







1、DPCM编解码原理
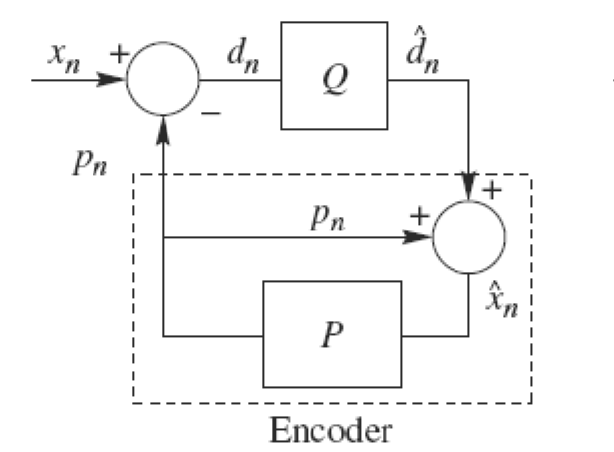
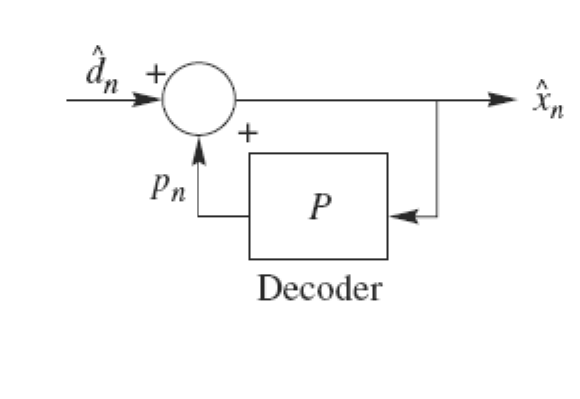
DPCM是差分预测编码调制的缩写,是比较典型的预测编码系统。在DPCM系统中,需要注意的是预测器的输入是已经解码以后的样本。之所以不用原始样本来做预测,是因为在解码端无法得到原始样本,只能得到存在误差的样本。因此,在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和
量化器的优化设计。
2、DPCM编码系统的设计
在本次实验中,我们采用固定预测器和均匀量化器。预测器采用左侧、上方预测均可。量化器采用8比特均匀量化。本实验的目标是验证DPCM编码的编码效率。首先读取一个
256级的灰度图像,采用自己设定的预测方法计算预测误差,并对预测误差进行8比特均匀量化,还可对预测误差进行1比特、2比特和4比特的量化设计。
在DPCM编码器实现的过程中可同时输出预测误差图像和重建图像。将预测误差图像写入文件并将该文件输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。将原始图像文件输入输入Huffman编码器,得到输出码流、给出概率分布图并计算压缩比。最后比较两种系统(DPCM+熵编码和仅进行熵编码)之间的编码效率(压缩比和图像质量)。
二、量化
需要决定的参数
1、 量化区间的数目
2、 决策边界(判决门限)
3、 重构水平
4、 量化区间索引的码字(量化码字)
量化器的设计是码率与失真之间的折中, 为了降低编码的比特数,需要减低量化区间的数目,但是会带来更大的误差。
性能受率失真理论控制:1、给定允许失真,求最小码率的量化器 ;2、 给定码率,求最小失真的量化器。
均匀量化: 均匀量化器只对均匀分布信源是最佳的。

三、主要代码
void DPCM(unsigned long w,unsigned long h,unsigned char * y,unsigned char * q,unsigned char *yy) //y为原始输入,yy为重现,q为误差的量化值
{
unsigned long i,j;
unsigned char P;
for(j=0;j<h;j++)
{
for(i=0;i<w;i++)
{
if(i==0) //判断是否为第一列的,是的话用128作为预测值
P=128;
else
P=yy[j*w+i-1];//否则以左侧重建值作为预测值
q[j*w+i]=(y[j*w+i]-P)/2+128;//对预测误差进行8bit量化,数值的变化过程为[-255,255]-->[-127,127]-->[1,255]
yy[j*w+i]=(q[j*w+i]-128)*2+P;//进行反量化,经过运算得到重建值
}
}
}四、实验结果
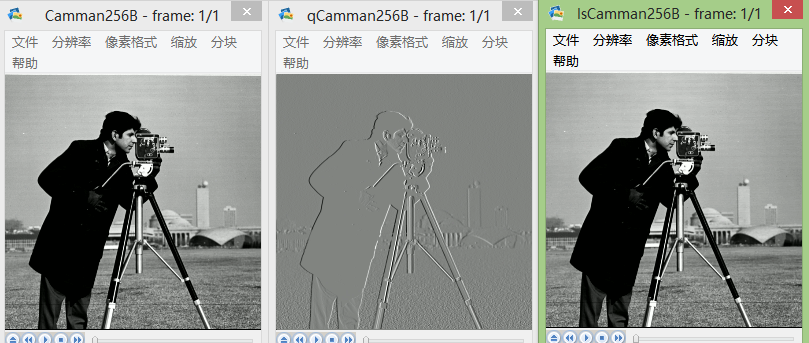
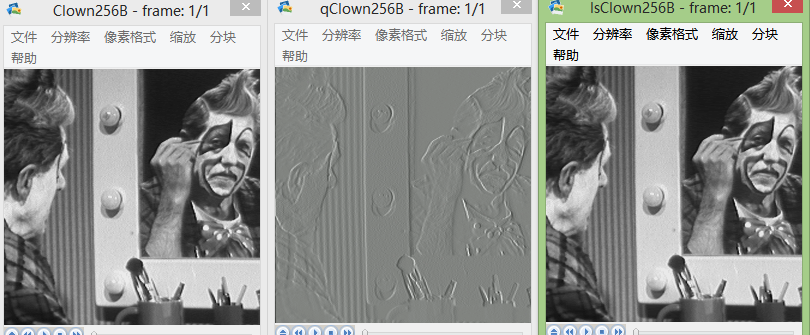
选取10张图片进行实验。由于其中三张像素较大,不好截图展现效果,下面截图其他7张的效果图。
图片从左到右一次为:原始图像、预测误差图像、重现图像。
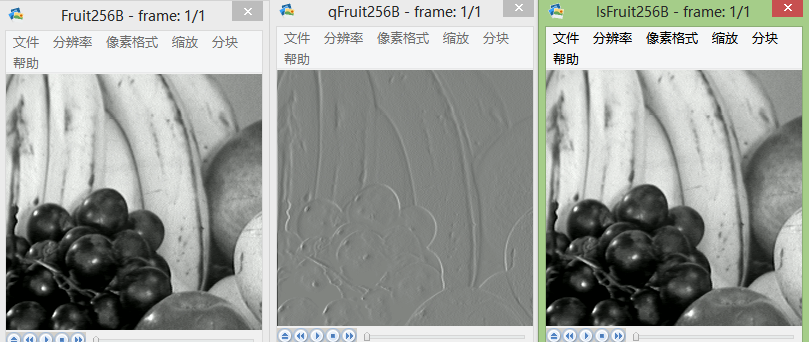
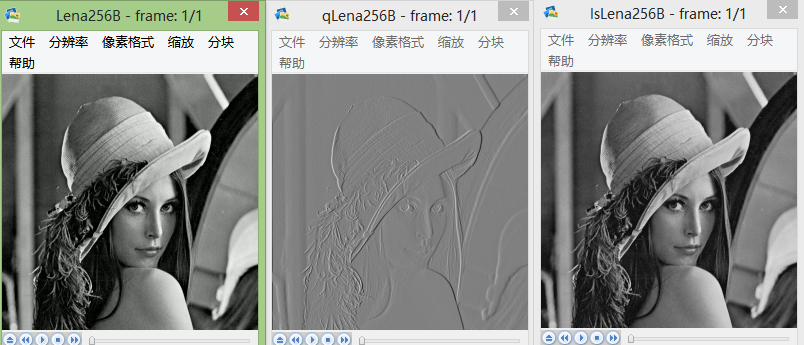
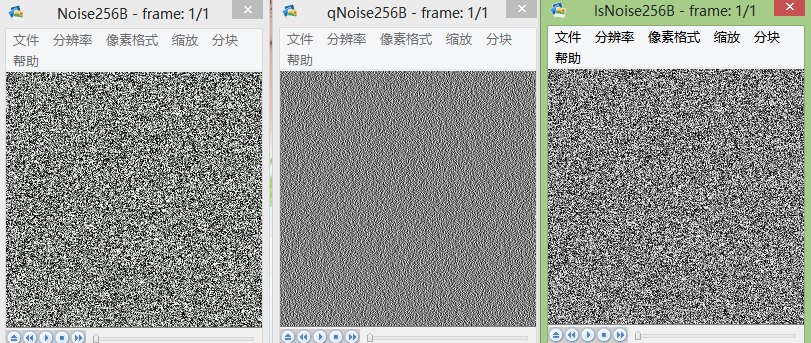

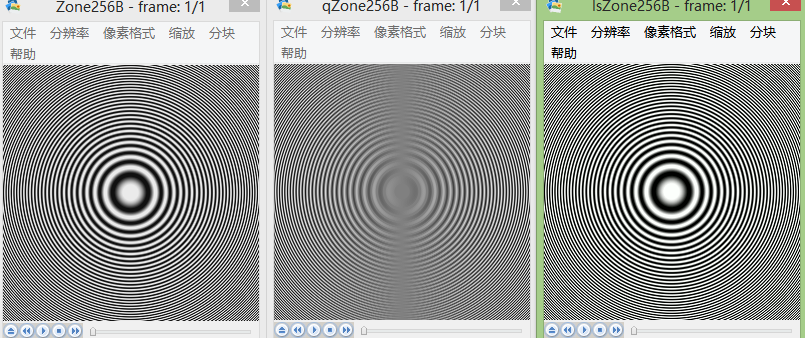
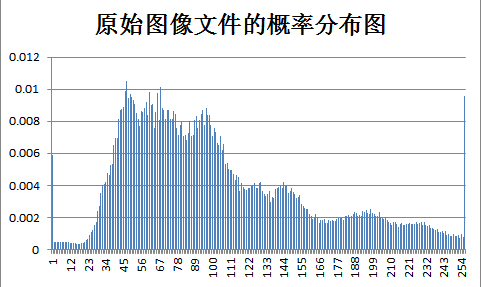
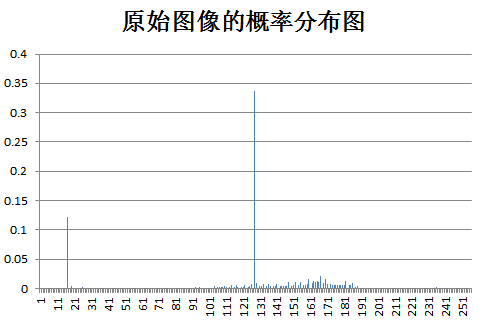
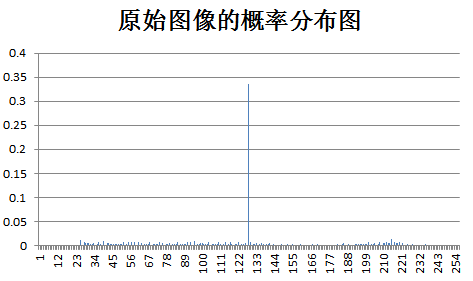
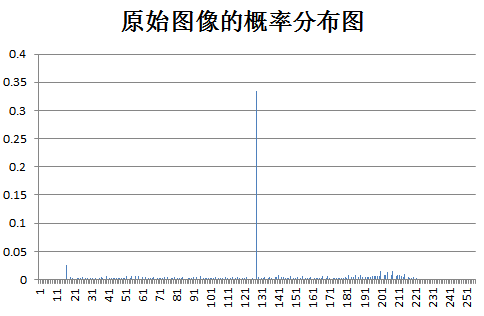
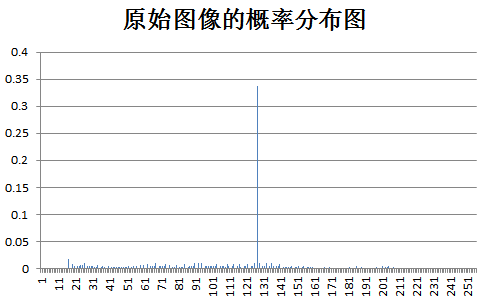
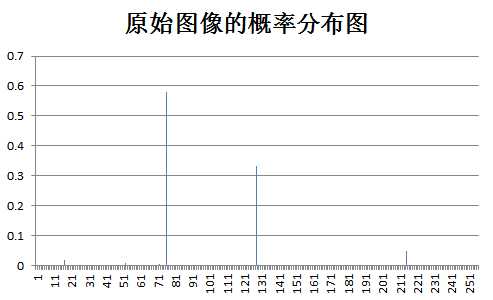
下面为原始图像和预测误差图像的概率分布图比较:
自己找的文件1:
自己找的文件2:

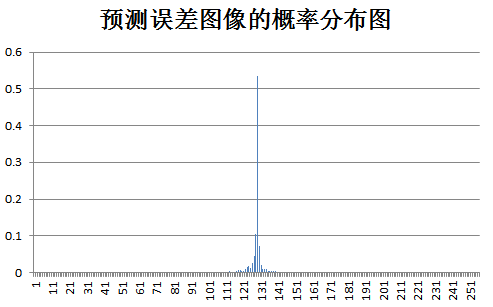
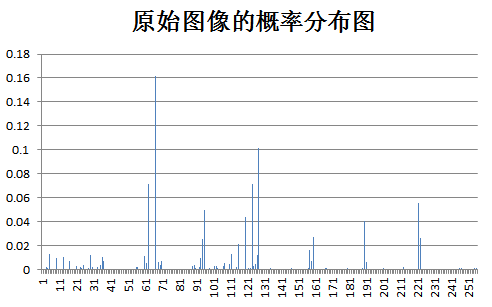
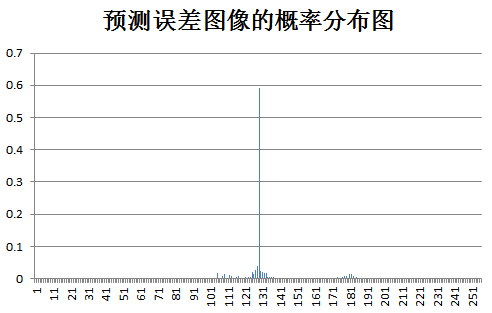
test Birds:
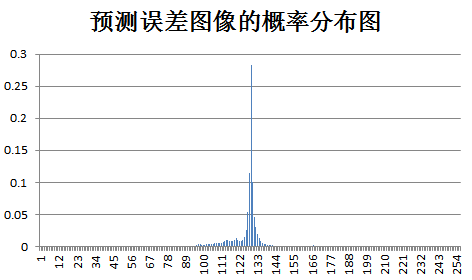
test Camman:
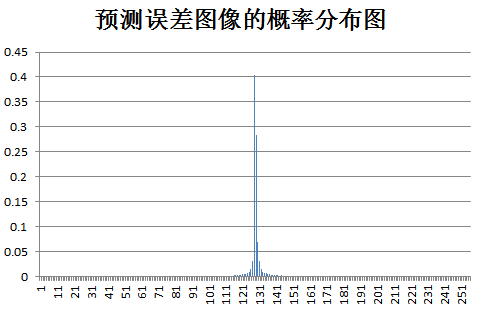
test clown:
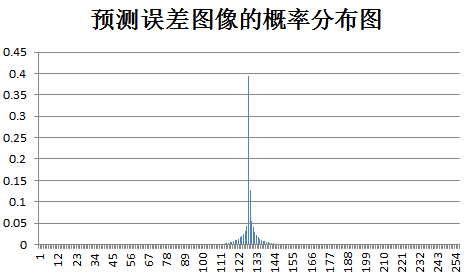
test fruit:
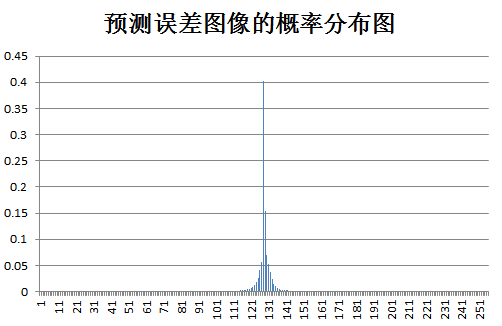
test lena:

test noise:
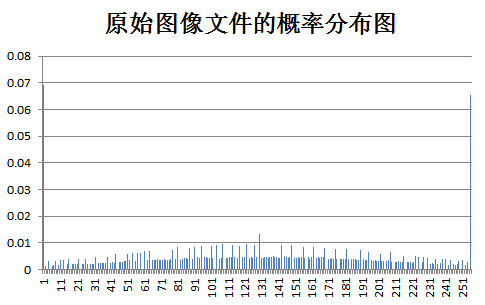
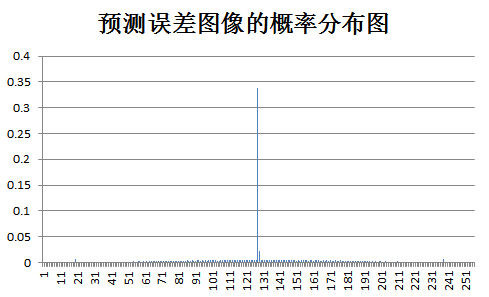
test Zone:
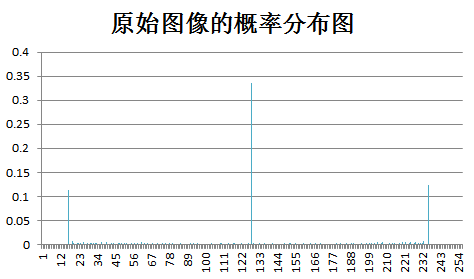
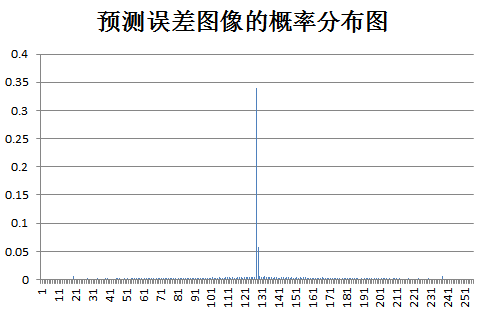
test odie:

DPCM+熵编码和仅进行熵编码的压缩比比较
| 文件名 | 原始图像 | 压缩后 | 压缩比 | 预测误差 | 压缩后 | 压缩比 |
| 1 | 1.75MB | 1555KB | 1.1524 | 1.75MB | 701 KB | 2.5563 |
| 2 | 0.98MB | 770KB | 1.3033 | 0.98MB | 405 KB | 2.4778 |
| Camman | 96KB | 61KB | 1.5738 | 96KB | 39 KB | 2.4615 |
| Clown | 96KB | 70KB | 1.3714 | 96KB | 47 KB | 2.0426 |
| Fruit | 96KB | 70 KB | 1.3714 | 96KB | 42 KB | 2.2857 |
| Lena | 96KB | 69 KB | 1.3913 | 96KB | 45 KB | 2.1333 |
| Noise | 96KB | 65 KB | 1.4769 | 96KB | 73 KB | 1.3151 |
| Odie | 96KB | 20 KB | 4.8 | 96KB | 17 KB | 5.6471 |
| Birds | 576KB | 520 KB | 1.1077 | 576KB | 333 KB | 1.7297 |
| Zone | 96KB | 60 KB | 1.6 | 96KB | 72 KB | 1.3333 |
初出茅庐,还请各位大神指教!















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









