






TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率),是一种统计方法,可以用来评估一个词对于一个文件集来说的重要程度,也可以评估一个语料库中的其中一份文件的重要程度。词语的重要性与它在文本中出现的次数成正比,与它在语料库中出现的频率成反比。
(某词在文本中出现的次数越多,在语料库中出现的次数越少越能代表该文章)
词频 (term frequency, TF) 指的是该词在文本中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件(不管该词是否重要,它在较长的文章中出现的次数可能比短文章中出现的次数多)。

比如:一篇文本的总词语数是100个,而词语“玫瑰花”出现了6次,那么“玫瑰花”一词在该文本中的词频就是6/100=0.06即
TF(玫瑰花)=6/100=0.06
这里需要注意的是, 一些通用的词语(词频很高的词)对于主题可能并没有太大的作用, 反倒是一些出现频率较少的词才能够表达文章的主题, 所以单纯使用是TF值大的词来代表文章是不合适的,这里就需要用到IDF。
权重的设计必须满足:一个词预测主题的能力越强,权重越大,反之,权重越小。
逆向文件频率 (inverse document frequency, IDF) IDF的主要思想是:如果包含某个词语的文档越少**(所有统计的文章中,一些词只是在其中很少几篇文章中出现,那么这样的词对文章的主题的作用很大,这些词的权重应该设计的较大。),该词的 IDF值就越大,则说明该词具有很好的类别区分能力。词语的IDF的计算,可以由总文件数目除以包含该词语的文件的数目**,再将得到的商取对数得到。

分母加1,是为了避免语料库中并没有包含该词的文档时分母为0。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,(高词频,低文件频率)可以产生出高权重的TF-IDF。因此,TF-IDF可以过滤掉常见的词语,保留重要的词语。
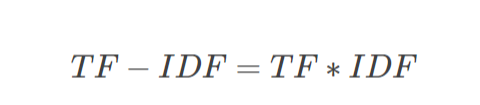
举例:
假设在一篇体育文本中,“篮球”,“中国”,“运动员”各出现15次,该文本共有1000个词,则这三个词的词频(TF)均为0.15,我们的语料库中共有200个文本,包含“篮球”的文本共有20篇则逆文件频率(IDF)=log(200/21)=0.979,包含“中国”的文本共有40篇逆文件频率(IDF)=log(200/41)=0.688,包含“运动员”的文本共有9篇逆文件频率(IDF)=log(200/10)=1.301。

TF-IDF值越大,说明该词更能代表该文章,如果只选择一个词,运动员就是这篇文章的关键词。















 2334
2334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









