







点击这里跳过前言
前言: 本文写作的动机,是笔者最近开始接触video处理,希望能从社区中找到快速入门的文档,但是翻来覆去,对于VOS任务的文档都很少,质量也不高,因此笔者在阅读过VOS综述和文章后,写下这篇VOS的review。希望能够帮助读者快速入门VOS以及Video Processing相关领域。
不定期更新最新工作。
VOS主要分成三种路径
- 无监督方法
- 有监督方法
- 半监督方法[Semi-Segmentation]
目前,主流的深度学习工作都集中在Semi-Segmentation。半监督学习常见的数据集为DAVIS,这种数据集中的每一个视频的第一帧有annotation,模型需要在剩下的帧中推理出mask。
本文就在DAVIS数据集上介绍各种常见的Semi-VOS方法。
下面是文章的正文
本文章只介绍Semi-SEG的方法,对于Semi-SEG,主要分为以下4种方法
-
based on Feature matching
这种方法使用第一帧有annotation的img-label对微调一个网络,并在剩下的视频帧中分割出foreground。
这种方法忽略掉了frame之间的相关性,当作小样本[或者one-shot]的Image-segment任务。 -
based on Long-term Feature-matching
相比based on Feature matching而言,虽然也是一种matching的方法,但是这种方法在预测当前帧t+1的mask时,采用不同的方法融合前面几帧或者所有帧的信息。 -
based on Optical-Flow
使用t+1和t帧的光流信息,预测t+1帧的mask -
based on Mask Propagation
这种方法也是使用之前帧的mask信息,但是区别于第二种based on Long-term infromation方法,第二种方法是将之前帧的信息融合成为一个feature,使用该feature给mask预测提供指导性的信息。但是Mask Propagation的任务基于一个assumption: t和t+1的mask相差应该不大,只需要将t帧的mask经过一定的修正就可以得到t+1帧的mask。
本文按以下目录组织。
文章目录
1. based on Feature matching[基于特征匹配]
一篇经典论文是One-Shot Video Object Segmentation。属于典型的Feature matching的方法。在介绍的同时,以这篇论文为例,什么是online,什么是offline。
该工作首先在ImageNet上训练一个模型,然后再在DAVIS数据集上进行fine-tuning,前面这两步都是offline的,也就是,在用户使用该网络的时候,不需要再进行上述训练。
在推理阶段,接受一个video sequence,第一帧是有annotation的。使用第一帧online地fine-tuning网络,得到一个适应于当前推理任务的网络,再用该网络对该video的后续frame进行推理。”One-Shot”只使用第一帧的标注数据来微调网络,然后在剩余的frames上inference。
该方法并不考虑视频帧之间的关系,简单地将每一帧看作独立的test data来进行推理。

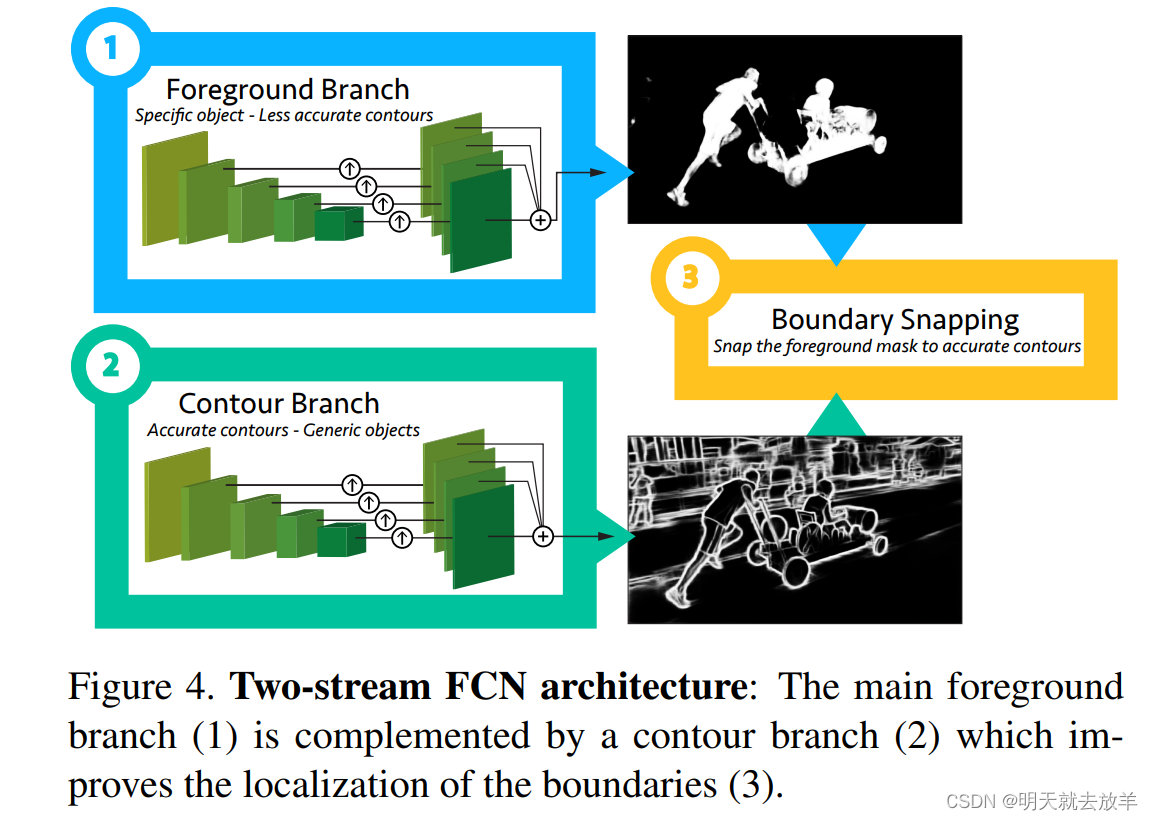
Details of the model:
模型选用FCN模型,并且设计为了两支,上面的Foreground Branch用来就是按照上述方法来预测前景,Contour Branch是使用其他数据集[边缘检测数据集]来offline训练的一个边缘检测的模型。最终上面的一张图得到了foreground,下面一张图得到了edge of each frame,两张图一起投票决定哪些pixel属于最终的segmentation image。
论文连接如下
https://arxiv.org/pdf/1611.05198.pdf
ADVANTAGE & disadvantage:
优点就是这种detect的方法不考虑帧之间的连续性,因此能够抗拒运动变化较大的物体。但是对于外形改变[跳舞的人]/相似物体误检无法抗拒。
2. based on Long-term feature-matching[基于长距离特征匹配]
这种方法,相比1.x的based on Feature matching而言,虽然也是一种matching的方法,但是这种方法在预测当前帧t+1的mask时,要融合前面几帧或者所有帧的信息,这种融合方式和3.x的mask Propagation也有区别,并不是将上一帧的mask作为下一帧的rough mask来修正[或者作为一种guide],而是直接将其编码成一种深层信息来给当前帧的预测使用。
2.1 Space-Time Memory
许多人认为这也是一篇mask-Propagation[见本文4.x]的工作。但是实际上这篇工作并不是将Mask给propagation了。而是将previous frames的特征存储到space-time memory,并使用当前帧的信息进行查询。将VOS工作变成了query问题。之前帧的mask并没有被propagation[传播]起来,而是作为了一种融合的feature,用来给当前frame进行match。
该工作的motivation是,在分割当前帧时,视频中前序帧中的信息对current frame的分割的影响,希望能够将之前分割好的帧的信息用来指导当前帧的分割。
Video Object Segmentation using Space-Time Memory Networks,该篇工作如下所述
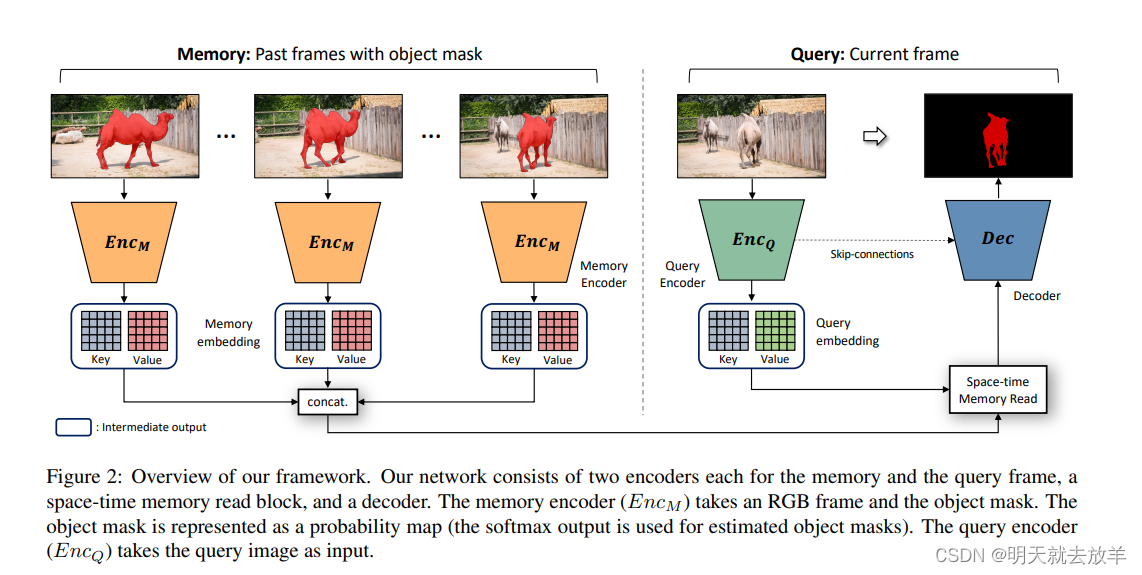
该模型的pipeline如下图。左边用来融合前序帧的信息,右边用来融合当前帧的RGB图像和左边得到的feature。
其中memory部分的ENCm是用来处理previous frame的。input为一个frame和一个mask,编码成一个Key和一个value。key和value一起送入Space-time Memory Read模块,ENCq模块用来编码current frame,编码的结果为一个Key和一个Value,也送入Space-time Memory Read模块。
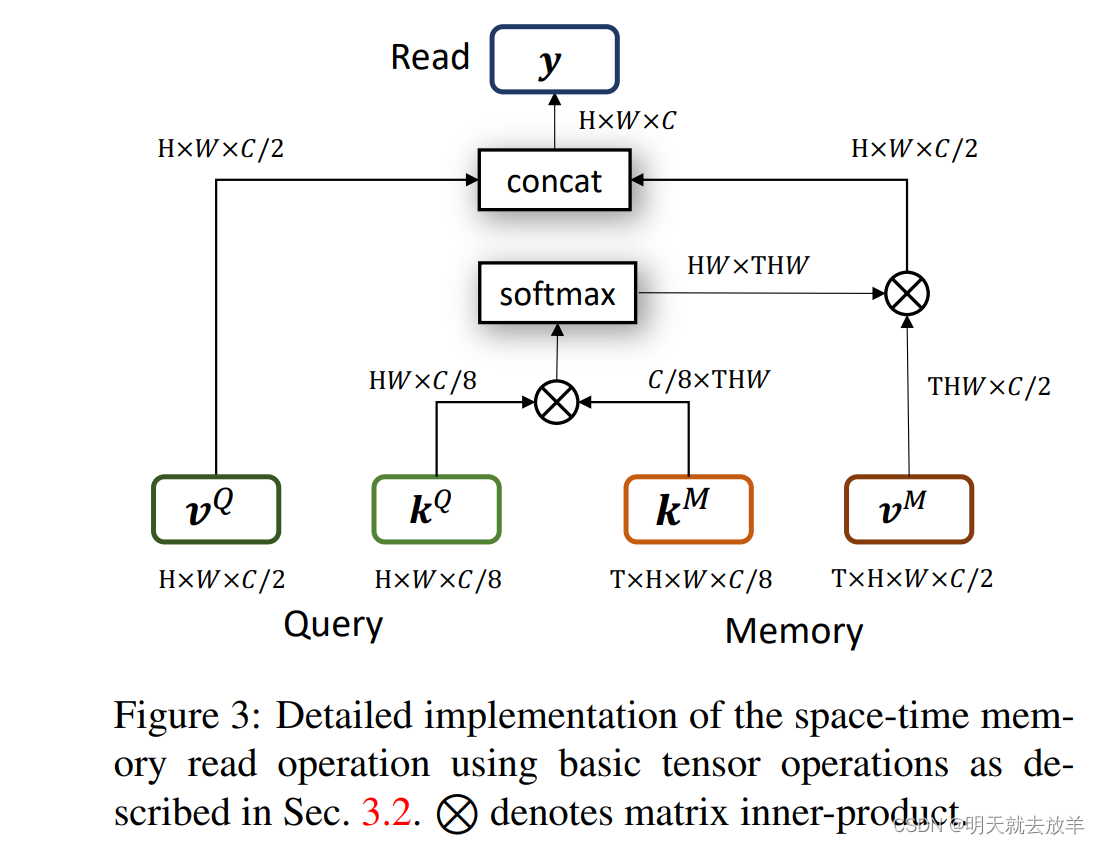
Space-time Memory Read模块接受两个Key和两个value。模型的detail如下图所示。首先K_q和K_m做一个注意力机制[multiple+softmax],将得到的feature map作为spatial-attention weight加到V_m身上。并和V_q拼接到一起,通过Read模块后输出到Decoder中去。
因此两个Key只是用来提供注意力权重,最终还是V_q和V_m[被注意力过后]相加后送入到Decoder。这种方法很好地利用到了之前已经分割出的mask。
2.2 Space-Time Variants
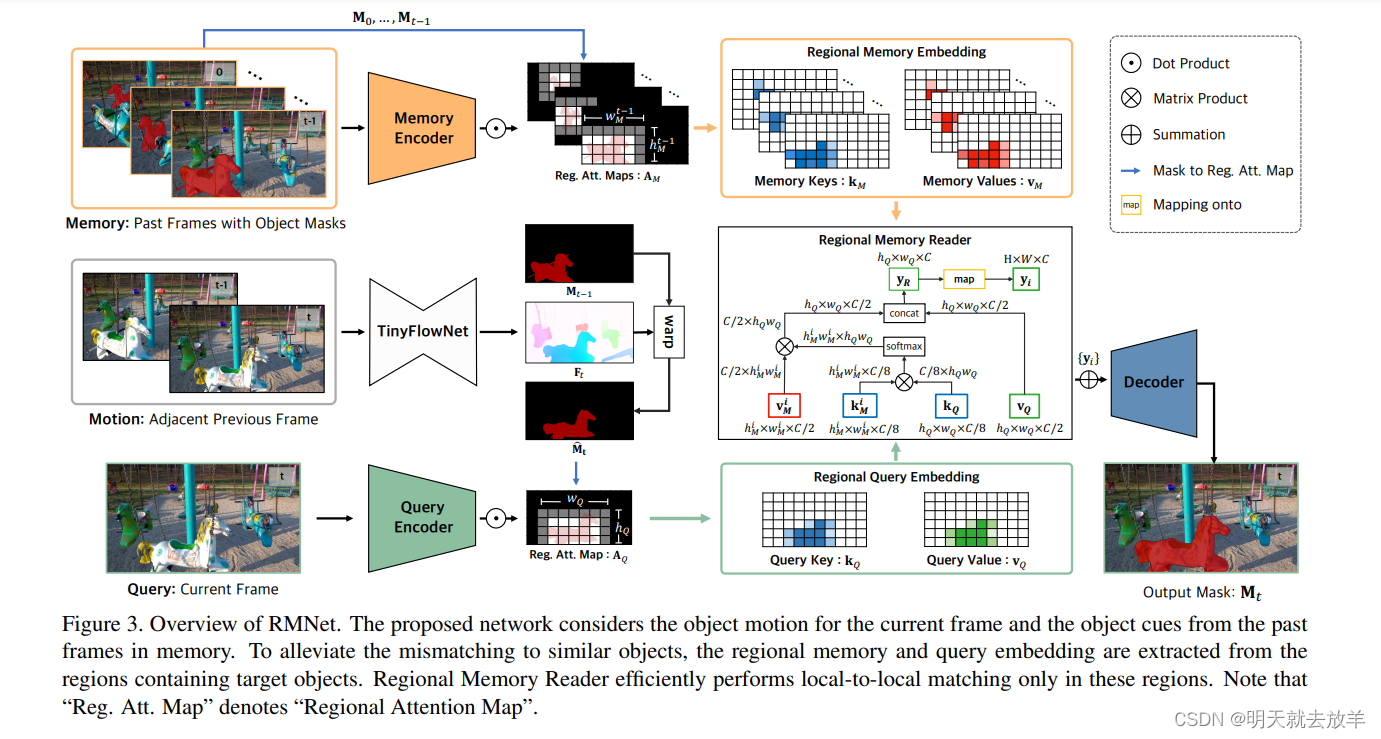
这是2.1工作的变体,文章叫做__Efficient Regional Memory Network for Video Object Segmentation
__。该文章在2.1的基础上进行了两个方面的创新。
- 在3.2的基础上加入了光流[见Section 3.x]。
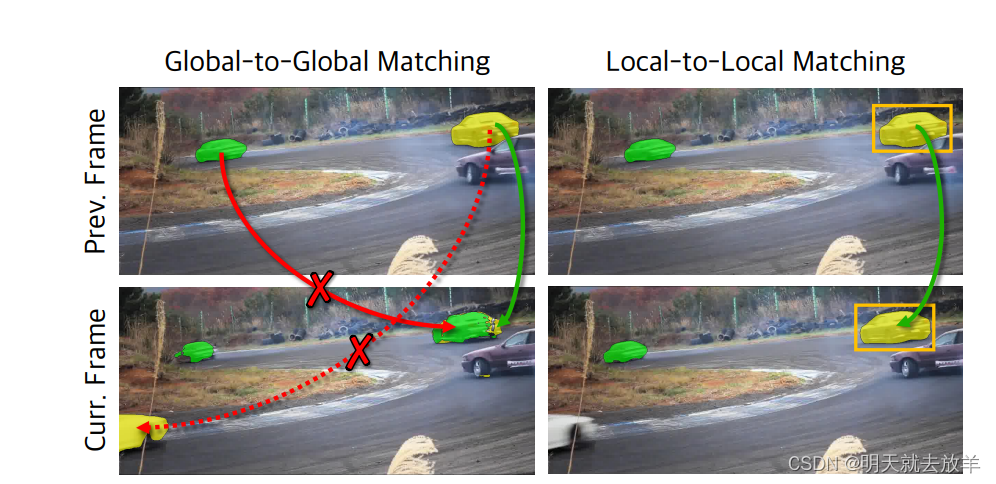
- 2.1的工作是Global2Global的算法,这种算法可能会将将外形相似的物体检测出来,比如我们想track一下CAR1,但是可能track到CAR2上,因此提出了一种Local2Local的方法。这两种的区别如下图所示。
再来看中间一支的光流算法,通过光流算法以后得到光流图,光流图和上一帧的Mask一起送入编码,得到了在当前帧上的Attention的feature map。和当前帧相乘以后得到的feature map再送入Memory中来查询。
其实这篇工作相比于2.1最大的贡献就是提供了一种local2local的attention机制,对于Memory frame的attention直接使用之前帧编码出attention weight,对于current frame的attention则是通过Optical Flow和上一帧的mask一起编码出attention weight。
3. based on Optical Flow[基于光流]
该方法不是特别流行,但是经常在其他的方法中配合使用。
为不影响行文,Optical Flow的介绍放在本文最后
frame t+1和frame t的光流图其实就揭示了所有像素点在t和t+1之间是如何流动的,如果已经知道了frame t的mask,那么结合光流图,就可以指导frame t+1的mask是什么了,这种方法的代表作品为_
FusionSeg: Learning to combine motion and appearance for fully automatic
segmentation of generic objects in video
Motion Branch输入的optical flow image是光流图

4. based on Mask-Propagation[基于掩膜引导]
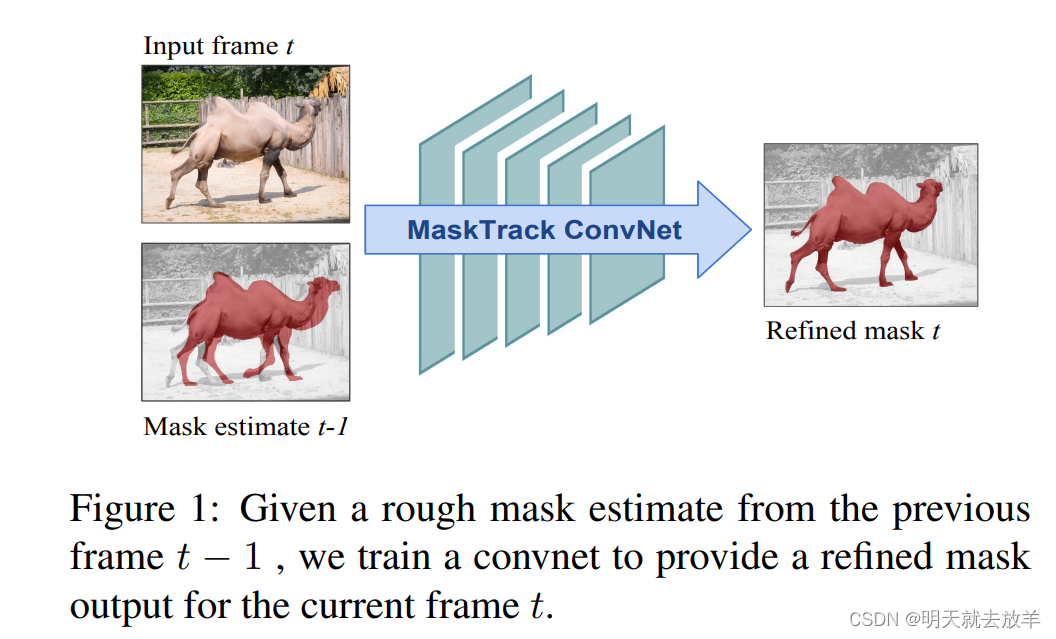
4.1 MaskTrack
ABSTRACT: 将seg任务转换成了一个estimate任务,t时刻预测得到的mask作为t+1时刻的粗糙mask,模型能够从粗糙的mask和当前的image中学会如何估计出当前帧的精确的mask。
在推理阶段,首先在线微调网络,将第一帧图像通过各种数据增广策略[主要起作用的是仿射变换和刚性变换,主要变换的对象是mask,这样就可以模拟出一个粗糙的mask,使用粗糙的mask和img来微调网络,使网络能够学习到如何根据RGB图像和粗糙的mask得到精确的mask]
真正开始推理的时候,就是offline的,将当前的RGB和上一帧的mask合成四通道,输入到网络中,得到当前帧的estimate mask[其实也就是准确的mask]
该方法还是online+offline。
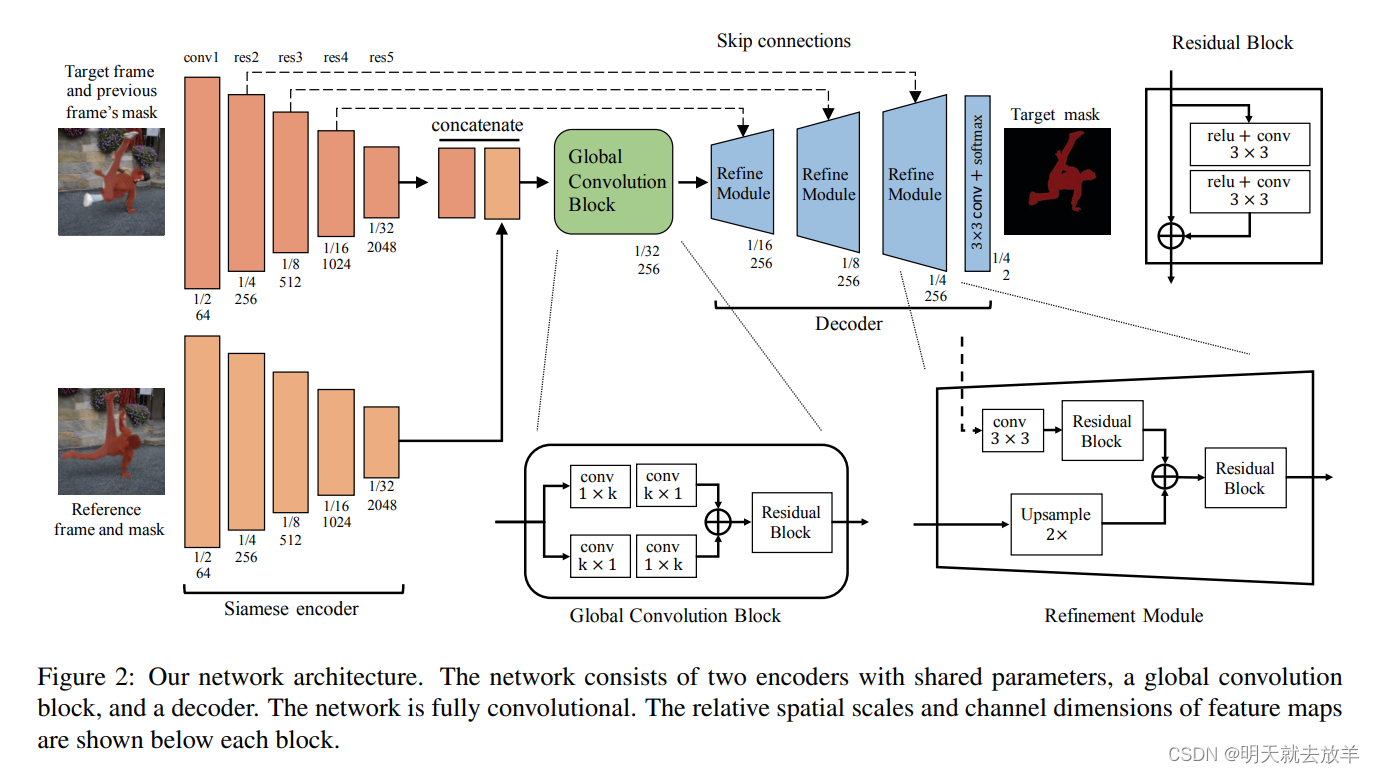
4.2 Reference-Guided Mask Propagation
该工作名为__Fast Video Object Segmentation by Reference-Guided Mask Propagation__。
该模型pipeline如下所示。在预测当前帧时,将当前帧的RGB和之前某一帧的mask拼接成四通道feature,在上半支输入。将第一帧的RGB和frame拼接起来输入到下半支。这样充分利用到了Mask Propagation[某一帧的mask]和Reference-Guided[第一帧的RFB和mask]
论文连接为
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8578868
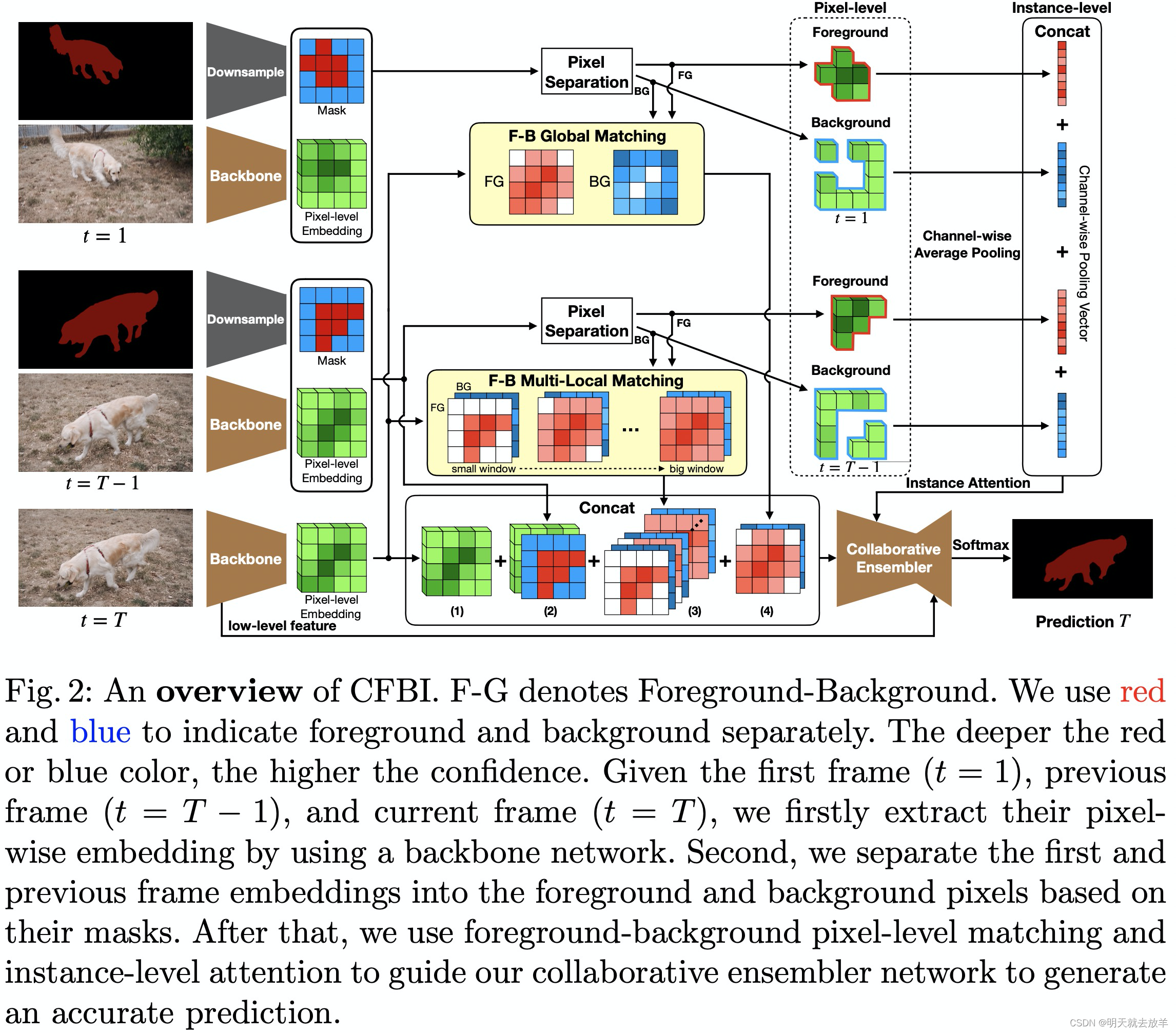
4.3 Fore&back GROUND Integration
Collaborative Video Object Segmentation by Foreground-Background Integration,这篇文章在总体的设计上和4.x中的其他文章一致,在这里也是用第一帧和上一帧的mask作mask Propagation,只是这篇文章在网络设计上更加优秀,提出了background embedding。并且在pixel-level embedding的之外,提出了instance-level embedding,作为一种attention机制来辅助pixel embedding。
5. Appendix[Intro of Optim Flow]
在介绍下面这种方法之前,先要理解一下什么是Optimal Flow[光流],光流就是pixel的流动。一般用一张光流估计图来表示两个相邻帧之间的Optimal Flow,这张光流图一般尺寸为[2,height,width],是一个双通道的图,其中每一个pixel的两个通道分别代表该像素点的x方向偏移量和y方向偏移量。光流估计有许多传统方法,也有深度学习的方法。介绍一下一个基础的FlowNet[based on CNN]。
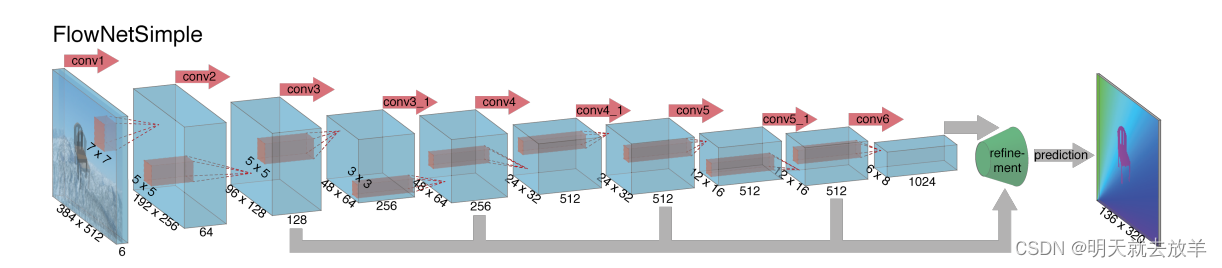
上面这张图将两个相邻的frame在输入前concatenate到一起,然后送入全连接CNN网络,解码后得到输出的光流图
下面这张图方法差不多,但是是在高维的feature map上进行concatenate,解码后得到光流图。
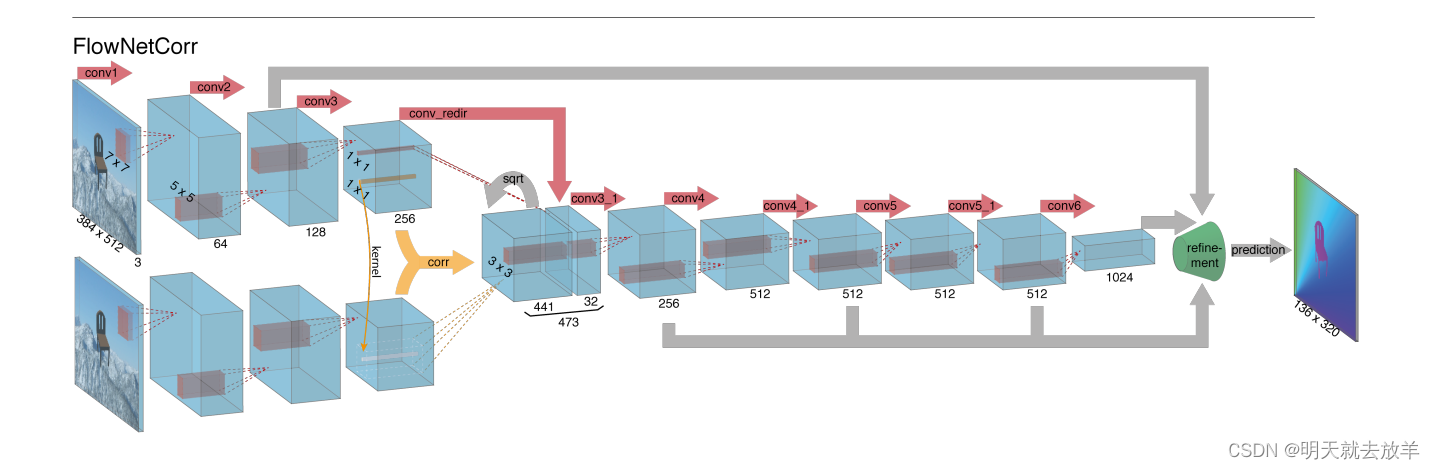
**Copyright@LiuThree**

















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









