







 本文介绍了Huffman编码,一种无失真数据压缩编码方式。它基于概率统计模型,通过构建二叉树来生成可变字长编码。文章详细阐述了Huffman编码的步骤,并展示了在实验中如何统计字符频率、构建Huffman树以及计算码字的过程。
本文介绍了Huffman编码,一种无失真数据压缩编码方式。它基于概率统计模型,通过构建二叉树来生成可变字长编码。文章详细阐述了Huffman编码的步骤,并展示了在实验中如何统计字符频率、构建Huffman树以及计算码字的过程。
1、 熵,又称为“信息熵” (Entropy)
1) 在信息论中,熵是信息的度量单位。信息论的创始人 Shannon 在其著作《通信的数学理论》中提出了建立在概率统计模型上的信息度量。他把信息定义为“用来消除不确定性的东西”。
2) 一般用符号H 表示,单位是比特。对于任意一个随机变量X,它的熵定义如下:H(X)= - ∑ P(X)log2[P(X)]。
3) 变量的不确定性越大,熵也就越大。换句话说,了解它所需要的信息量也就越大。
1) Huffman Coding (霍夫曼编码)是一种无失真编码的编码方式,Huffman 编码是可变字长编码(VLC)的一种。
2) Huffman 编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符号编长码,出现概率小的信源符号编短码,从而使平均码长最小。3) 在程序实现中常使用一种叫做树的数据结构实现 Huffman 编码,由它编出的码是即时码。
3 、Huffman 编码的方法
1) 统计符号的发生概率;
2) 把频率按从小到大的顺序排列
3) 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,这两个叶子节点不再参与比较,新的根节点参与比较;
4) 重复 3,直到最后得到和为 1 的根节点;
5) 将形成的二叉树的左节点标 0,右节点标 1,把从最上面的根节点到最下面的叶子节点途中遇到的 0,1 序列串起来,就得到了各个符号的编码。
二、实验过程
1 、 数据结构
1) Huffman 结点
typedef struct huffman_node_tag
{
unsigned char is Leaf; /* 是否为叶结点*/
unsigned long count; /* 信源中出现频数 */
struct huffman_node_tag *parent; /* 父节点指针 */
union
{
struct
{
struct huffman_node_tag *zero, *one; /*如果不是树叶,则此项为该结点左右孩子的指针*/
};
unsigned char symbol; /*如果是树叶,为某个信源符号 */
};
} huffman_node;
typedef struct huffman_code_tag
{
/* 码字的长度(单位:位) */
unsigned long numbits;
/* 码字,
码字的第 1 位存于 bits[0]的第 1 位,
码字的第 2 位存于 bits[0]的第 2 位,
码字的第 8 位存于 bits[0]的第 8 位,
码字的第 9 位存于 bits[1]的第 1 位 */
unsigned char *bits;
} huffman_code;
在实验时采用静态链接库,程序文件中包含两个工程,其中主工程需选择Win32 Console Application, 库工程需选择Win32 Static Library。
1)编码流程
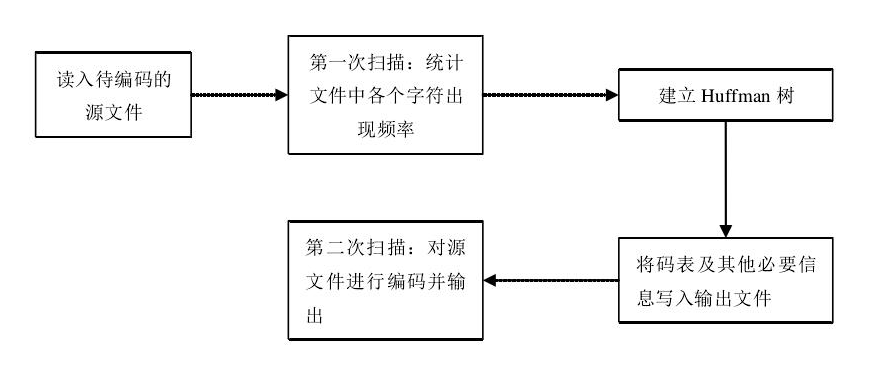
2) 第一次扫描,统计信源字符发生频率(8 比特,共 256 个信源符号)
1> 创建一个 256 个元素的指针数组,用以保存 256 个信源符号的频率。其下标对应相应字符的 ASCII 码。
2> 数组中的非空元素为当前待编码文件中实际出现的信源符号。
3> 程序代码如下:
typedef huffman_node* Symbol Frequencies[MAX_SYMBOLS];
Symbol Frequencies sf;
static unsigned int get_symbol_frequencies(Symbol Frequencies *pSF, FILE *in)
{
int c;
/* 总信源符号数初始化为 0 */
unsigned int total_count = 0;
/* 将所有信源符号地址初始化为 NULL(0) */
init_frequencies(pSF);
/* 第一遍扫描文件*/
while((c = fgetc(in)) != EOF) /*判断文件是否结束*/
{
unsigned char uc = c;
/* 如果是一个新符号,则产生该字符的一个新叶节点 */
if(!(*pSF)[uc])
(*pSF)[uc] = new_leaf_node(uc);
/* 当前字符出现的频数+1 */
++(*pSF)[uc]->count;
/* 总信源符号数+1 */
++total_count;
}
return total_count;
}
1> 按频率从小到大顺序排序并建立 Huffman 树
tatic Symbol Encoder* calculate_huffman_codes(Symbol Frequencies * pSF)
{
unsigned int i = 0;
unsigned int n = 0;
huffman_node *m1 = NULL, *m2 = NULL;
Symbol Encoder *pSE = NULL;
/*按信源符号出现频率大小排序,小概率符号在前(pSF 数组中)即下标较小 */
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp);
/* 得到当前待编码文件中所出现的信源符号的种类总数 */
for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n)
;
/* 建立 huffman 树。需要合并 n-1 次,所以循环 n- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









