






半监督学习
监督学习是什么?
训练集的每一个数据已经有特征和标签(我们在进行文本分类的时候,训练数据为已经分好类别的语料)
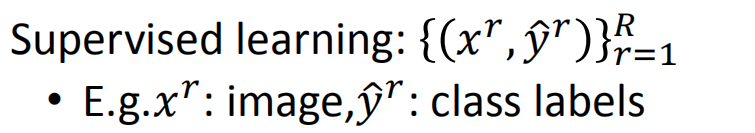
有输入数据和输出数据通过学习训练集中输入数据和输出数据的关系,生成合适的函数,将输入映射到合适的输出。比如分类、回归。
半监督学习是什么?
在label data上面有另外一组unlabel data(只有input没有output)
训练集中一部分数据有特征和标签,另一部分只有特征(只有输入没有输出),综合两类数据来生成合适的函数。【通常无标签的数据要多于有标签的数据】
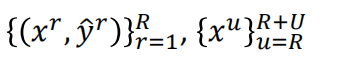
Transductive learning: unlabeled data is the testing data(只使用testing data的特征)
Inductive learning: unlabeled data is not the testing data(不考虑testing set)【是否确定testing data】
为什么要用半监督学习?
数据很多,但是带标签的数据很少(人工标注需要耗费大量的人力物力)
我们在生活中的学习就是半监督学习(比如从小孩开始,接触新事物的时候会先从父母那里得到一点信息,比若说看到一只狗,父母就会告诉我们这个是狗,也就是label,但是我们在一生中会看到很多种狗,我们会根据之前的知识去推断出来它是狗,这时是没有标签的,所以人类学习的过程就是半监督学习)
为什么半监督学习有用
无标签数据的分布能告诉我们一些有价值的信息,通常是伴有假设的。
假设:
相似性聚簇(在现实世界中,在晚上,在中国大片土地上用灯光的聚簇就可以定位大城市、特大城市。)类型相似的数据一般会聚在一起
半监督学习有没有用取决于假设有没有用



半监督学习的四种方法
Semi-supervised Learning for Generative Model**
监督生成模型
在监督学习中,二分类中生成模型的数据有C1和C2两类数据组成,寻找最可能的先验概率P(Ci)和类依赖概率P(x | Ci),假设每一类的数据都是服从高斯分布,我们可以通过分布得到参数均值μ和方差Σ。P(x |> Ci)是由μ_和Σ参数化的高斯分布。如下图所示,我们要求得一个决策边界。
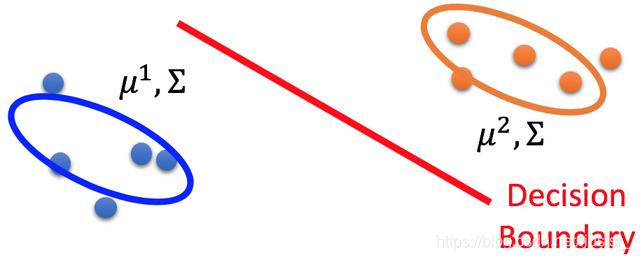
利用参数可以知道P(C1)和 P(C2)、μ1、μ2、Σ。并利用这些参数计算某一个对象属于某一类别的概率 (贝叶斯)。
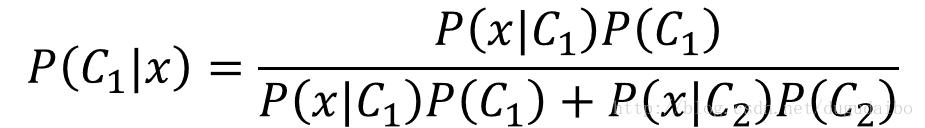
半监督生成模型
半监督生成和监督生成模型类似,但是其中存在一些无标记的数据,如下图所示,让分布更加丰满,由椭圆到圆
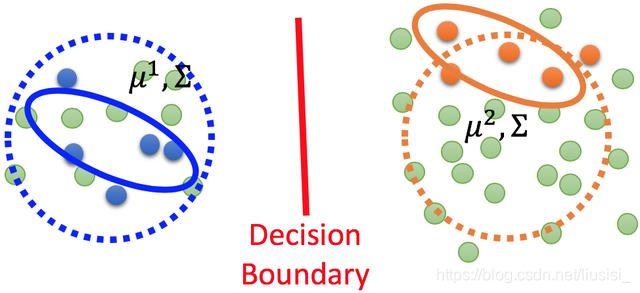
这个时候如果仍在使用之前的数据分布明显是不合理的,需要重新估计数据分布的参数,这个时候可能分布式一个类似于圆形的形状。这里就需要用未标签数据来帮助估计新的μ1,μ2,Σ
由贝叶斯定理的思想,我们知道,未标记的数据对于这些参数的重新估计趋向更加精确发挥着重要的作用。
半监督生成模型的过程(简单介绍)

假如我们做二分类的问题,我们先使用有标注的数据初始化两个类别的参数P(C1)和 P(C2)、μ1、μ2、Σ,
一、 根据现有的参数计算出每一个无标签数据的类别概率P(c1|xu)
(这个概率和之前带标签的数据训练的模型有关)
二、更新模型(求先验概率的时候需要把无标签的数据考虑进去)
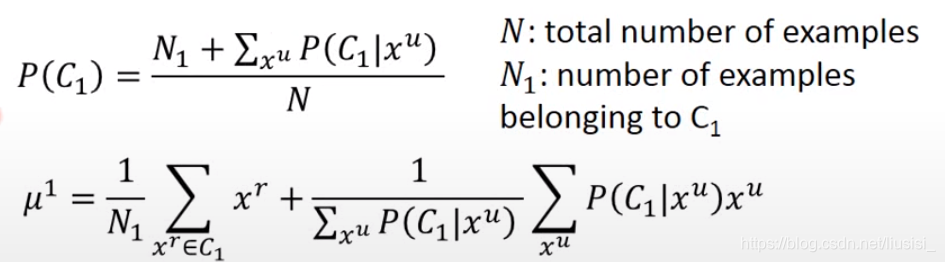
计算概率、更新模型反复迭代
具体算法
EM算法
EM算法是一种流行的迭代算法,用于在丢失数据的问题中进行最大似然估计。EM算法包括两个步骤
1、期望步骤,即填写缺失的数据;
2、最大化步骤 - 计算参数的新的最大后验估计。

Low-density Separation Assumption(低密度分离的假设)
low-density separation定义
若仅给定两类有标签数据那么boundary为两条红线中的任一条均可,但当加入无标签数据时(绿圆)则左侧boundary最优,因为low-density separation定义为交界处数据的密度是最低的(两个类别有很明显的交界处)
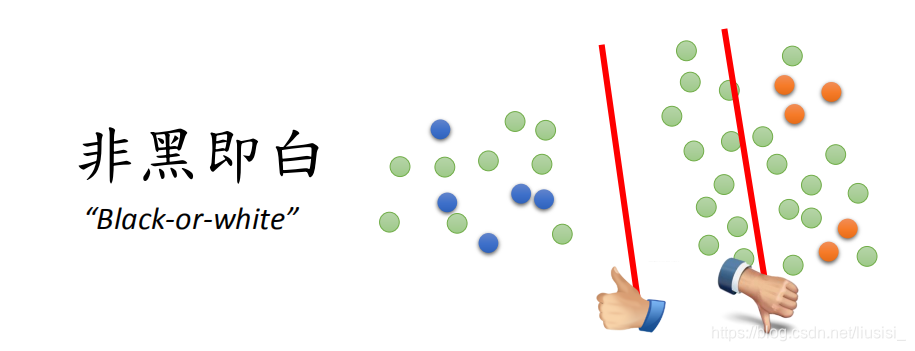
Low-density separation最简单的方法是self-training
过程:
(1)我们有一些label data和一些unlabel data
(2)通过labelled data训练得到模型 f
(3)将unlabelled data放入模型 f,得到unlabel data的标签
(4)把unlabel data的数据拿出一部分出来放入label data set中(可自己定义),再训练模型 f
循环
slef-training和generative model里面用的那个方法很相似。他们唯一的差别就是在做self-training的时候,我们用的是hard label;在做generative mode时,你用的是soft model。在做self-training的时候我们会强制一笔train data是属于某一个class,但是在generative model的时候,根据它的posterior probability 它有一部分是属于class1一部分是属于class2。
哪一个比较好?
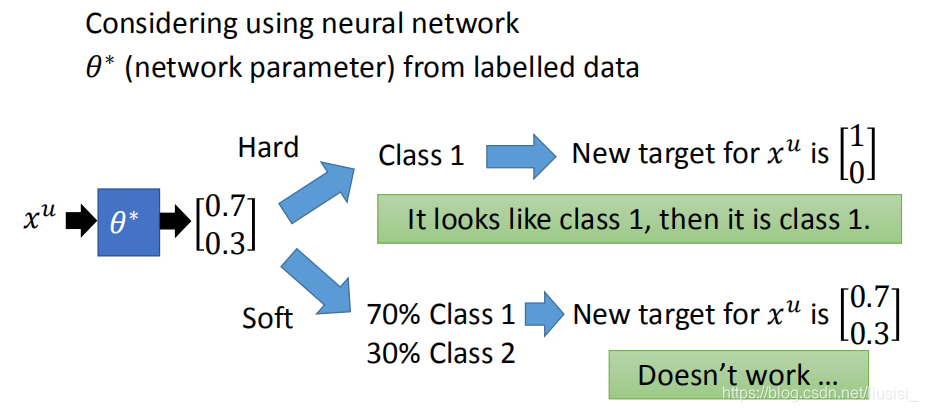
这里soft这个方法是没有用的,只能使用hard label。因为模型的输出就是0.7和0.3,目标又设成0.7和0.3,相当于自己证明自己,所以没用。
我们用hard label的时候,就是用low-density separation的概念。也就是说:我们看xu 它属于class1的几率只是比较高而已,我们没有很确定它一定是属于class1的,但这是一个非黑即白的世界,如果你看起来有点像class1,那就一定是class1。根据model的输出:0.7是class1,0.3是class2,那用hard label(low-density-separation)就改成它属于class1的几率是1(完全就不可能是class2)。
改进 Entropy-based Regularization
如果我们使用neural network,最终的output是一个distribution,我们不限制output一定要是class1、class2,但是我们做的假设是这样的,这个output distribution一定要是很集中,因为这是一个非黑即白的世界。
假设我们现在做五个class的分类,在class1的几率很大,在其他class的几率很小,这个是好的。在class5的几率很大,在其他class上几率很小,这也是好的。如果今天分布很平均的话,这样是不好的(因为这是一个非黑即白的世界),这就不符合low-density separation的假设。

这个我们使用entropy来评估我们得到的distribution是好的还是不好的。通过entropy来计算我们的分布是集中的还是不集中的。
这里我们希望找一个参数,让在label data上训练出的模型l的output跟正确的model output距离越小越好,我们可以使用 entropy 来评估它们之间的距离,这个是label data的部分。在unlabel data的部分,我们需要加上每一笔unlabel data的output distribution的entropy,我们希望这些unlabel data的entropy 越小越好
半监督SVM

SVM的原理就是:通过两个类别的数据,找一个边界,这个边界一方面要做有最大的margin(最大margin就是让这两个class分的越开越好)同时也要有最小的分类的错误。
现在假设有一些unlabel data,SVM会穷举所有可能的label,比如说这里有4个unlabel data,每一个data都可以是属于class1,也可以是属于class2,具体的做法就是穷举它所有可能的label(如右图所示)。对每一个可能的结果都去做一个SVM,然后再去说哪一个unlabel data的可能性能够让你的margin最大同时又minimize error。
问题:穷举所有的unlabel data label,这是非常多的事情。该论文提出了一个approximate的方法,基本精神是:一开始得到一些label,然后你每次改一个unlabel data看可不可以让margin变大,变大了就改一下。
Smoothness Assumption
假设:x的分布是不平均的,它在某些地方是很集中,某些地方又很分散。如果x1,x2在在高密度的地方是很接近的话,y1,y2才会是很像的。
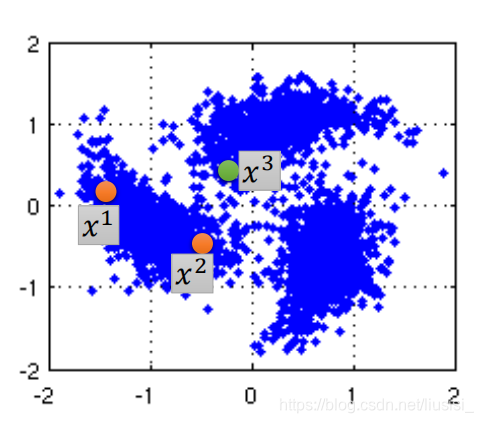
这里有三个数据,x1和x2之间有一个高密度的区域,所以x1和x2之间是比较像的,所以x1和x2
可能会有比较像的label,而x2和x3之间可能会有比较不一样的label(他们中间没有high density path)
这个假设在真实的情况下是很多可能成立,比如:

最左边的2跟最右边的2中间有很多连续的形态,所以根据smoothness
Assumption的话,左边的2跟右边的2是比较像的,右边的2跟3中间没有过渡的形态,它们两个之间是不像的。
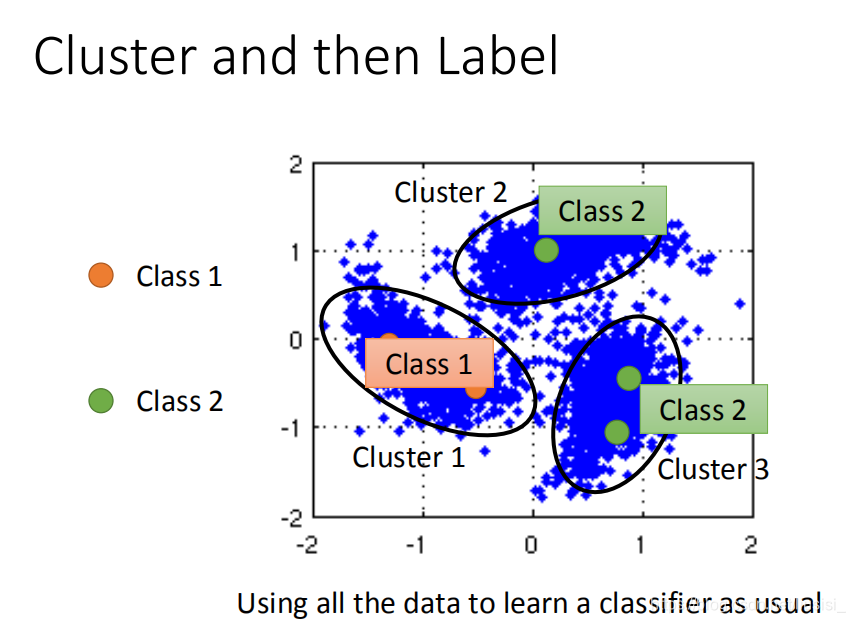
实践smoothness assumption,最简单的方法是聚类然后打标签。图中橙色是class1,绿色是class2,蓝色是unlabel data。接下来我们需要进行聚类,我们将其分成三个cluster,然后cluster1里面class1的label data最多,所以cluster1里面所有的data都算是class1,cluster2,cluster3都算是class2、class3,然后把这些data拿去learn就结束了,但是这个方法不一定有用。因为不同的class可能会很像,也有可能会不像。
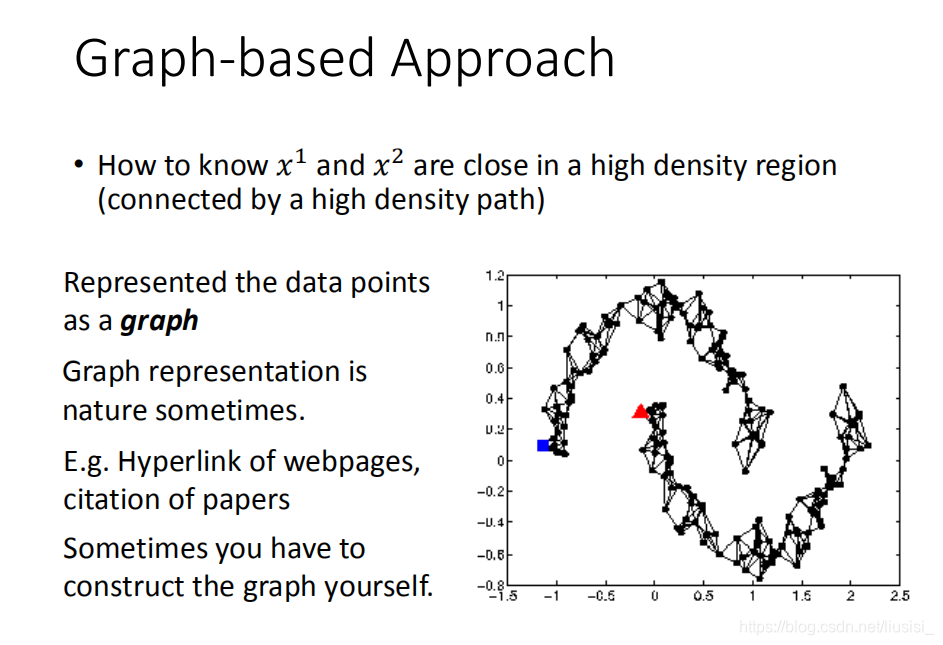
Graph-based Approach 基于图的方法
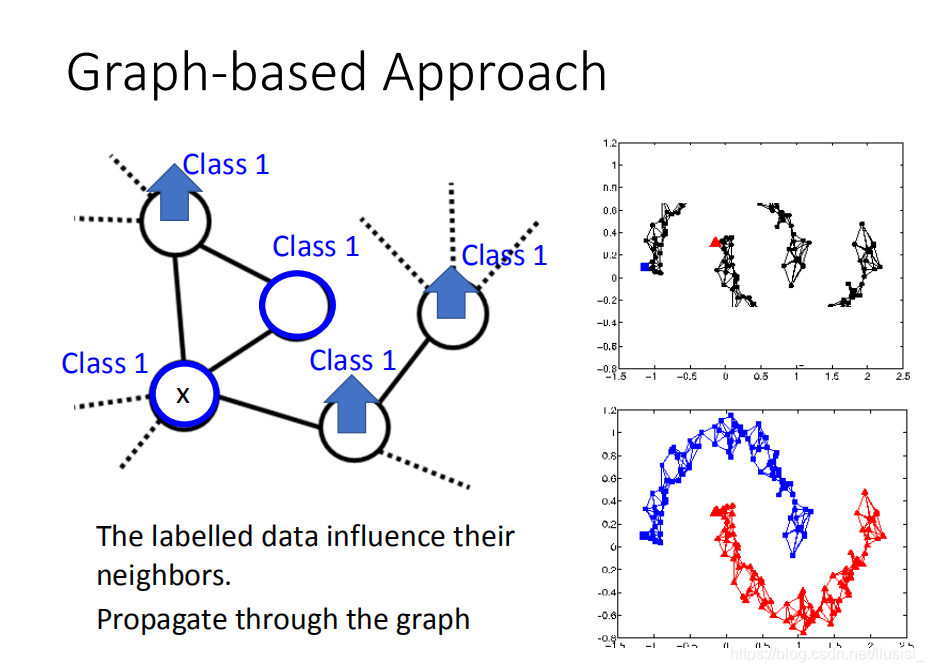
我们用基于图的方法来表达通过高密度路径连接
我们现在把所有的data points都建成一个graph,每一笔data points都是这个graph上一个点
high density path的意思就是说,如果有两个点,他们在这个图上面是相连的,那么他们这就是同一个class,如果没有相连,就算实际的距离也不是很远,那也不是同一个class。
创建graph:
(1)有些时候这个graph representation是很自然就得到了。举例来说:假设我们现在要做的是网页的分类,而我们有记录网页之间的Hyperlink,那Hyperlink就可以直接告诉我们网页之间是如何连接的。假设现在做的是论文的分类,论文和论文之间有引用之间的关系,这个引用也是graph。
(2)在两个数据之间没有很明显的关系时,我们需要计算两个数据之间的相似度,算完相似度就可以创建graph,graph有很多种:比如说可以建K Nearest Neighbor,K Nearest Neighbor意思就是说,我现在有一大堆的data,data和data之间,我都可以算出它们的相似度,那我K=3(K Nearest Neighbor),每一个point跟他最近的三个point做标记。或者也可以做e-Neighborhood:意思就是说,每个点只有跟它相似度超过某一个threshold,跟它相似度大于的1点才会连起来。所谓的edge也不是只有相连不相连这样boundary的选择而已,我们可以给edge一些weight,你可以让你的edge跟你的要被连接起来的两个data points的相似度是成正比的。我们可以选择Gaussian Radial Basis function来定义这个相似度。

如果我们现在在graph上有一些label data,在这个graph上我们说这个data1是属于class1,那跟它有相连的data points属于class1的几率也会上升,所以每笔data会影响它的邻居。graph-based approach真正帮助的是:它的class是会传递的,本来这个点有跟class1相连所以它会变得比较像class1。但是这件事会传递,虽然这个点真正没有跟class1相连,因为像class1这件事情是会传递的,会通过graph link传递过来。
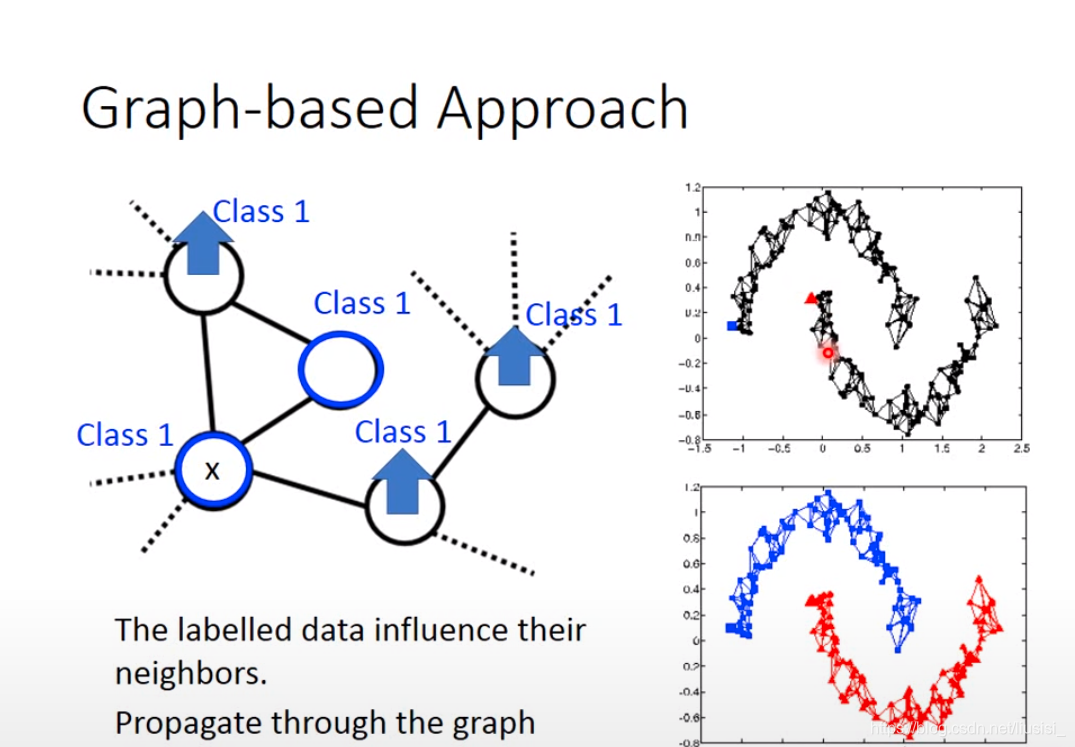
这样的semi-supervised有用,我们的data要足够多,如果data不够多的话,这个地方没收集到data,那这个点就会断掉,那这个信息就传不过去了,比如右上图就出现四个小的cluster。
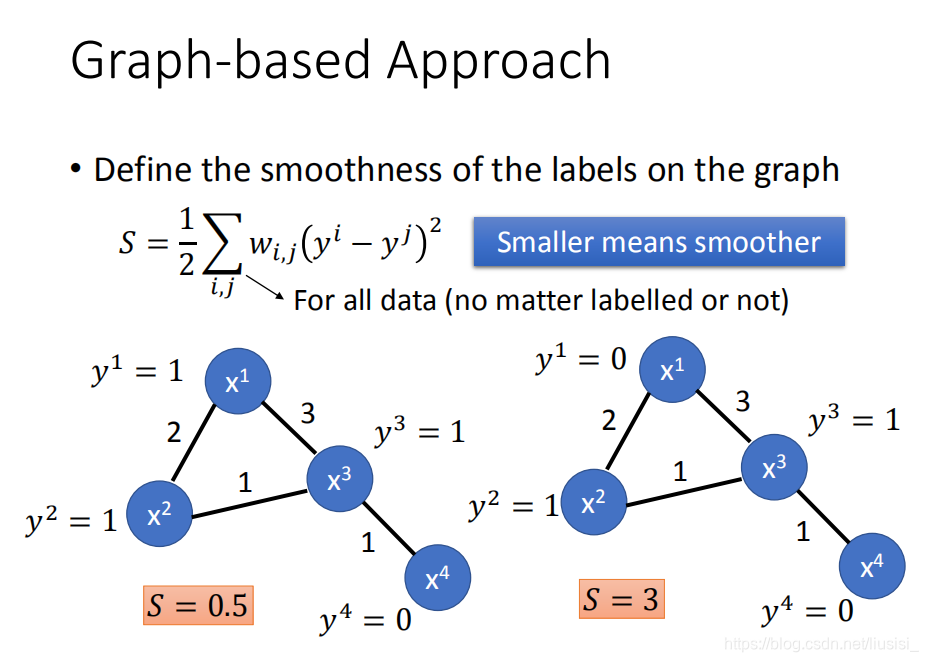
定量使用这个graph,在这个graph structure上面定义一个东西叫做:label的 smoothness,我们会定义说label有多符合我们刚才说的smoothness assumption 的假设。
我们考虑两两有相连的point,两两拿出来计算,s值越小越smothness
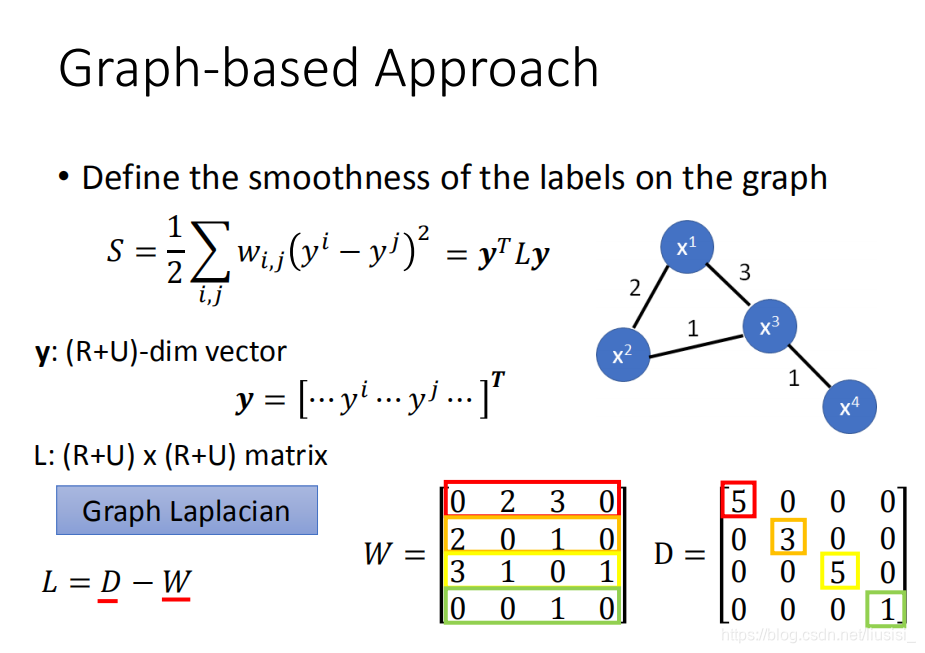
现在我们可以用yTLy去评估我们现在得到的label有多smothness,这个y是label,这个label的值也就是神经网络的输出,它的值取决于神经网络的参数,















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









