






1、什么是pit
官方对Point in time的定义:
A search request by default executes against the most recent visible data of the target indices, which is called point in time.pit,又称时间点api,我们可以简单理解为就是一个快照,是索引在某个时刻点的状态,这个状态被保存了下来,使用pit的检索请求,就是在索引对应的保存的这个【状态】中进行检索,这个【状态】就是一个上下文。
2、创建一个pit
创建pit我们需要指定索引以及pit的有效时间:
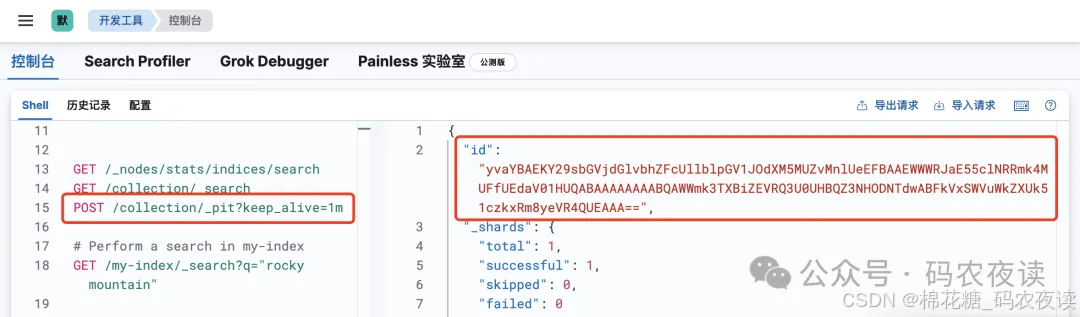
命令行:
POST /collection/_pit?keep_alive=1m在创建pit的这一刻,es就为该索引创建了一个对应这个时刻的上下文,也就是保存了一个状态:
这样,一个pit就创建成功了。
3、使用pit进行检索
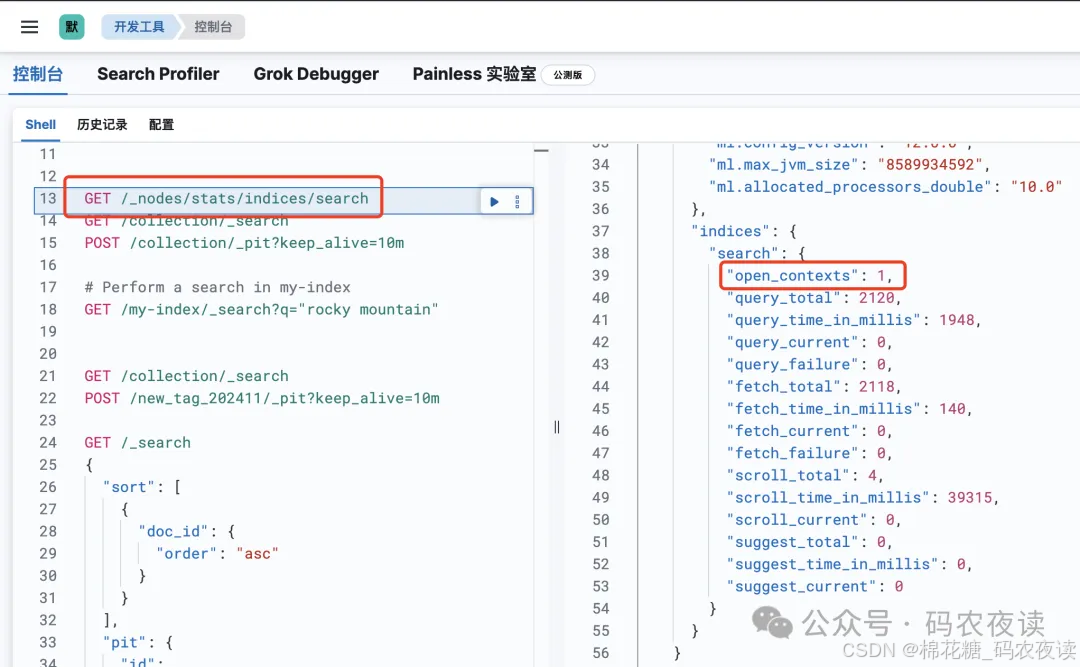
首先,我的测试索引中,在创建pit之前共8条数据,数据结构如下:
{ "user": "双榆树-张三","message": "今儿天气不错啊,出去转转去","uid": 2,"age": 20,"city": "北京","province": "北京","country": "中国","address": "中国北京市海淀区","location": {"lat": "39.970718","lon": "116.325747"}}
对于pit的使用,需要注意,执行检索时:
-
不需要指定索引。
-
每个检索请求都会返回pit_id,当前检索要使用上一次检索返回的pit_id。
-
keep_alive设置的时长不是整个数据检索的时长,只要够下次检索的时长即可。
官方有一个说明如下:

但是从我实际测试看,这个id在创建后,每次search返回的pit_id都是同一个值(es版本:8.17)。
检索语句为:
GET /_search{"sort": [{"uid": {"order": "asc"}}],"pit": {"id": "yvaYBAEKY29sbGVjdGlvbhZFcUllblpGV1JOdXM5MUZvMnlUeEFBAAEWWWRJaE55clNRRmk4MUFfUEdaV01HUQABAAAAAAAACwMWWmk3TXBiZEVRQ3U0UHBQZ3NHODNTdwABFkVxSWVuWkZXUk51czkxRm8yeVR4QUEAAA==","keep_alive": "1m"},"size": 2}
在这个检索语句里也有keep_alive参数,我在研究pit的过程中当时就有疑问,这个keep_alive和创建pit的keep_alive是怎样的关系,实测的结果是这样的,上面说了,pit_id在整个search过程中都是一个,id值是没有变化的,search中的keep_alive会一直延续这个pit的有效时间,当search结束时,过了keep_alive设定的时间,上下文并没有马上关闭(实测时有效时间设定的1分钟),又过了一会才关闭。
现在我们给索引再加2条数据到10条:
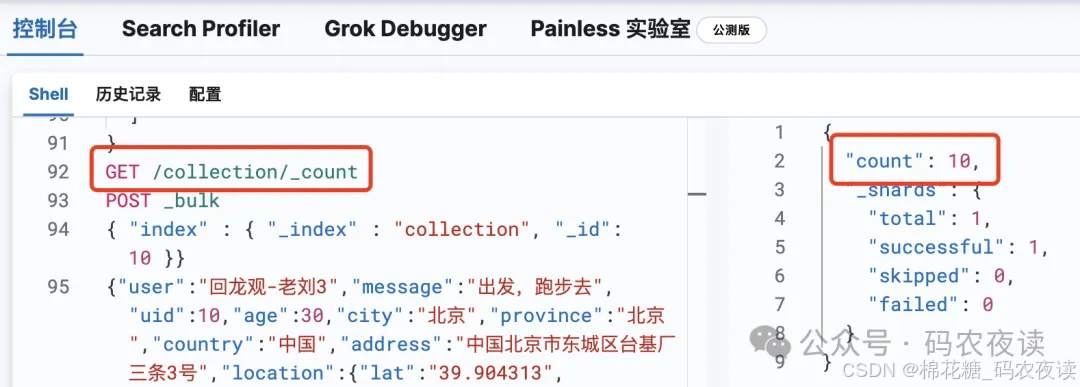 之后再次执行pit检索:
之后再次执行pit检索:
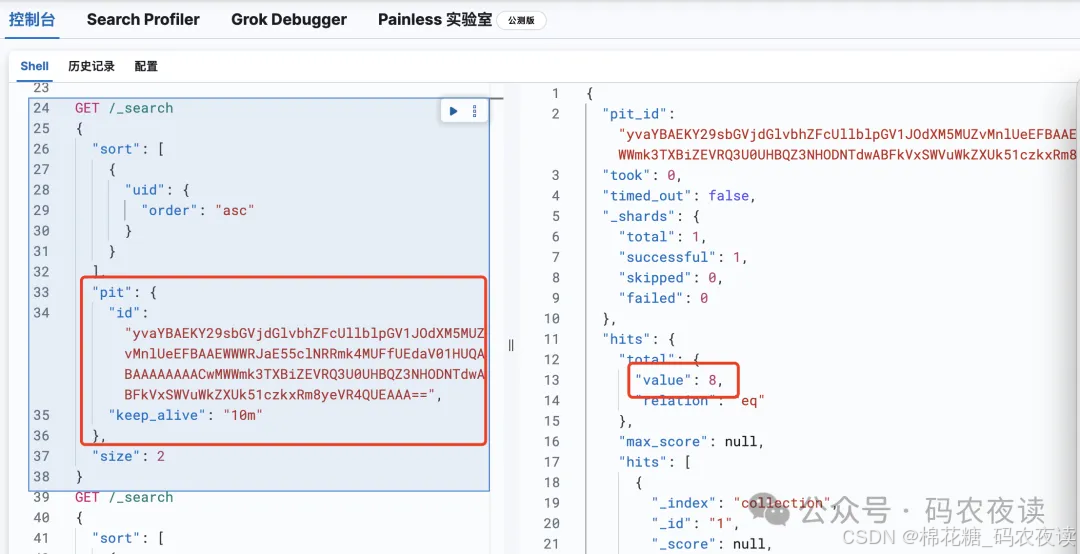
检索结果仍然是8条,【这就是pit的意义】,虽然当前索引的数据已经发生了变化,但他是不影响pit的检索结果的,因为这个变化发生在创建pit之后,这个功能点,不仅仅针对数据的写入,对于删除、更新都有是有效的。
4、删除pit,清除上下文
在使用pit检索完成后,需要删除pit,关闭上下文:
DELETE /_pit{"id":"yvaYBAEKY29sbGVjdGlvbhZFcUllblpGV1JOdXM5MUZvMnlUeEFBAAEWWWRJaE55clNRRmk4MUFfUEdaV01HUQABAAAAAAAAKlIWbWFxaDB5eG9RYy1iendZaTZOOVlfQQABFkVxSWVuWkZXUk51czkxRm8yeVR4QUEAAA=="}
执行该命令后,上下文将会被删除:
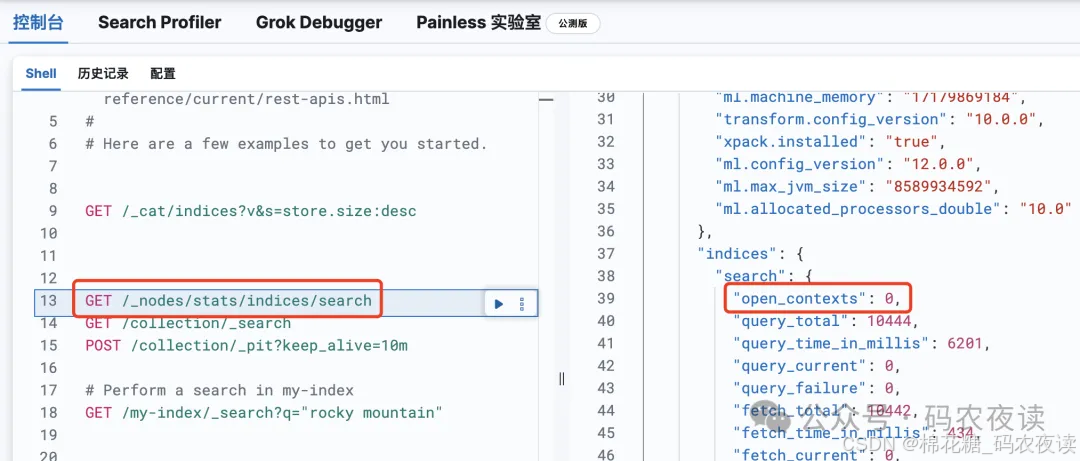 当然,不执行手动删除操作也是ok的,pit超时之后也会自动关闭上下文,但是为了保险起见,最好是在检索完成后,手动关闭pit。
当然,不执行手动删除操作也是ok的,pit超时之后也会自动关闭上下文,但是为了保险起见,最好是在检索完成后,手动关闭pit。
5、关于pit功能点的思考
从上面介绍pit的使用方法看,pit的检索和滚动查询是极其类似的,滚动查询也是先创建滚动id,也设定有效时间,在之后的查询中不断的更新scroll_id为上一次滚动查询的id,过程完全一样,那么利用【search_after+pit】与【scroll】查询这两个全量检索的技术方案,哪个更优,我们应该怎么选?我现在没有答案,针对这个问题我抽时间再研究一下,有结果后再写一篇文章分享给各位小伙伴们。
关于pit测试的代码(golang)小伙伴们可以参考:
https://github.com/liupengh3c/career欢迎各位同学关注公众号~~~~~~~~~~~~~~~~。


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









