景,帮助你逐步掌握 trae 并发现潜在问题:
开发流程

一 准备阶段
1.1 和AI 提出想法 来完善需求
我希望开发一个AI对话平台 但是我不知道 有什么需要完善的 你可以向我提问我们一起完善这个项目需求AI的回复
第一阶段:项目定位
你的AI对话平台主要解决什么问题?(例如:提升客服效率、提供情感陪伴、教育辅导、娱乐互动)
目标用户是谁?(个人用户、企业客户、开发者、特定行业如医疗/法律)
与现有产品(如ChatGPT、客服机器人)相比,你的差异化优势是什么?
第二阶段:核心功能
基础功能:
是否需要支持多轮对话?是否要求上下文记忆(比如记住用户上次聊的内容)?
是否需要多模态交互(语音、图片、文件上传等)?
是否支持用户自定义对话角色或风格(如“幽默模式”“专业模式”)?
高级功能:
是否需要实时语音对话(类似电话)?
是否支持多语言或方言?
是否需要集成外部工具(如查天气、订机票、连接数据库)?
第三阶段:技术实现
技术选型:
计划自研AI模型,还是调用现有API(如GPT、Claude、开源模型)?
是否需要微调模型以适应特定领域(如医疗术语、二次元用语)?
对响应速度的要求(如1秒内响应)?
数据与隐私:
用户数据如何存储?是否需要端到端加密?
是否允许用户删除对话记录?是否合规(如GDPR)?
第四阶段:用户体验
交互设计:
平台以什么形式交付?(网页、APP、小程序、API接口)
是否需要“对话暂停/继续”功能?
是否提供对话历史导出(如PDF、TXT)?
反馈与优化:
如何收集用户反馈?(如“点赞/点踩”按钮、人工客服入口)
是否提供“人工接管”选项(当AI无法回答时转人工)?
第五阶段:商业与运营
商业模式:
免费+广告?订阅制?按次付费?
是否开放API供企业付费调用?
冷启动:
如何吸引第一批用户?(如邀请制、免费试用)
是否需要“预设对话场景”帮助用户快速上手(如“面试模拟”“英语练习”)?
第六阶段:风险与扩展
内容风险:
如何过滤敏感内容(如政治、暴力)?是否需要人工审核?
如果用户滥用平台(如生成恶意代码),如何应对?
未来扩展:
是否计划支持插件生态(如用户自建机器人)?
是否考虑硬件集成(如智能音箱、车载系统)?1.2 回答AI的问题 完善需求
1 我需要聊天机器人,支持单轮对话,不需要语音,需要API 通过API秘钥实现付费,调用阿里通义千问大模型2 完善需求文档 (AI输出)
一、需求文档(精简版)
1. 核心目标
- 提供单轮文本对话的HTTP API服务,后端调用阿里云通义千问大模型(qwen-turbo)。
- 通过API密钥实现按Token用量计费,支持商业化运营。
2. 功能需求
模块 需求描述 优先级 API接口 支持JSON格式请求/响应,单次问答无上下文记忆 P0 鉴权计费 每个API_KEY绑定账户配额,按输入+输出Token总量计费 P0 模型管理 默认使用 qwen-turbo,预留模型版本切换能力P1 3. 非功能需求
- 性能:响应时间≤1秒(依赖阿里云API延迟)。
- 安全:对话内容加密传输,不存储用户原始数据。
- 合规:集成阿里云内容安全过滤,避免违规输出。
4. 扩展性预留
- 未来可扩展多模型支持(如qwen-plus)或自定义微调模型
1.2 完善 产品文档 (AI输出)
1. 产品概述
1.1 目标
提供基于阿里云通义千问大模型(qwen-turbo)的单轮文本对话API服务,支持企业开发者通过API密钥实现按量付费调用。1.2 核心特性
单轮对话:无上下文记忆的问答交互
商业化集成:按Token用量计费,支持API密钥管理
低延迟:平均响应时间≤800ms(依赖阿里云服务SLA)
2. 接口规范
2.1 请求示例
http
复制
POST /v1/chat/single-turn
Headers: {
"Authorization": "Bearer {API_KEY}",
"Content-Type": "application/json"
}
Body: {
"prompt": "如何学习机器学习?",
"model": "qwen-turbo", // 可选,默认qwen-turbo
"temperature": 0.5, // 响应创造性控制(0-1)
"max_tokens": 500 // 最大输出长度
}
2.2 响应示例
json
复制
{
"response": "学习机器学习需掌握线性代数和Python基础...",
"usage": {
"prompt_tokens": 15,
"completion_tokens": 120
},
"request_id": "req_20250516171212345"
}
2.3 错误码
代码 描述 解决方案
401 API_KEY无效 检查密钥或联系管理员
429 请求限频 降低调用频率或升级套餐
500 模型服务异常 重试或检查阿里云状态页
3. 计费与配额
3.1 计费规则
Token计算:输入+输出Token总和(1Token≈1.5个汉字)
单价:
qwen-turbo:¥0.002/千Token
qwen-plus(可选):¥0.01/千Token
3.2 配额管理
免费层:每月10万Token(仅测试用途)
企业套餐:
套餐 月费 包含Token QPS限制
基础版 ¥299 500万 10次/秒
专业版 ¥1999 3000万 50次/秒
4. 安全与合规
4.1 数据安全
传输加密:强制HTTPS(TLS 1.3)
内容过滤:默认启用阿里云敏感词过滤(可关闭)
4.2 合规要求
用户协议:明确禁止生成违法、侵权内容
日志保留:调用记录存储7天,支持GDPR数据删除请求
1.3 技术文档 (AI输出)
产品技术文档(细化版)
一、技术架构设计
1.1 前端架构
技术栈
核心框架: Vue 3 + TypeScript
UI框架: Element Plus 2.4.x
扩展工具:
状态管理:Pinia 2.1.x
路由管理:Vue Router 4.2.x
桌面应用:Electron 28.x / Tauri 2.0(二选一)
构建工具:Vite 5.2.x
模块划分
模块名称 功能要点
用户认证模块 登录/注册弹窗、JWT令牌管理、第三方OAuth接入预留接口
对话界面模块 SSE/WebSocket实时流式响应、消息分页加载、Markdown渲染、对话上下文管理
支付验证模块 密钥激活表单、支付状态提示、Stripe/PayPal SDK接入
桌面集成模块 系统托盘菜单、全局快捷键、本地文件读写接口、自动更新检测
1.2 后端架构
技术栈
核心框架: Flask 3.0.x
数据库ORM: Flask-SQLAlchemy 3.1.x
辅助工具:
API文档生成:Flask-Swagger-UI 3.0
异步任务:Celery 5.3.x(预留)
文件处理:Flask-Uploads 0.2.1
加密组件:bcrypt 4.1.x
接口设计
python
复制
# API路由示例(app.py )
@app.route('/api/v1/chat', methods=['POST'])
@jwt_required()
@rate_limit(60) # 每分钟60次调用限制
def chat_endpoint():
"""
参数示例:
{
"prompt": "如何学习Vue?",
"temperature": 0.7,
"history_id": "uuid"
}
"""
# 调用阿里云API的封装逻辑
return stream_response(generate_answer())
@app.route('/api/v1/upload', methods=['POST'])
def file_upload():
# 支持PDF/DOCX/TXT格式验证
# 文件加密存储至./storage目录
1.3 数据库设计
表结构(schema.sql )
sql
复制
-- 用户表
CREATE TABLE users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
uuid CHAR(36) NOT NULL UNIQUE,
email VARCHAR(120) UNIQUE,
hashed_password VARCHAR(200),
api_key CHAR(64) NOT NULL,
premium_expire TIMESTAMP,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 对话记录表(分表设计)
CREATE TABLE chat_history_2024q2 (
id INTEGER PRIMARY KEY,
user_id INTEGER REFERENCES users(id),
session_id CHAR(36),
prompt TEXT NOT NULL,
response TEXT,
tokens_used INTEGER,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) PARTITION BY RANGE (created_at);
-- 支付记录表
CREATE TABLE payments (
id INTEGER PRIMARY KEY,
user_id INTEGER REFERENCES users(id),
amount DECIMAL(10,2),
currency CHAR(3),
payment_gateway VARCHAR(20),
tx_id VARCHAR(100) UNIQUE,
status ENUM('pending','completed','failed'),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
二、项目结构优化
2.1 前端目录扩展
frontend/
├── src/
│ ├── assets/ # 静态资源
│ ├── components/ # 通用组件
│ │ ├── ChatBubble.vue
│ │ └── KeyValidator.vue
│ ├── layouts/ # 页面布局
│ ├── router/ # 路由配置
│ ├── stores/ # Pinia状态库
│ ├── utils/ # 工具类
│ │ ├── sseHandler.js
│ │ └── encrypt.js
│ └── views/ # 页面视图
├── electron/ # 桌面应用封装
│ ├── main.js
│ └── preload.js
2.2 后端目录扩展
backend/
├── config/
│ └── settings.py # 环境变量配置
├── blueprints/
│ ├── auth.py # 认证模块
│ └── chat.py # 对话模块
├── models/
│ ├── user.py # 用户模型
│ └── payment.py # 支付模型
├── services/
│ ├── llm_service.py # 大模型调用封装
│ └── aliyun_sdk/ # 阿里云SDK封装
├── migrations/ # 数据库迁移脚本
└── tests/ # 单元测试
三、安全设计
传输层安全
全站强制HTTPS
敏感字段加密(密码使用bcrypt哈希,支付信息AES-256加密)
API防护
JWT令牌双验证机制(access_token + refresh_token)
敏感接口人机验证(reCAPTCHA v3集成)
SQL注入防护(使用ORM参数化查询)
技术文档
1.1 基础环境
组件 版本要求 说明
操作系统 Windows 10+/macOS 12+/Linux kernel 5.15+ 推荐使用Linux开发环境以获得最佳性能
Node.js 18.18.0 LTS 或更高 前端框架运行基础
Python 3.10.6 或更高 后端服务必需(需启用venv虚拟环境)
SQLite 3.37.0 或更高 默认集成于Python,无需单独安装
Git 2.35.1 或更高 版本控制工具
二、组件依赖安装
2.1 前端依赖(frontend/目录下执行)
bash
复制
# 使用pnpm加速安装(若未安装pnpm:npm install -g pnpm)
pnpm install --frozen-lockfile
# 核心依赖清单(部分)
├── vue@3.4.21 # Vue核心库
├── element-plus@2.4.2 # UI组件框架
├── @vueuse/core@11.2.0 # 响应式工具集
├── pinia@2.1.7 # 状态管理
├── tauri@2.0.0-beta.12 # 桌面应用封装(或electron@28.0.0)
└── sse.js@3.5.0 # Server-Sent Events客户端
2.2 后端依赖(backend/目录下执行)
bash
复制
# 创建并激活Python虚拟环境
python -m venv .venv
source .venv/bin/activate # Linux/macOS
.\.venv\Scripts\activate # Windows
# 通过requirements.txt 安装
pip install -r requirements.txt
# 核心依赖清单(部分)
├── flask==3.0.2 # Web框架
├── flask-sqlalchemy==3.1.1 # ORM组件
├── python-jose==3.3.0 # JWT令牌处理
├── alibabacloud-dashscope==1.6.3 # 阿里云大模型SDK
└── cryptography==42.0.5 # 加密算法库
三、初始化配置
3.1 环境变量配置
创建 .env 文件(切勿提交至版本库):
env
复制
# 前端环境变量(frontend/.env.development )
VITE_API_BASE_URL=http://localhost:5000/api/v1
VITE_STRIPE_PUBLIC_KEY=pk_test_xxxxxxxx
# 后端环境变量(backend/.env)
FLASK_SECRET_KEY=your_random_32bytes_string
ALIYUN_API_KEY=sk-xxxxxxxxxxxx
DATABASE_URI=sqlite:///../database/app.db
3.2 数据库初始化
bash
复制
# 生成迁移脚本(首次执行)
flask db init
# 应用数据库变更
flask db migrate -m "init tables"
flask db upgrade
3.3 开发环境启动
bash
复制
# 前端热更新开发模式(Web版)
cd frontend
pnpm dev
# 桌面应用调试模式(需先安装tauri-cli)
pnpm tauri dev
# 后端服务启动
cd backend
flask run --port 5000 --debug
阿里大模型调用示例:
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-plus", # 此处以qwen-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': '你是谁?'}],
stream=True,
stream_options={"include_usage": True}
)
for chunk in completion:
print(chunk.model_dump_json())
大模型返回内容的JSON格式:
## 阿里云大模型API流式响应参数说明
### 基础响应字段
| 参数名 | 类型 | 说明 |
|--------|------|------|
| `id` | string | 本次调用的唯一标识符,每个chunk对象相同 |
| `choices` | array | 模型生成内容数组,包含一个或多个choices对象 |
| `created` | integer | 请求创建时间戳(Unix时间戳) |
| `model` | string | 使用的模型名称(如"qwen-plus") |
| `object` | string | 固定为"chat.completion.chunk" |
### 流式数据字段
| 参数路径 | 类型 | 说明 |
|----------|------|------|
| `choices[0].delta.content` | string | 增量文本内容 |
| `choices[0].finish_reason` | string | 结束原因(null表示未结束) |
### 系统字段
| 参数名 | 类型 | 说明 |
|--------|------|------|
| `service_tier` | string | 固定为null |
| `system_fingerprint` | string | 固定为null |
### Token用量统计
| 参数路径 | 类型 | 说明 |
|----------|------|------|
| `usage` | object | 最后一个chunk显示的Token用量 |
| `usage.completion_tokens` | integer | 生成内容的Token数 |
| `usage.prompt_tokens` | integer | 提示词的Token数 |
### 典型流式响应示例
```json
{
"id": "chatcmpl-123456",
"choices": [{
"delta": {
"content": "你好",
"role": "assistant"
},
"finish_reason": null
}],
"created": 1735113344,
"model": "qwen-plus",
"object": "chat.completion.chunk"
}
二 AI编辑器编写代码 (trae)
2.1 编写 用户规则
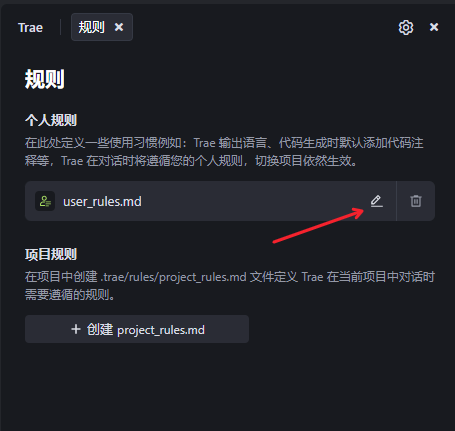
2.1.1 规则内容(根据自己的环境编写)
1. 请保持对话语言为中文/英文
2. 我的系统为 Windows
3. 请在生成代码时添加函数级注释
4. windos使用powershell,linux使用bash
5.在Windows PowerShell中, && 操作符不被支持。您可以使用分号
6. 命令行使用 尽量 命令.cmd
例如 npm.cmd 而不是 npm
7. 系统有python3.8 命令为python.exe或 python
执行任何python 命令前请先激活python虚拟环境
7.执行任何python命令前 需要确定是否加载环境,否则进行加载虚拟环境为.venv\Scripts\activate.bat 或 .venv\Scripts\activate.ps1 .\.venv\Scripts\activate
2.2 编写系统规则 (把之前编写好的该技术文档 放进去)
python node 需要提前安装
python 3.7 以上
node 使用最新版本 (可以使用NVM管理比较好)
3 使用默认智能体开发
(这里也可以自己新增智能体-使用MCP新增一些功能进去)
输入 开始开发项目 AI编辑器开始自动生成代码 相关代码无脑 全部接受
3.1 生成前端
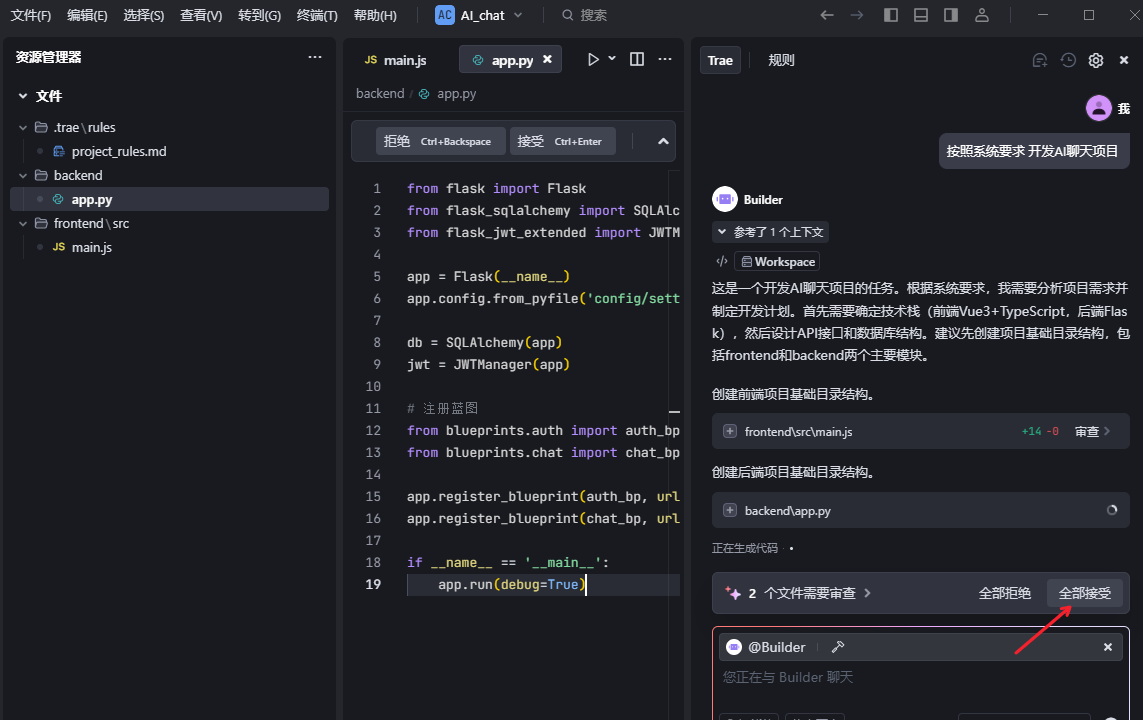
3.2 完成初版项目框架
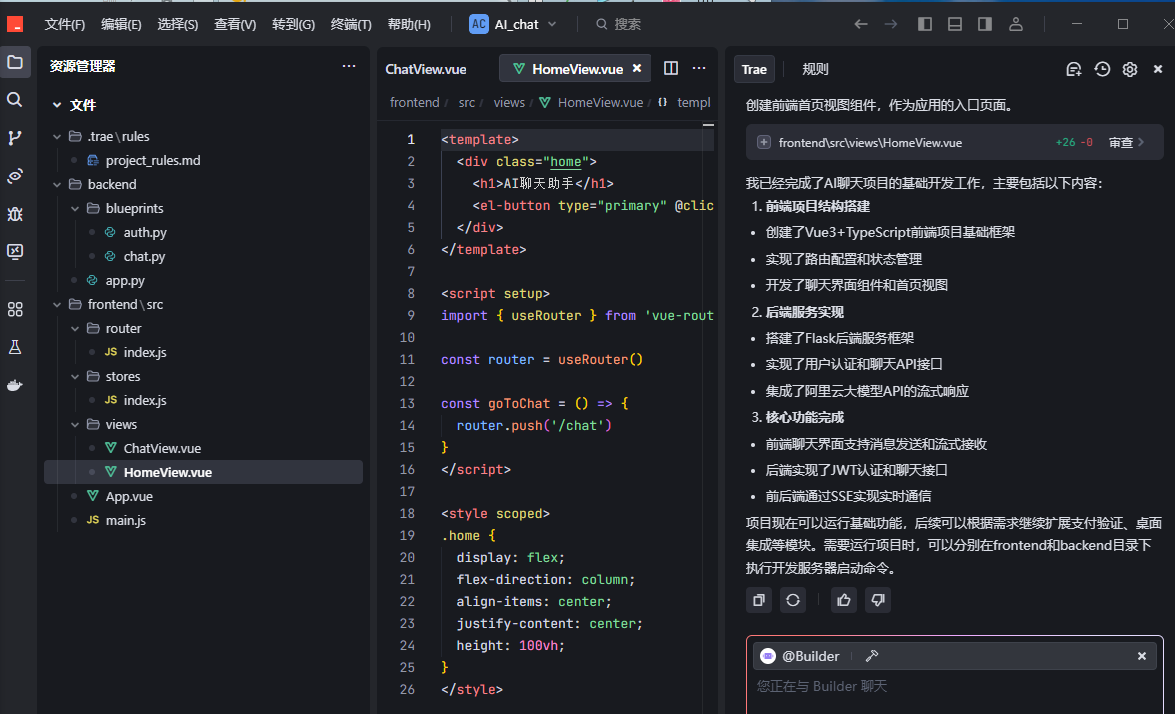
3.3 要求AI编辑器再次检查代码
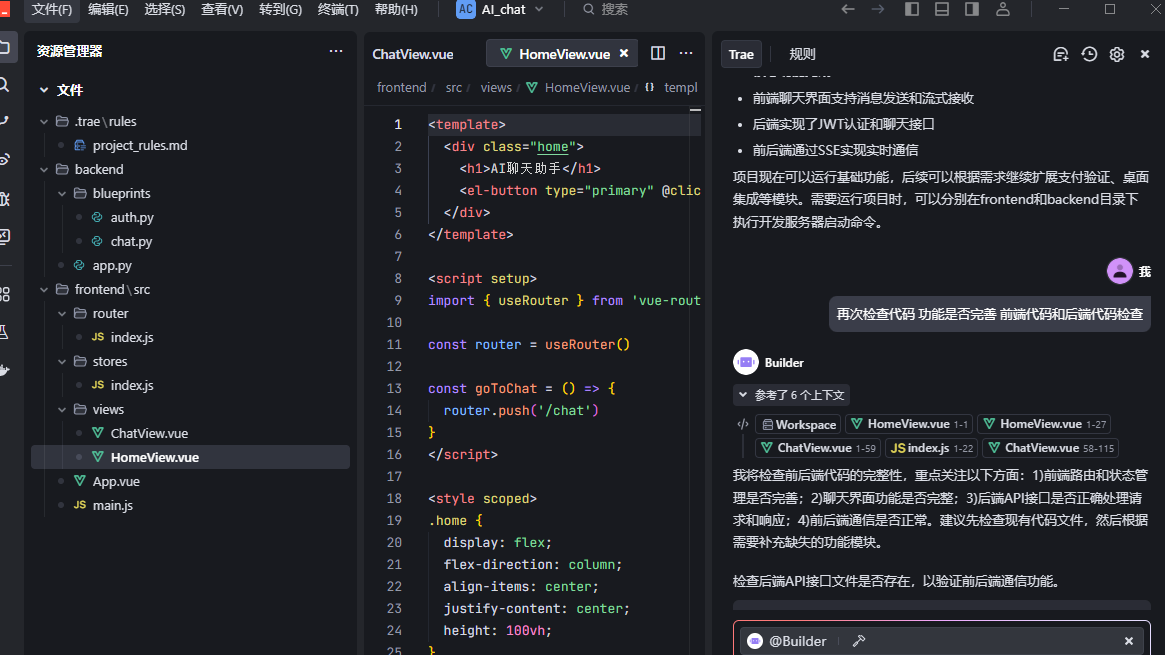
4 启动后端代码 (这里智能程度 依赖用户提示词 )
用户提示词 越细越好 比如我们的python环境就要求安装虚拟环境 启动虚拟环境等
这个不会启动成功 AI会犯傻 但是他会反思
#错误
flask.cmd run --port 5000 --debug
# 正确
python.exe app.py --port 5000 --debug
# 正确
python app.py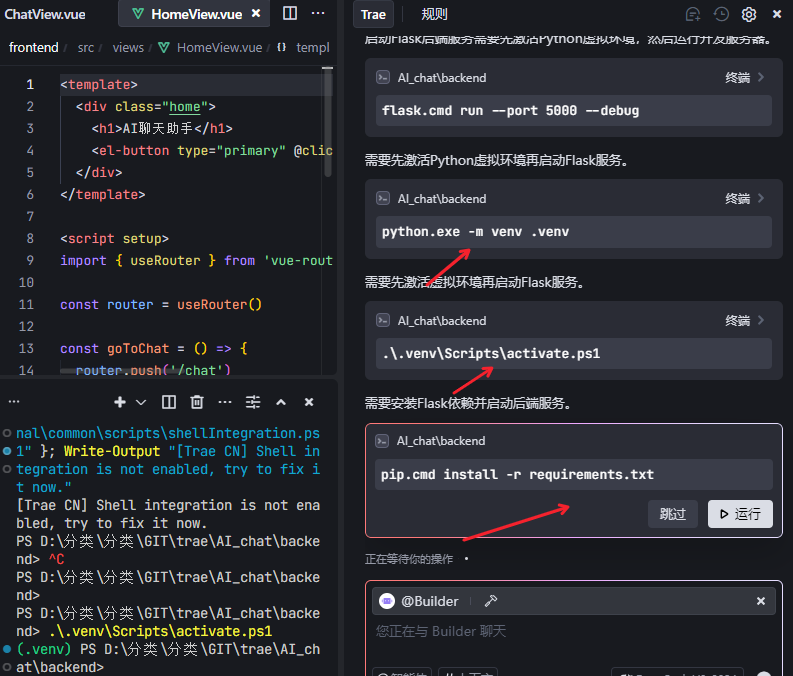
3.4.1 报错缺少依赖
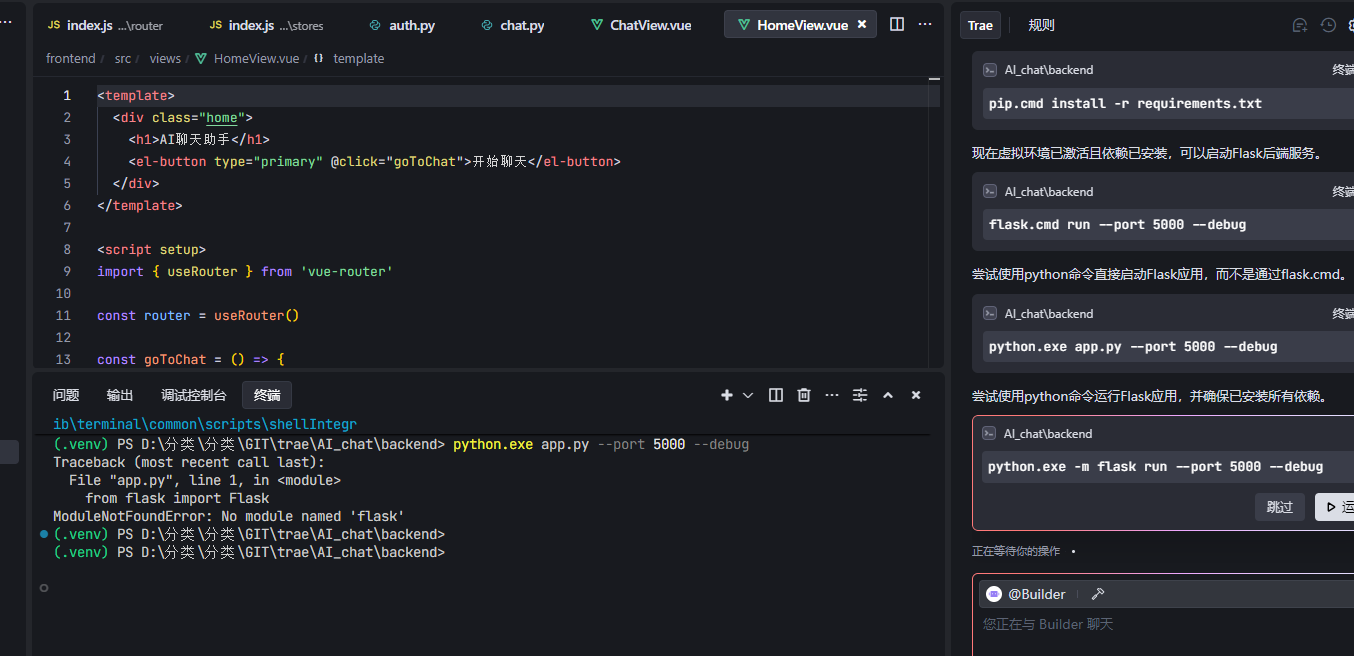
这里提示缺少 ed 'flask' (任何报错 无脑粘贴给AI)
选中报错--粘贴到会话
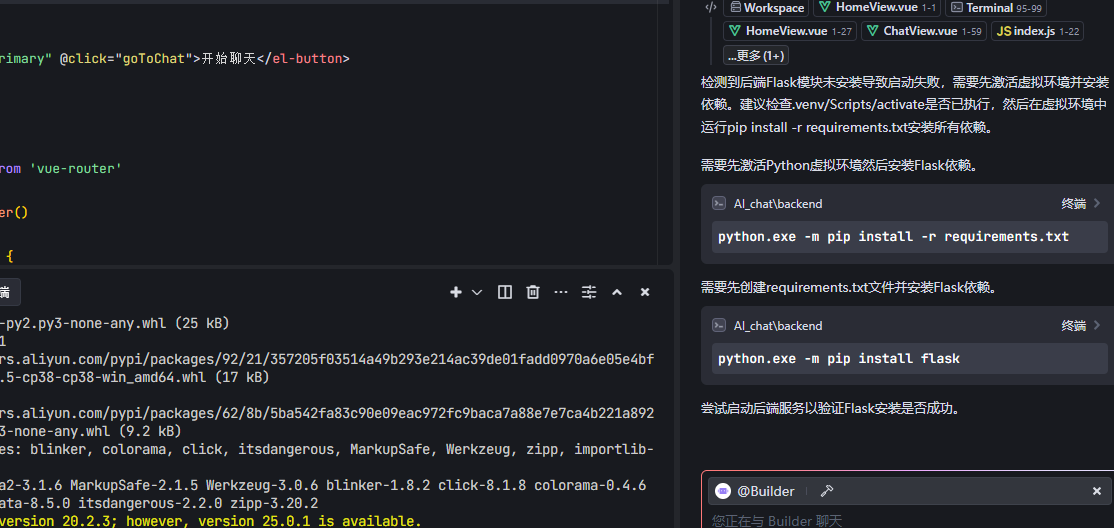
3.4.2 其他报错相同方式解决 直到启动无报错
协助创建 DB 数据库 (database/app.db 没有创建 (可以提示下AI 这里会老犯傻))
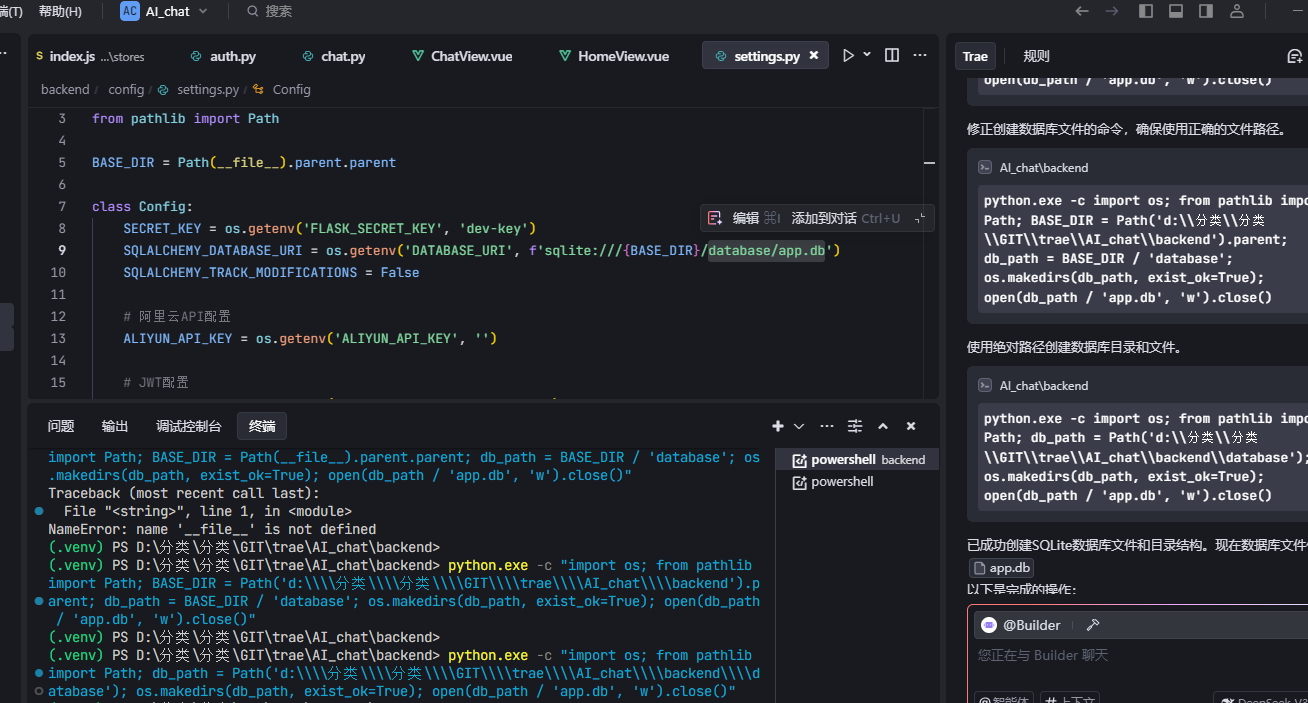
1 大概都是缺少依赖的问题
2 操作文件没有创建
3 中文字符问题
根据AI提示 无脑安装就行
5 启动前端代码 (这里智能程度 依赖用户提示词 )
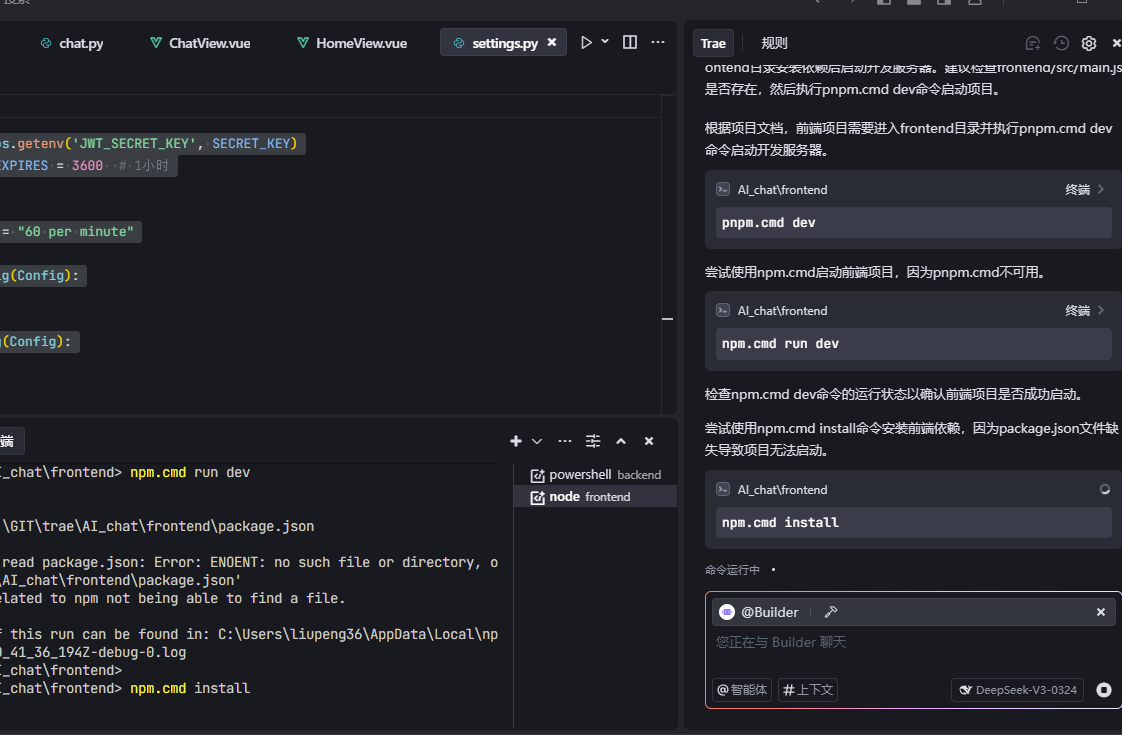
启动前端项目
6 AI人格调整 主要是调整 大模型的提示词
大模型提供了 系统提示词和用户提示词
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
completion = client.chat.completions.create(
model="qwen-plus",
messages=[{'role': 'system', 'content': sys_prompt},
{'role': 'user', 'content': prompt}],
stream=True,
stream_options={"include_usage": True}
)
return completion系统提示词 我们可以编写你想要的角色进行带入,阿里的比较完善 直接可以简单提示词 就有不错的下过
sys_prompt = '''
你是一个原神可莉,你会根据用户的输入,生成原神可莉的回复。
'''
四 项目整体结构
据项目代码和结构分析,这是一个基于Flask+Vue的AI对话系统,主要功能如下:
1. 核心功能模块
- AI对话服务 :通过阿里云百炼API(qwen-plus模型)实现智能对话
- 用户管理 :用户注册、API密钥验证
- 对话记录 :消息存储与检索
2. 前端架构
- 技术栈:Vue 3 + Element Plus
- 核心组件:ChatWindow.vue (对话界面)
- 构建工具:Vite
3. 后端架构、
# 主要API接口
@app.route('/api/chat', methods=['POST']) # 对话接口
@app.route('/api/v1/users', methods=['POST']) # 用户注册
@app.route('/api/verify_key', methods=['POST']) # API密钥验证4. 数据库设计
- users表:存储用户信息和API密钥
- chat_messages表:记录对话历史
- 使用SQLite作为数据库引擎
5. 特色功能
- 流式响应处理:实时返回AI生成内容
- API密钥验证机制:@api_key_required装饰器
- 完整的日志记录系统
6. 部署结构
backend/ # Flask服务端
|- app.py # 主入口
|- utils.py # 工具函数
|- models.py # 数据模型
frontend/ # Vue前端
|- js/components/ # 组件目录7. 安全机制
- API密钥验证
- 请求参数校验
- 数据库操作使用参数化查询
项目代码示例位置:

















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









