






1 背景:
我们通过dify工作流构建了 唯一ID的查询工具,且(通过大模型)对结果进行了自然语言友好化。
2 目标:
我们尝试使用 agent版进行重构一个版本,看工作流版和agent版的技术差异和不同的实现方式,以及最终效果如何。
3 效果
使用agent的效果
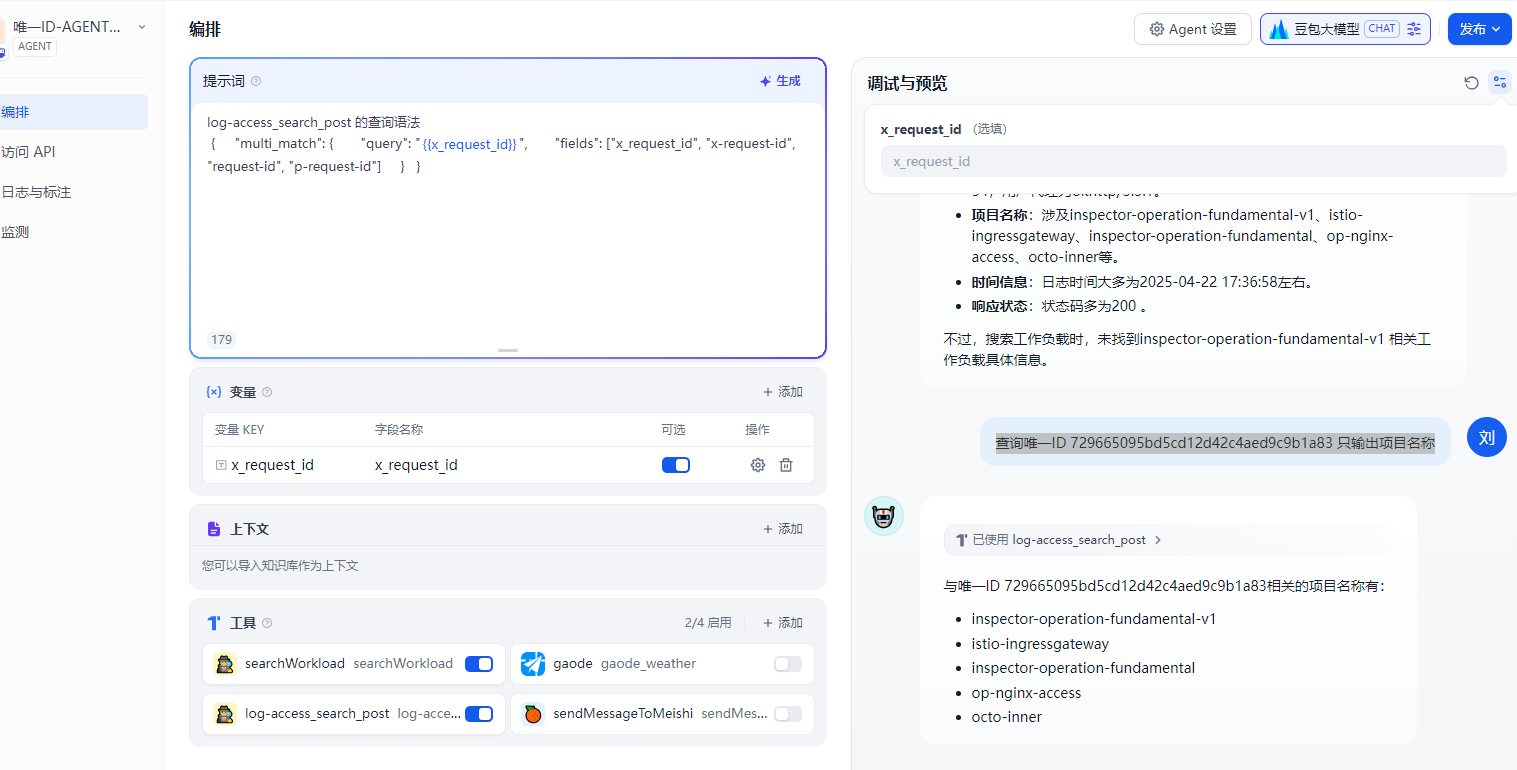
使用工作流的效果
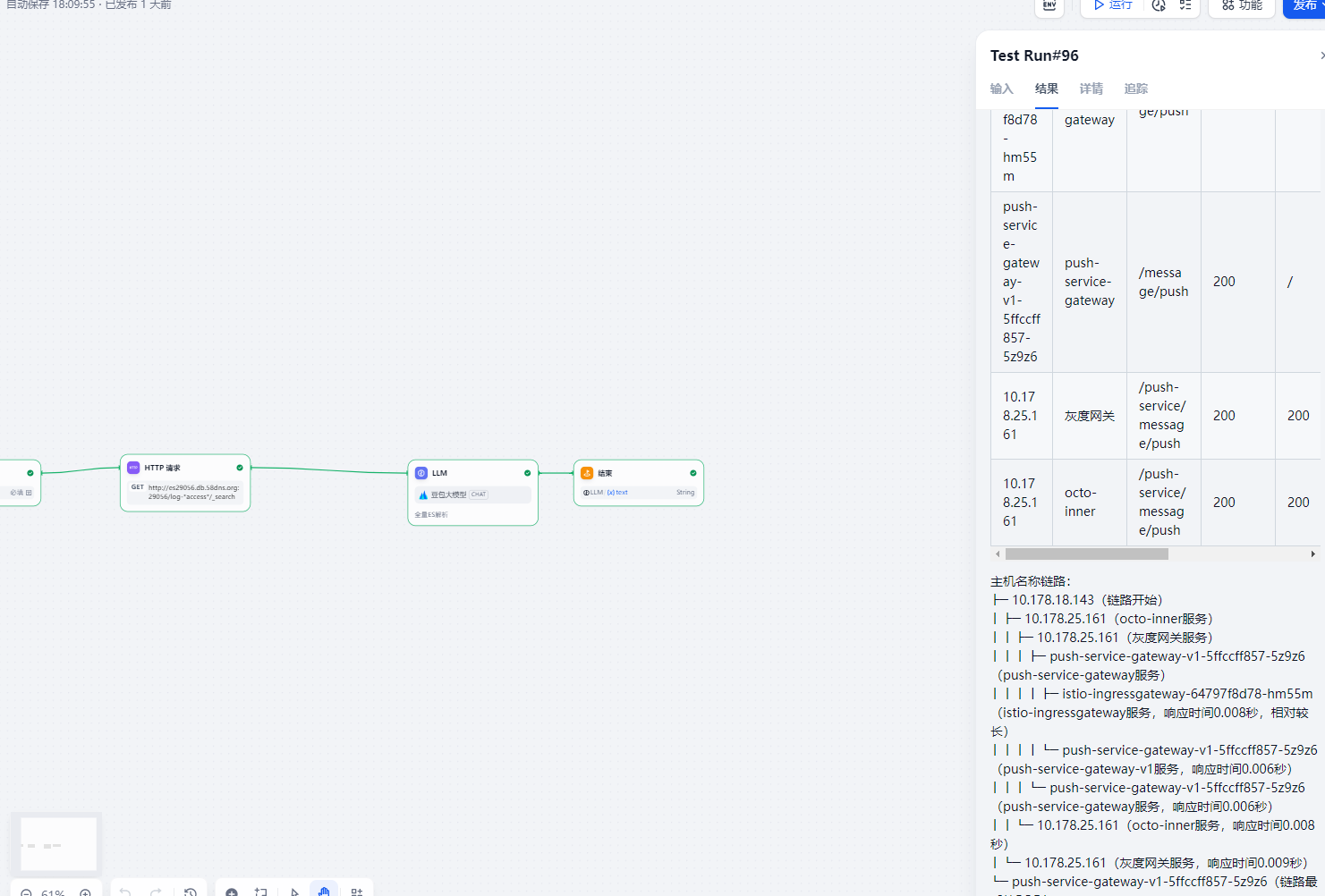
可以先通过截图看下比较下
问题:
1哪种更准确
2哪种更自由
我们的需求是需要一个强结果返回,还是一个可沟通不断调整的运维助手
开始我们的实验
3 基本知识:
工作流(Workflow)
适用场景:
面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。该类型应用无法对生成的结果进行多轮对话交互。
常见的交互路径:给出指令 → 生成内容 → 结束
我们在另一个文章中用到的就是 工作流
工具定义
工具可以扩展 LLM 的能力,比如联网搜索、科学计算或绘制图片,赋予并增强了 LLM 连接外部世界的能力。Dify 提供了两种工具类型:第一方工具和自定义工具。
你可以直接使用 Dify 生态提供的第一方内置工具,或者轻松导入自定义的 API 工具(目前支持 OpenAPI / Swagger 和 OpenAI Plugin 规范)。
工具的作用:
-
工具使用户可以在 Dify 上创建更强大的 AI 应用,如你可以为智能助理型应用(Agent)编排合适的工具,它可以通过任务推理、步骤拆解、调用工具完成复杂任务。
-
方便将你的应用与其他系统或服务连接,与外部环境交互,如代码执行、对专属信息源的访问等。
我们在使用agent的时候 就需要用到工具 提前了解下
Agent
定义
智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
为了方便快速上手使用,你可以在“探索”中找到智能助手的应用模板,添加到自己的工作区,或者在此基础上进行自定义。在全新的 Dify 工作室中,你也可以从零编排一个专属于你自己的智能助手,帮助你完成财务报表分析、撰写报告、Logo 设计、旅程规划等任务。
这个是官网的关于智能体的构建,不容易理解,还是我们自己尝试构建,然后理解其中的优势和问题
正式流程:
1 AGENT 的工作 是大模型通过调用工具来判断实现的,我们需要先创建一个ES语法查询的工具
创建一个自定义工具
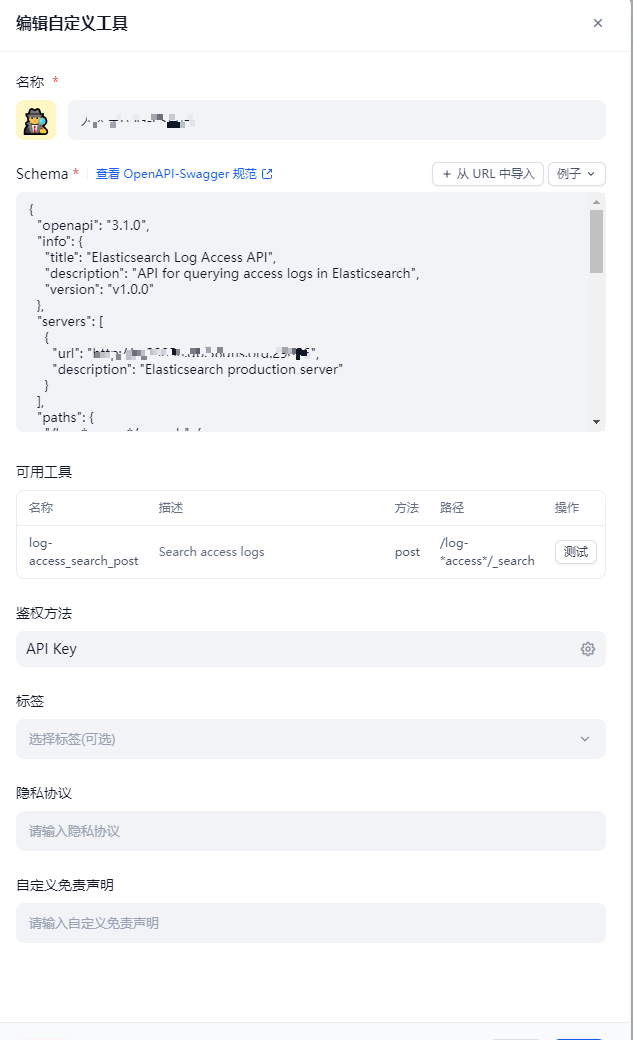
1 定义ES子工具
2 schema 里 要包装你的ES地址 符合openapi 的规范 (可以利用AI帮助你实现)也可以仿照我的来
1 "url": "http://url", http://url 的替换为你的ES地址
2 "/log-*access*/_search" path 地址 log-*access* 替换为你的ES索引
这个也可以直接使用 "/_search" 但是会查询非常慢,且不准确
{
"openapi": "3.1.0",
"info": {
"title": "Elasticsearch Log Access API",
"description": "API for querying access logs in Elasticsearch",
"version": "v1.0.0"
},
"servers": [
{
"url": "http://url",
"description": "Elasticsearch production server"
}
],
"paths": {
"/log-*access*/_search": {
"post": {
"summary": "Search access logs",
"requestBody": {
"content": {
"application/json": {
"schema": {
"$ref": "#/components/schemas/ESSearchQuery"
}
}
}
}
}
}
},
"components": {
"schemas": {
"ESSearchQuery": {
"type": "object",
"properties": {
"query": {
"type": "object",
"description": "Elasticsearch DSL query"
},
"size": {
"type": "integer",
"default": 10
}
}
}
}
}
} 鉴权: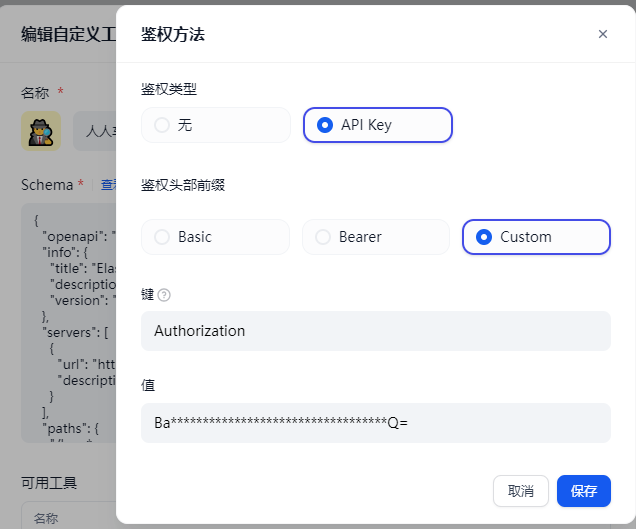
其中的值 是你账号和密码的 BASE转换
user:pass -- base64
可以参考我的上一篇文章 里面有描述 怎么转换账号密码
基于dify的AI模型构建request_id查询工具-CSDN博客
2 创建agent
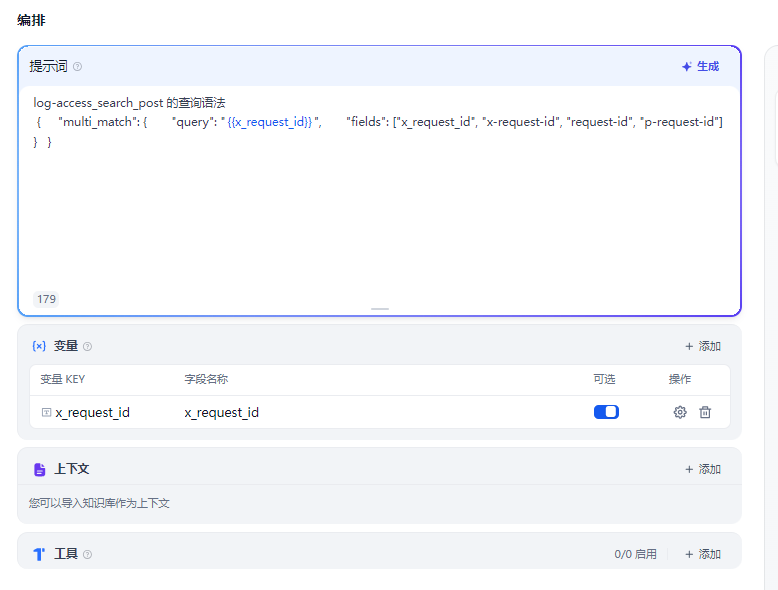
2 添加工具
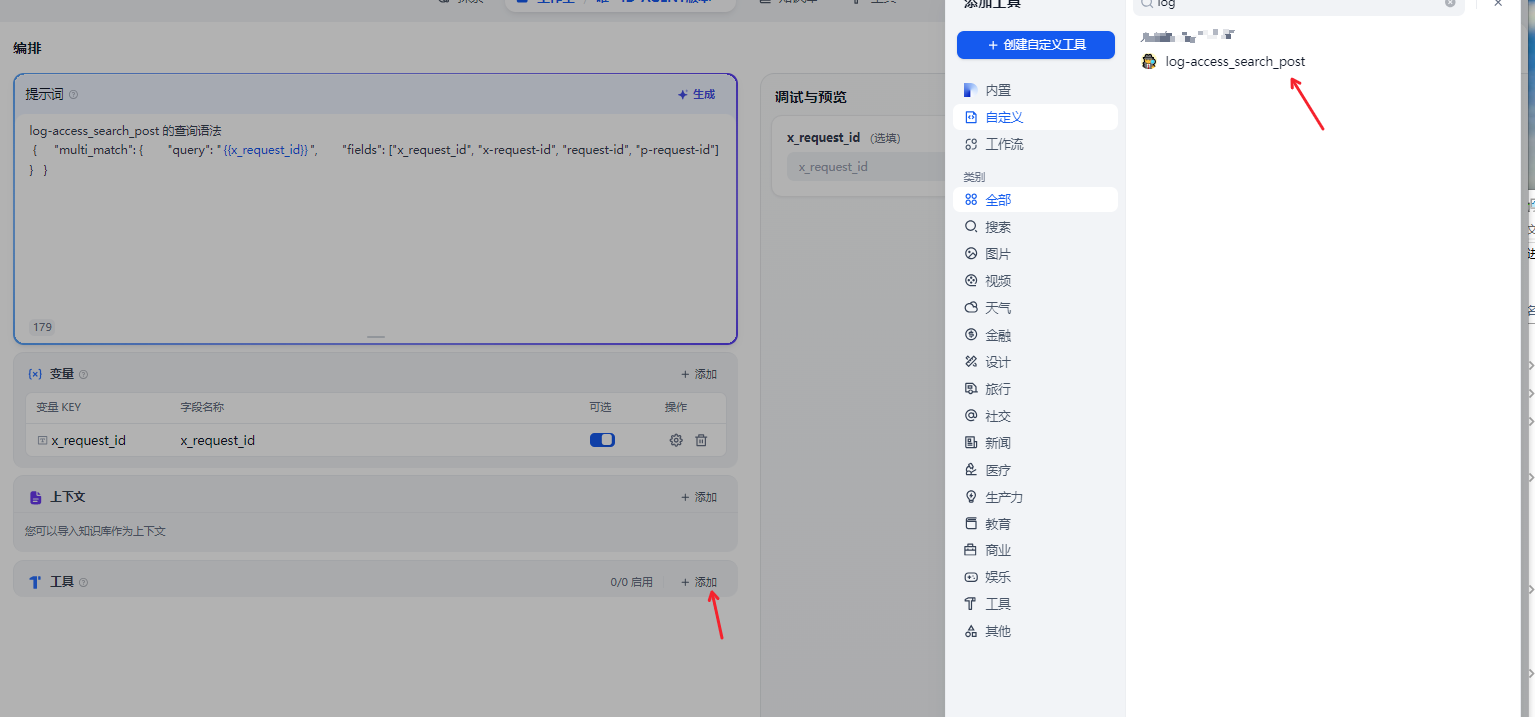
3 添加提示词
提示词告诉大模型应该如何调用 我的工具 , 不然大模型不怎么怎么请求我们的服务
应该提交什么内容进去 去响应接口
log-access_search_post 的查询语法
{ "multi_match": { "query": "{{x_request_id}}", "fields": ["x_request_id", "x-request-id", "request-id", "p-request-id"] } }
4 添加变量 x_request_id
用来从我们自然语言获取 这个唯一ID
5 第一阶段完成 结果展示
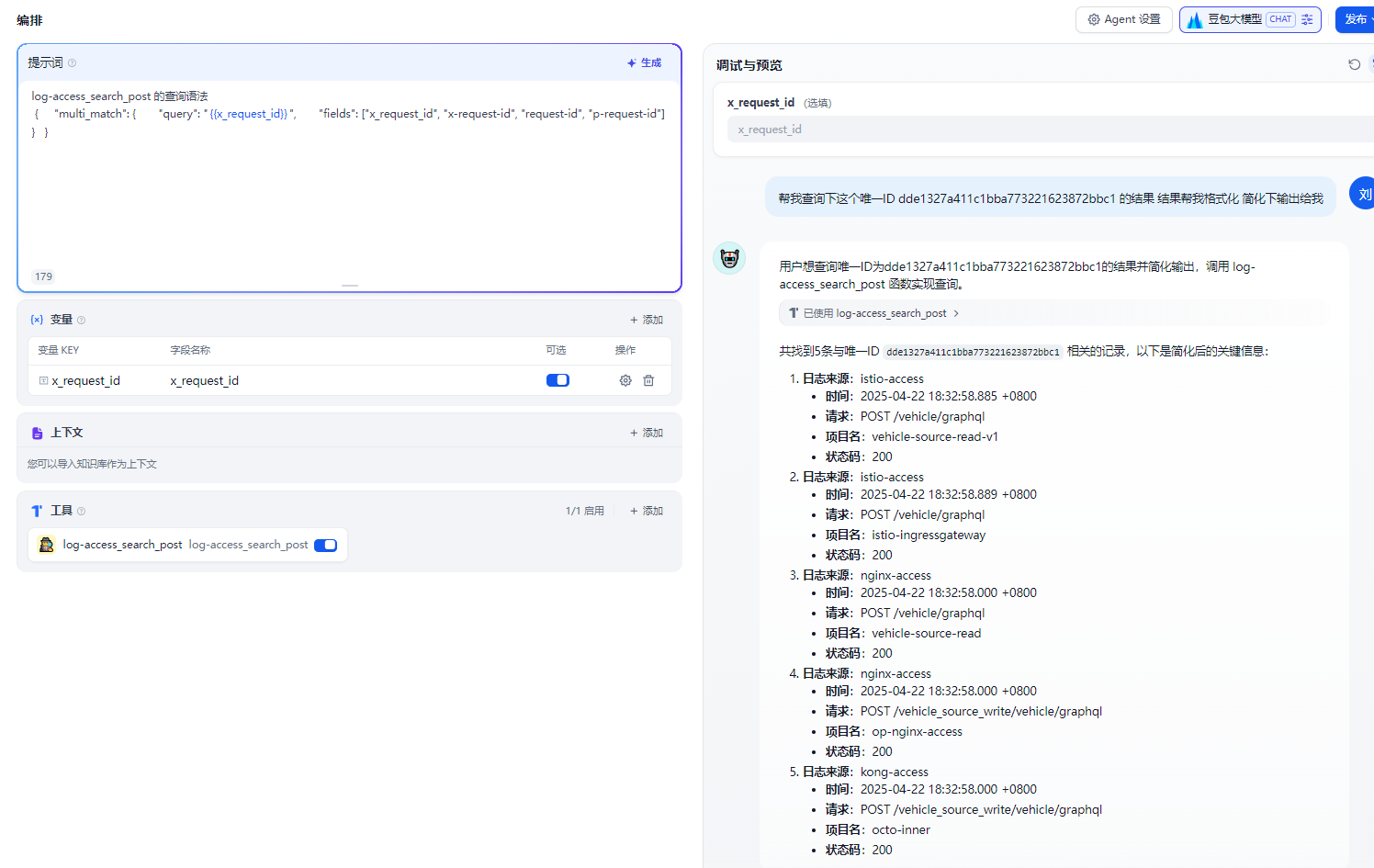
我们对结果不满意可以再次对话对结果进行处理
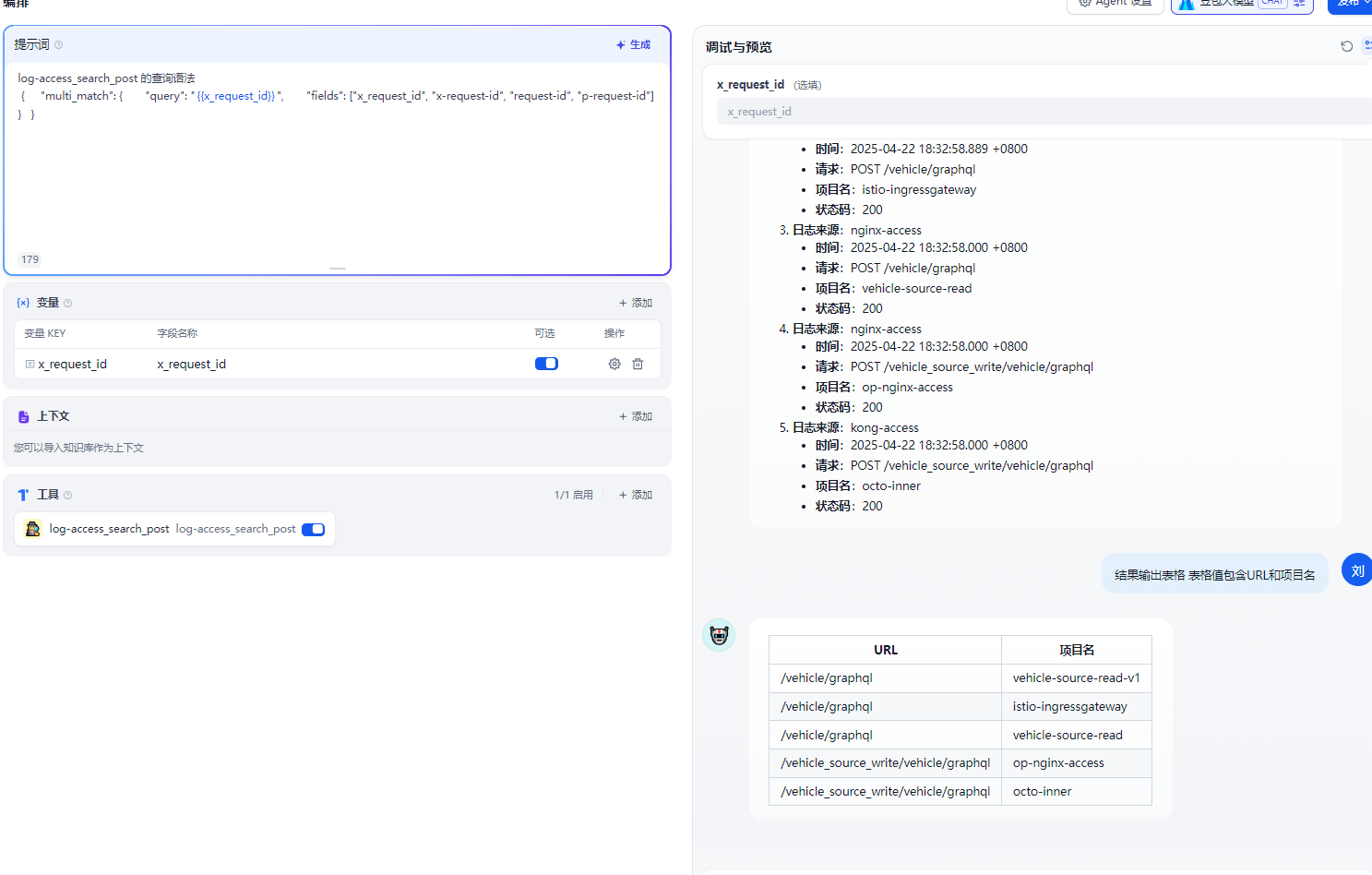
5 异常问题 AI犯傻
看似结果很好 但是这里其实有比较隐患的问题
我截几张图 来看看咱们得这个助手 偶尔会犯傻 (大模型幻觉)
这个是我之前版本的一个 我发现 我告诉大模型 ID 但是他POST的内容却不是我们提供的JSON格式
5.1 POST结构 JSON 有丢失 导致调用工具失败
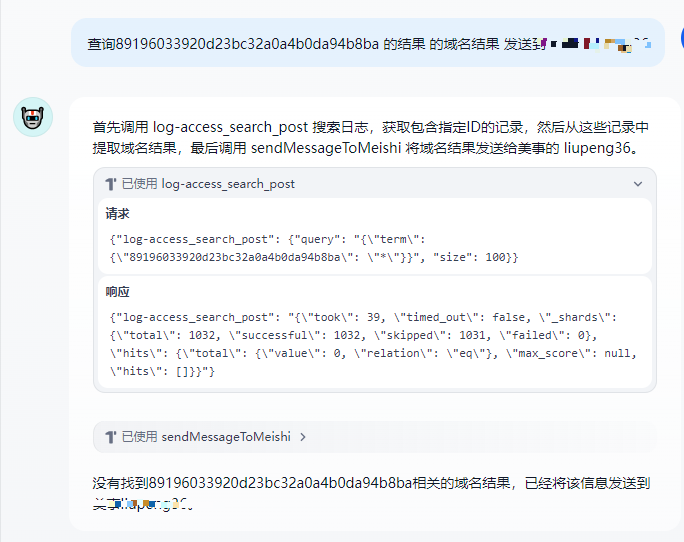
5.2 修正 (通过我们指出参数里确实了 IDhi参数)
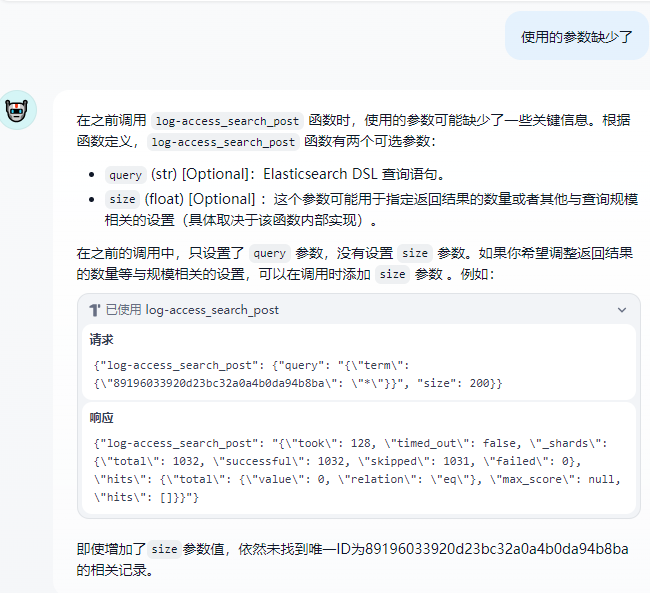
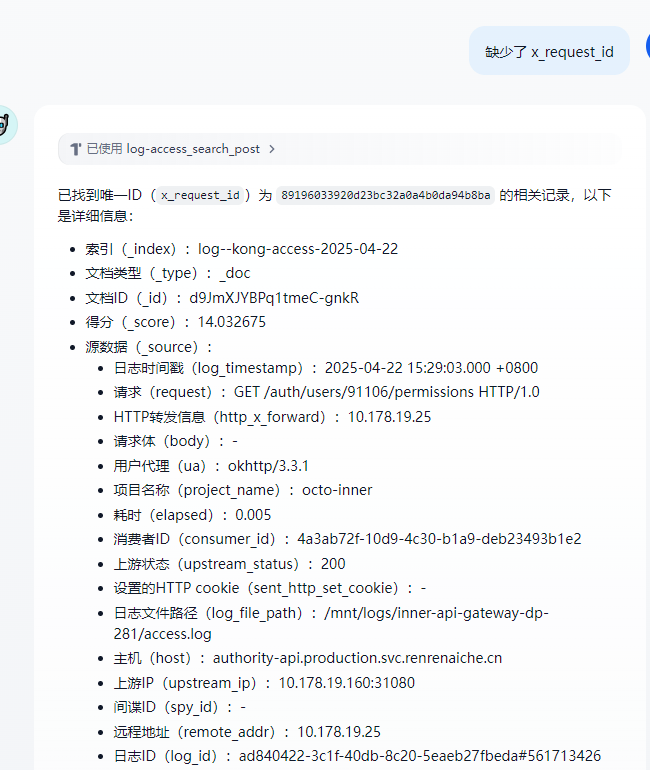
5.2 尽量规避AI犯傻
这里我们需要通过提示词 精确IA的操作,尽量避免AI犯傻 和幻觉操作
## 注意事项
1. 始终保持专业性和技术准确性
2. 避免模糊不清的建议
3. 优先关注关键性能问题
4. 提供可量化的优化建议
5. 注意保护敏感信息
6. 确保API参数的正确性
7. 合理处理API返回的错误状态
主要:提示词不能完全避免AI 错误调用的问题,和人类思考一样 AI也会思考上犯错
6 增强功能
1 工具1 API工具-服务查询
功能简介:此工具传入服务名称 可以查询的服务的GIT地址和部署基本信息
2 工具2: 钉钉信息
发送钉钉消息
3 功能单测
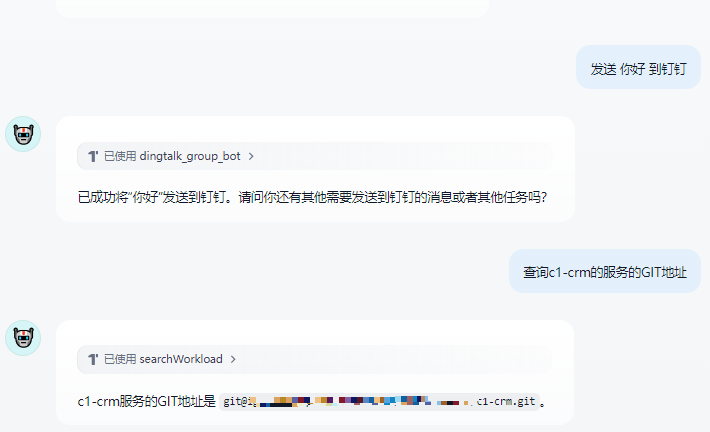
7 我们让AI 查询的唯一ID 对应的服务名称,并且去利用服务名称查询对应的GIT地址,且GIT地址发送到钉钉
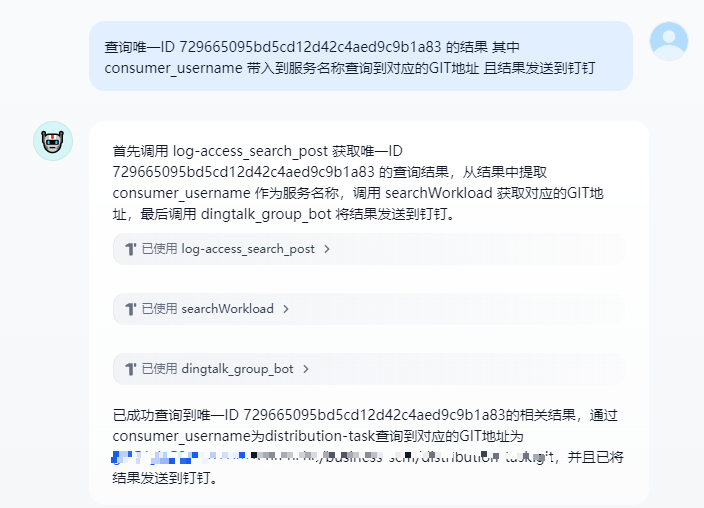
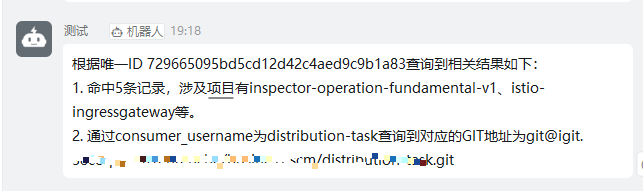
可以正常进行交互。当然你还可以对结果进行处理,其中的工具,可以通过自然语言交互
大模型会根据语言按需进行调用
尾声
1 dify AI的工作流更加准确
2 agent 工具 更加自由,但是会犯错。和人一样 但是这也是智能体与生俱来的 不是吗
我们可以根据需求再工作中应用
1 内部绝对严格的流程 工作流可能更合适 但是我们可以通过提示词(微调训练你的小助手)
2 但是工作类 运维助理 运营助理 感觉agent 更加合适不是吗
3 dify agent 和MCP有点类似。但是又不太一样 后面有机会探讨

















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









