







字符串数组与字符串指针在使用上有很多相似的地方,导致对两者的理解容易混淆.下面我们将从汇编的角度来详细审视一下两者的区别.
先看下面一段代码:
/*file name: test.c*/
#include<stdio.h>
char *globle_pointer="aaaaaaaaa";
char globle_buf[]="bbbbbbbb";
void main(){
char *local_pointer="cccccccc";
char local_buf[]="dddddddddd";
*(globle_pointer+2)='A';
globle_buf[2]='B';
*(local_pointer+2)='C';
local_buf[2]='D';
printf("globle_pointer:%s\n",globle_pointer);
printf("globle_buf:%s\n",globle_buf);
printf("local_pointer:%s\n",local_pointer);
printf("local_buf:%s\n",local_buf);
}这个程序可以通过编译,但是一旦运行就会报出”段错误 (核心已转储)”.原因在于第8和第10行.紧跟在字符串指针后的字符串是只读数据,不允许修改.所以第8行和第10行企图修改只读数据段的操作当然受到禁止了.我们可以在汇编代码(片段)中清楚看到这一点:
.file "test.c"
.globl globle_pointer
.section .rodata
.LC0:
.string "aaaaaaaaa"
.data
.align 4
.type globle_pointer, @object
.size globle_pointer, 4
globle_pointer:
.long .LC0
.globl globle_buf
.align 4
.type globle_buf, @object
.size globle_buf, 9
globle_buf:
.string "bbbbbbbb"
.section .rodata
.LC1:
.string "cccccccc"
.LC2:
.string "globle_pointer:%s\n"
.LC3:
.string "globle_buf:%s\n"
.LC4:
.string "local_pointer:%s\n"
.LC5:
.string "local_buf:%s\n"
.text
.globl main
.type main, @function
main:由于.section .rodata的修饰,.string “aaaaaaaaa”和.string “cccccccc”变成只读数据段,而.string “bbbbbbbb” 和globle_pointer 受到.data修饰,恢复为可读写属性.所以globle_pointer作为全局变量可以修改它的值.这解释了字符串”aaaaaa”,”bbbbbbb”和”ccccccc”的读写性质,等等,”dddddd”在哪儿呢?通过读后续代码,我们可以看到”ddddd”是被代码写入了main函数的栈空间中,而栈是可读写的,所以这也解释了local_buf的读写属性:
movl %esp, %ebp
pushl %ecx
.cfi_escape 0xf,0x3,0x75,0x7c,0x6
subl $36, %esp
movl %gs:20, %eax
movl %eax, -12(%ebp)
xorl %eax, %eax
movl $.LC1, -28(%ebp)
movl $1684300900, -23(%ebp)
movl $1684300900, -19(%ebp)
movw $25700, -15(%ebp)一共10个’d’,正好在最后三行汇编代码中得到体现.说了这么多,可以看到所谓读写属性本质是由编译器的.section .rodata控制的.为了证明这一点,我们可以尝试突破这个限制:
我们在终端依次输入下面的命令:
$gcc -m32 -c test.c
$objcopy --rename-section .rodata=.data test.o out.o
$gcc -m32 out.o -o out
$./out我们逐行解释:第一行将test.c编译成test.o,不进行链接.第二行将test.o的只读数据段修改成读写数据段,输出为out.o,第三行链接out.o为可执行程序out,第四行执行这个文件.这时程序可以正常运行:
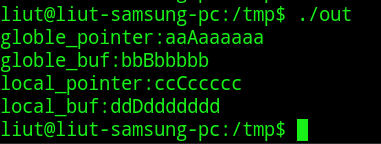
综上,程序示例中的字符串指针后的字符串是只读的,而字符串数组后的字符串是可读写的.















 3179
3179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









