






 本文介绍了书生·浦语大模型实战营的首课内容,由陈恺老师讲解,详细阐述了InternLM2的开源历程、模型架构、强化功能及应用,涵盖了高质量语料、预训练、微调等全链条开源体系。
本文介绍了书生·浦语大模型实战营的首课内容,由陈恺老师讲解,详细阐述了InternLM2的开源历程、模型架构、强化功能及应用,涵盖了高质量语料、预训练、微调等全链条开源体系。
本篇是书生·浦语大模型实战营(第二期)第一节课的笔记,实战营链接在这里也一并给出。
课程笔记
本次课程由陈恺老师讲授,主要介绍书生·浦语大模型全链路开源体系,以InternLM2体系为重点进行介绍。课程从以下几点展开:
-
开源历程:2023年6月7日InternLM千亿参数语言大模型发布;24年1月17日InternLM2开源;
-
InternML2模型体系:
(1). InternLM2-Base: 模型基座,包括7B和20B两个版本;
(2). InternLM2: 在Base基础上,在多个能力方向进行了强化;
(3). InternLM2-Chat: 在Base基础上,优化对话交互,chat功能突出; -
InternLM2亮点:
(1). 超长上下文:模型可容纳20万Token上下文;
(2). 综合性能提升:在推理、数学、代码能力比肩ChatGPT;
(3). 语言能力强劲:精准指令跟随,并可实现结构化创作;
(4). 工具调用能力:支持工具多轮调用,支持复杂智能体搭建;
(5). 数理能力:内生计算能力强劲,数理能力和数据分析能力比肩GPT4; -
模型应用:
InternLM2采用全链条开放,全面助力大模型在各行业的应用。下图显示了从模型到应用的典型流程以及书生·浦语全链条开源开放体系:
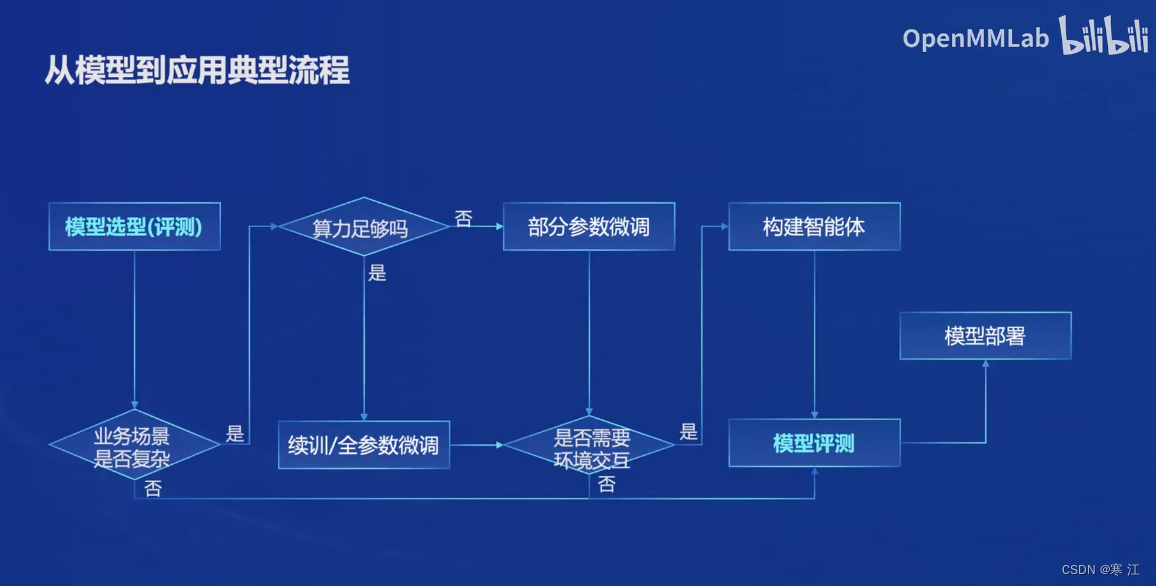
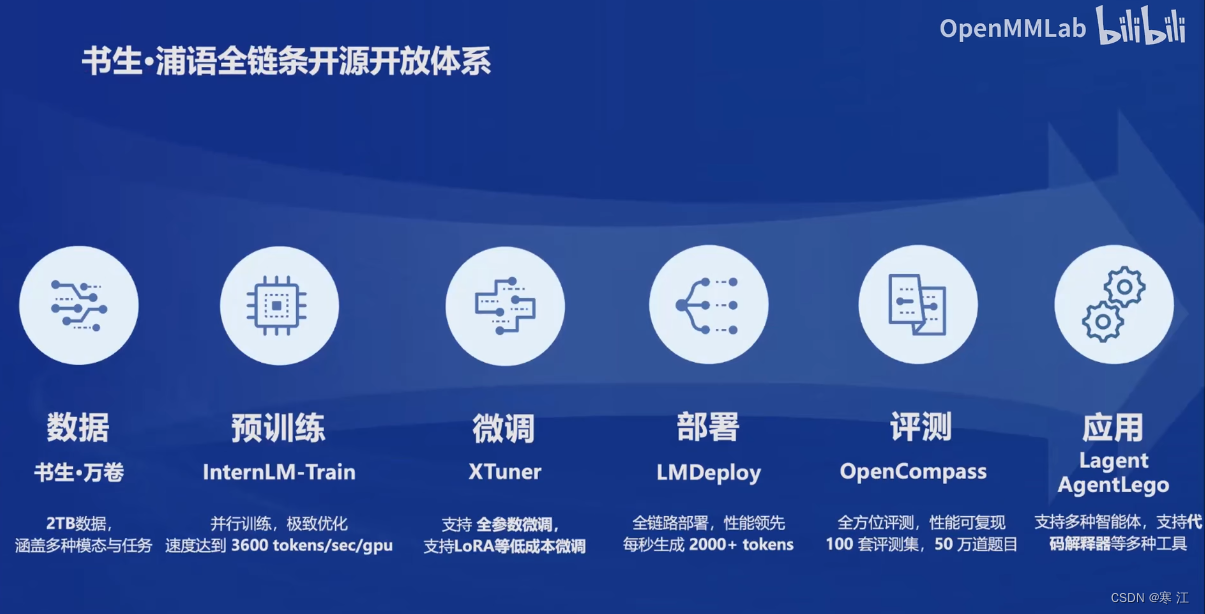
下面从六个方面具体介绍开源开放体系
(1). 高质量语料数据:OpenDataLab

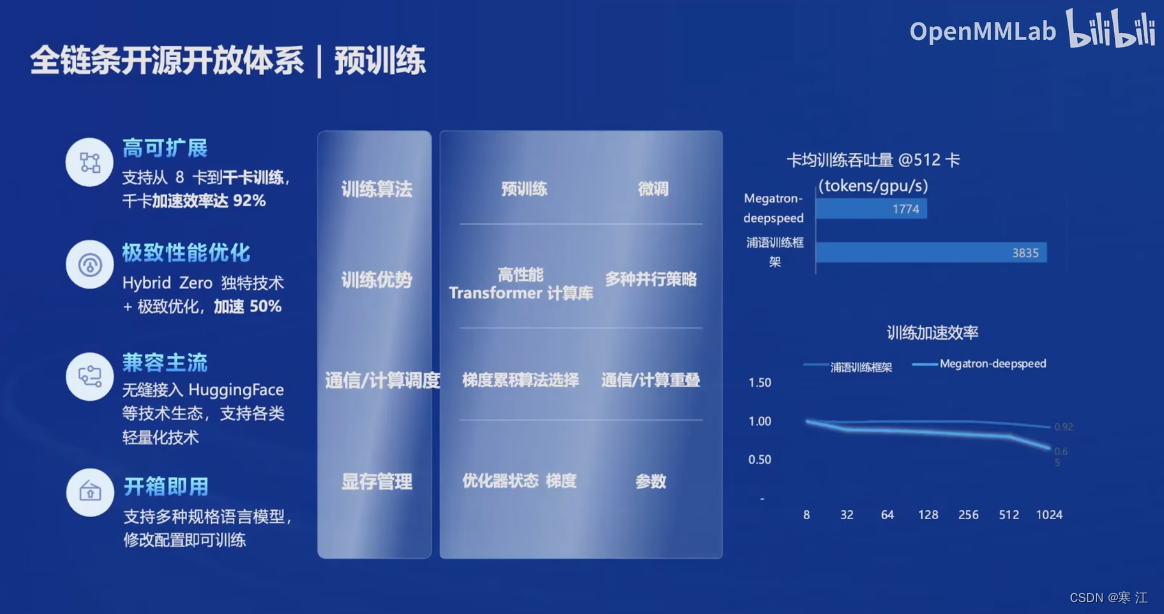
(2). 预训练
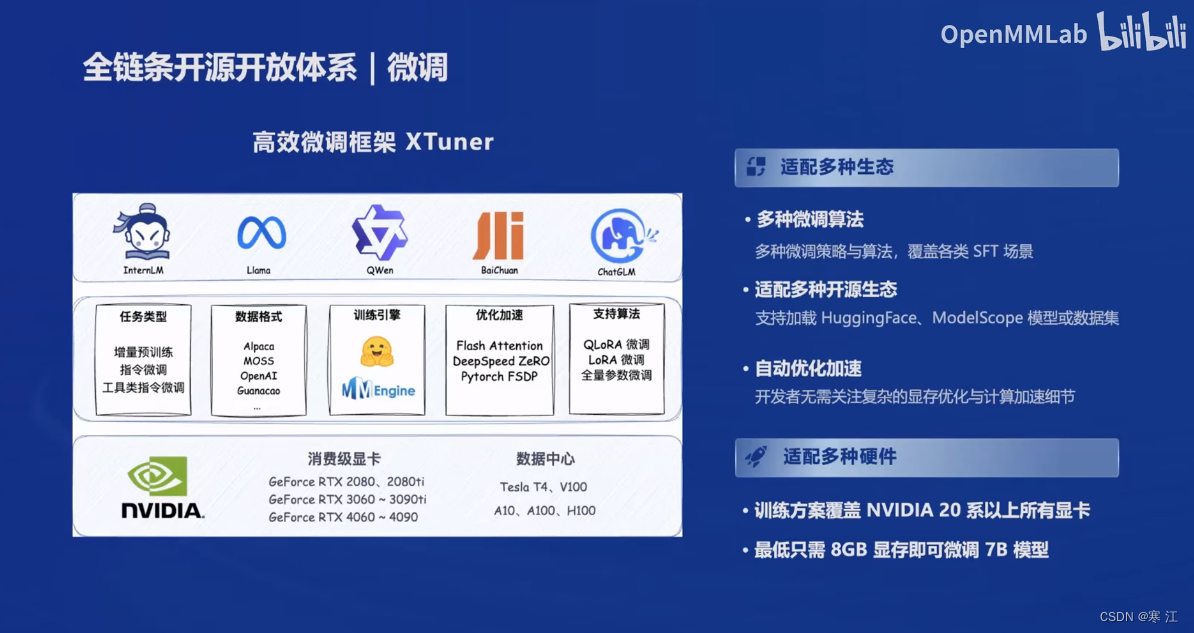
(3). 高效微调框架XTuner
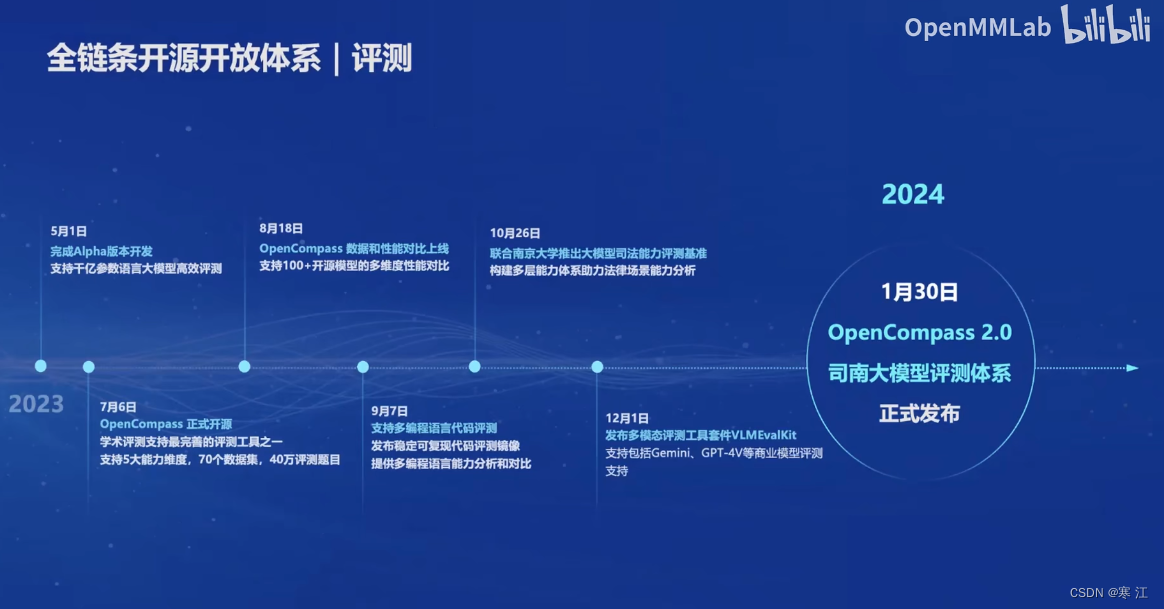
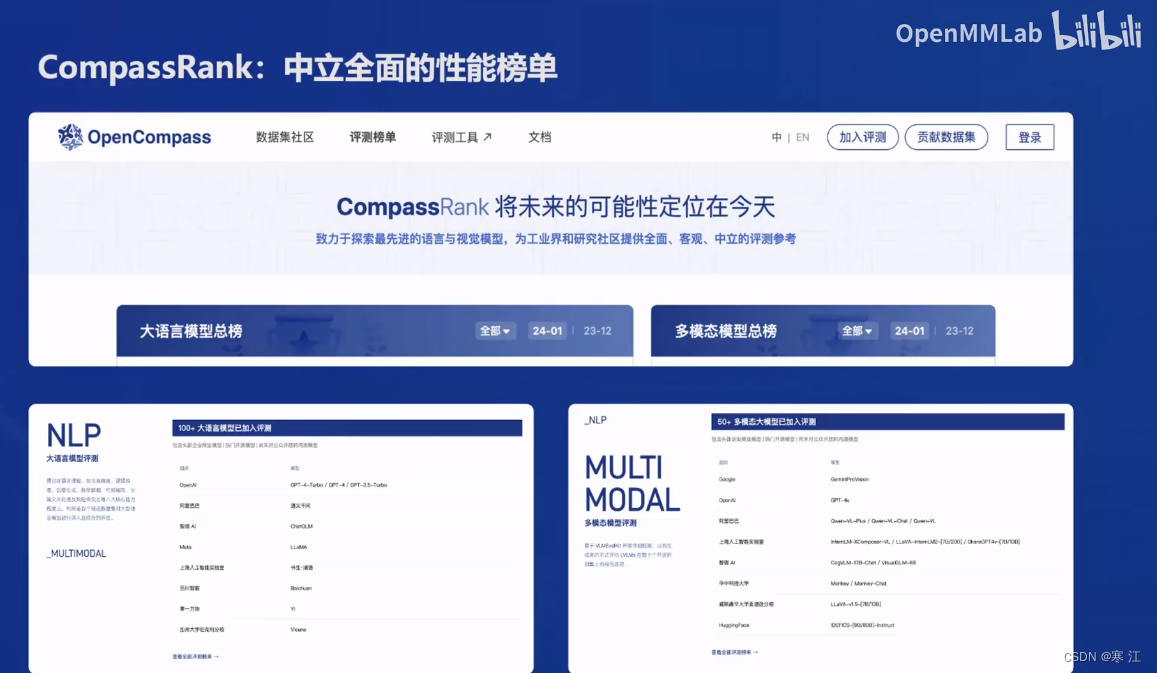
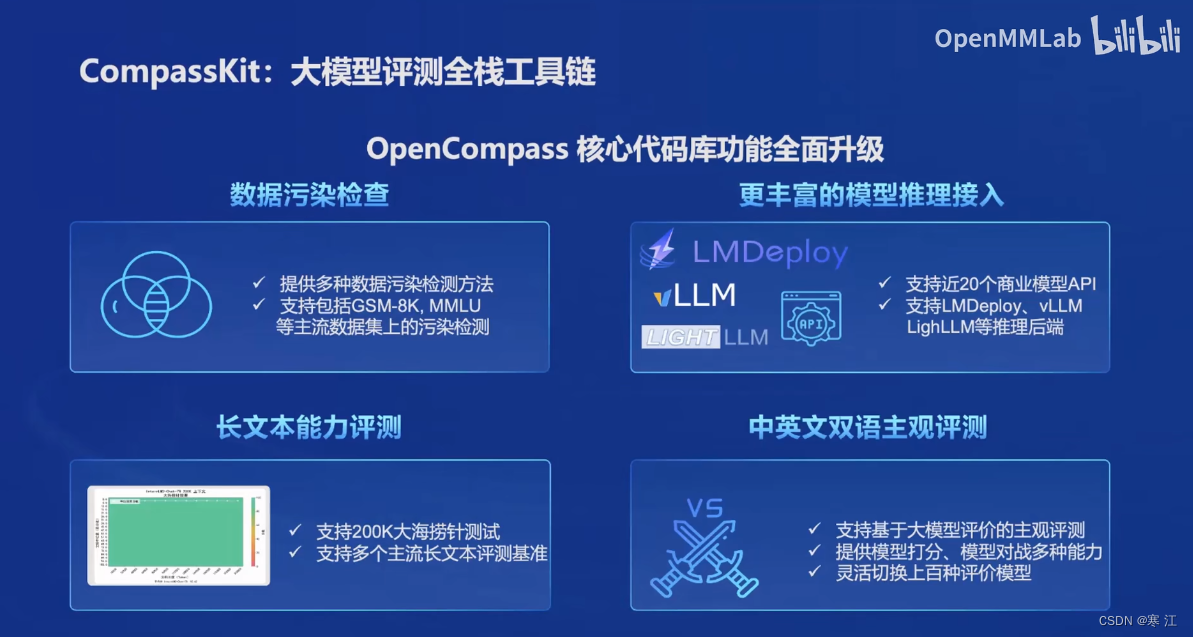
(4). 司南评测体系
(5). 使用LMDeploy进行模型部署
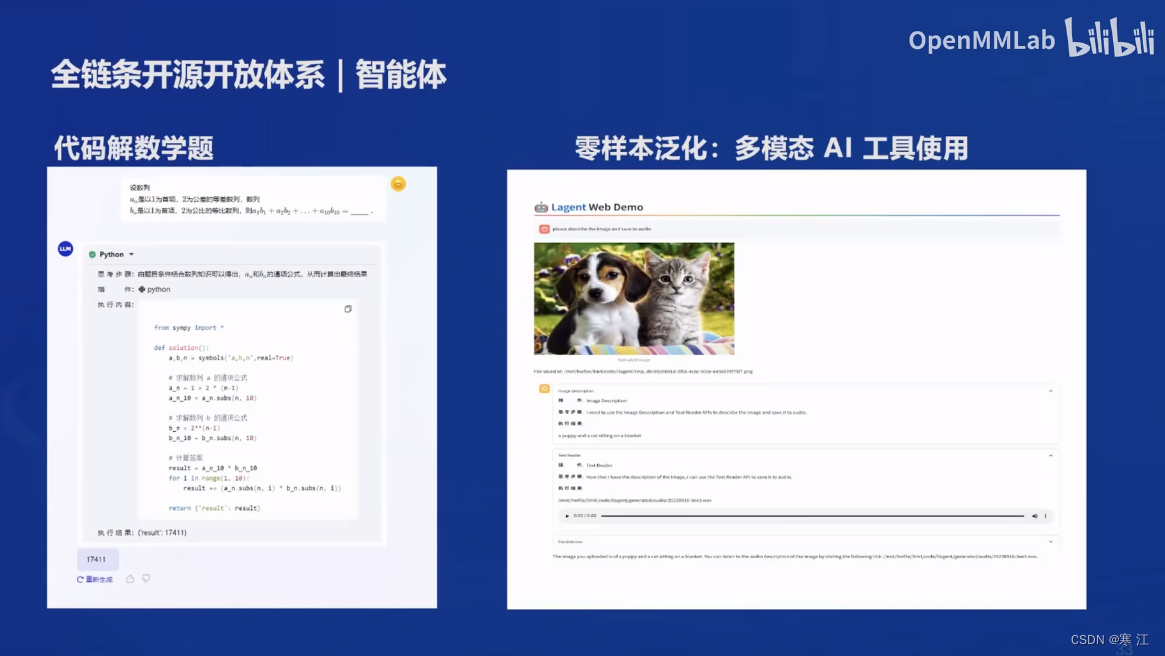
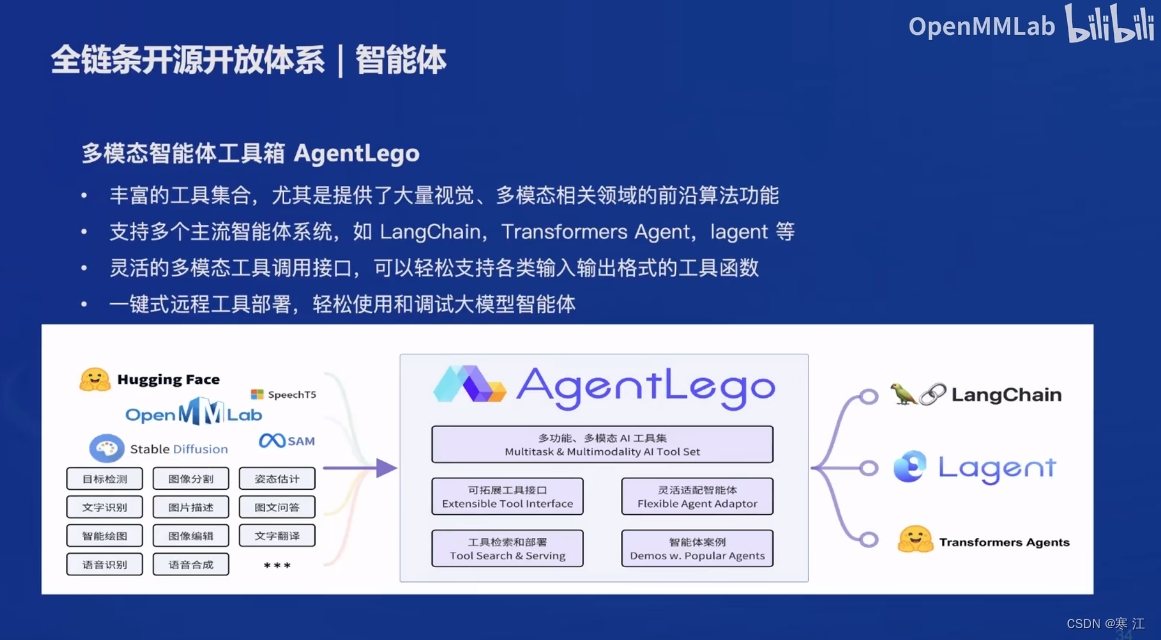
(6). 智能体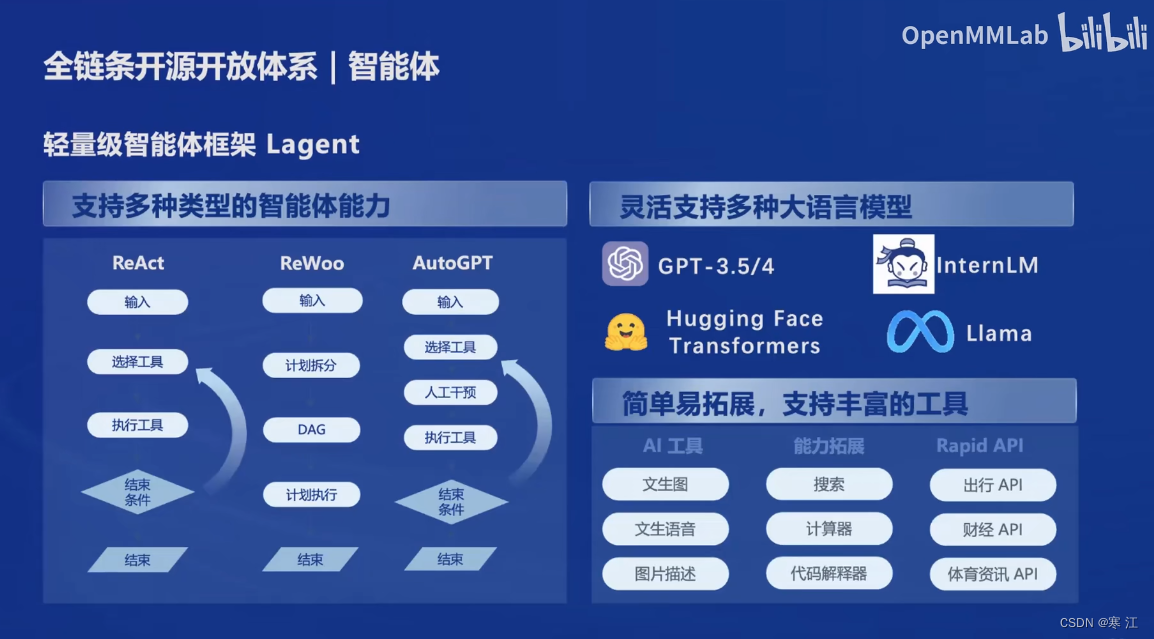















 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









