







 本文深入探讨了倒排索引的概念及其在全文检索中的优势。倒排索引通过将内容分词并建立词到文档的映射,极大地提高了搜索效率。相较于正排索引,倒排索引更适合大数据量的全文搜索。文章还介绍了倒排索引的组成部分,包括单词词典和倒排列表,并举例说明了其工作原理。在实际应用中,如电商营销活动的规则匹配,倒排索引可以避免遍历所有规则,提高查询速度。倒排索引的思想不仅在Elasticsearch等搜索引擎中有应用,也可灵活运用到各种需要高效检索的场景。
本文深入探讨了倒排索引的概念及其在全文检索中的优势。倒排索引通过将内容分词并建立词到文档的映射,极大地提高了搜索效率。相较于正排索引,倒排索引更适合大数据量的全文搜索。文章还介绍了倒排索引的组成部分,包括单词词典和倒排列表,并举例说明了其工作原理。在实际应用中,如电商营销活动的规则匹配,倒排索引可以避免遍历所有规则,提高查询速度。倒排索引的思想不仅在Elasticsearch等搜索引擎中有应用,也可灵活运用到各种需要高效检索的场景。
倒排索引是一个很重要的概念在ES中,这个概念我们需要很仔细的来研究一下。
首先说起倒排就肯定是基于正排对比的。那我们先来说一下正排索引。
一、正排索引
先举个例子吧,以前我们学习mysql的时候,很多书或者资料都会在讲到索引的时候给你来个例子就是书的目录。其实索引不管是正排还是倒排都是起到一个目录的作用。只不过倒排和正排的目录组织形式有所不同。
MYsql的索引组织形式就是正排索引,我们以他的聚簇索引结构来看一下,当然我们不说他的那些B+树的具体格式。只做简单的一个结构描述。在Mysql中的一个表结构如下。
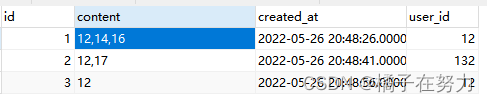
表中结构是按照id为主键,一行一行的文档排布的。我们查找文档的时候,通过id可以找到一条文档。这种方式的好处就是我在查询整个文档的时候一次就能取出来。
但是要是遇到全文检索的需求,比如我要查content是14的再那个文档里面就得一个个去比对(mysql底层肯定是要一个个比对的)。这种要是数据量很大的时候就会有性能问题。此时要是倒排索引就很好解决这个问题。
二、倒排索引
1、倒排列表
倒排索引也是目录,只是目录的组织形式不一样。还是以上面那个mysql的表的例子,他在转成倒排索引的时候格式如下。
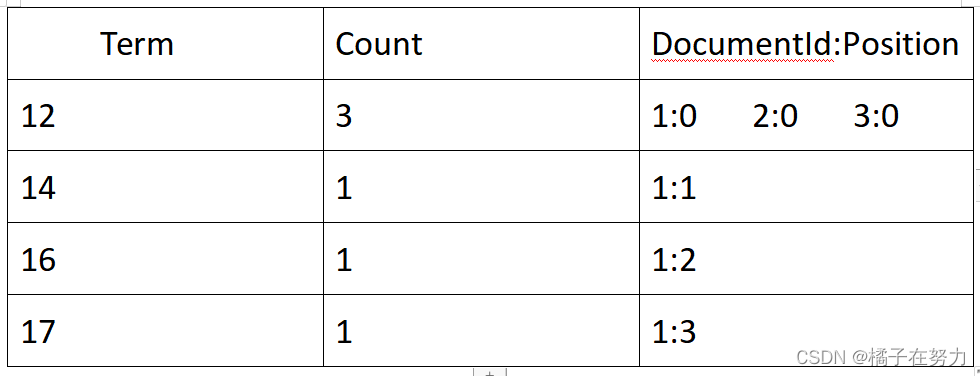
先来解释一下这个表的各个数据的含义。
Team列就表示你的那些词,我们这里就是12,14,16.17
Count表示的是每个词总共出现的次数。我们12这个词在上面一共出现了三次。
DocumentId:Position表示的是这个词分别出现在哪个文档的id以及在文档中的位置。12在三个文档中都有出现,而且位置都是第一位,位置从0开始计数。其余的类似。
此时就是一个倒排索引结构,此时我们要查一下12的文档,直接找到12,然后发现他分别出现在1,2,3三个文档中,直接检索这三个文档就好了。这样就简单了。
注意,倒排索引和上面MYSQL的正排索引没有高低之分,只是检索场景不同。mysql不注重全文检索,他是记录检索,所以不需要以检索内容作为目录项。而倒排索引是以文档为检索项目的,所以他是提取的检索项目作为目录,直接定位文档。
2、倒排索引的核心组成部分
我们上面讲的实际上是倒排索引的一部分,叫做倒排列表。但实际上你想想,你要做检索,输入一个词汇,你要定位这个词汇到底在倒排列表的位置的,所以还需要存一份这个定位的映射关系。
所以真正的倒排索引分为两部分。
2.1、单词词典
记录所有文档的单词,记录单词到倒排列表的关联关系。单词词典的大小一般比较大,可以通过B+树或者哈希拉链法来实现,满足高性能存储查询。
2.2、倒排列表
上面说过了,记录了单词和真实文档的对应关系,由倒排项组成。
- 文档ID:就是文档的ID。
- 词频:单词在文档中出现的次数,用于相关性评分。
- 位置:单词在文档中分词的位置,用于语句检索。
- 偏移:单词在文档中的开始字符位置,结束字符位置,实现高亮显示用。
举个例子:
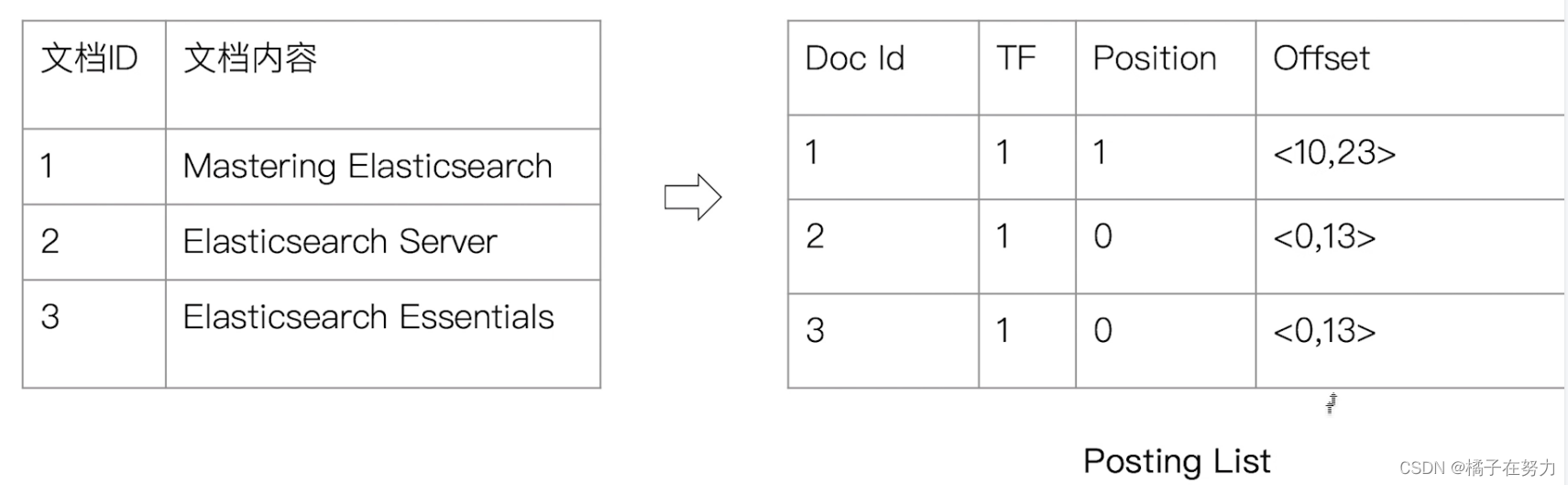
我们以Elasticsearch这个词为例,他的文档形成的这个词的倒排表就是右边那样的。
注意,我们上面说的都是词汇的倒排索引,到了ES中,因为分词机制的存在,文档会被分词成为一个个字段,每个字段都会有自己的倒排索引。可见他的性能其实付出了空间的代价,空间换时间没啥好说的。至于如何分词后面到了分词的时候再说。
也可以在创建索引的时候在Mapping中指定对哪些字段不做索引,比如你永远不查的那种字段你建立也没用,还能节省空间,但是这个词就不能被检索了。
三、倒排索引实战
倒排索引其实本质上是个思想,你可以以各种形式来实现他。比如我们可以不存偏移位置也没啥,顶多就是不做高亮而已。这也不会死。所以只要你明白了为啥要做索引倒排,在实际开发中是可以实际使用这个东西的。
1、为啥要倒排索引
我们上面其实说了,当我们要通过内容去找到整个记录的时候,正排索引只能一个个去匹配,做不到直接定位。而倒排索引是把内容拆分分词来做的目录项,可以直接定位记录。这就是设计倒排索引的目的。
2、实战使用
假如有这么个场景,橘子商城现在要营销活动,活动有其参与规则。橘子商城规定,
- 活动1:男的进来买A类商品有优惠。女的进来买B类商品有优惠。
- 活动2:大于35岁的进来买C类有优惠,小于35的买D类有优惠,不限男女。
- 活动3:户籍所在地是大同的买E类有优惠。
我们看到这次营销活动中,规则是有多个的,每个人可能符合一个或者多个规则,享受不同的优惠。那么此时问题来了,当你支付的时候,判断你满足那些活动,你怎么判断。有两种方式。
方案1:简单粗暴
我们把活动和其规则存成一个表,每个人支付的时候去遍历活动,然后根据自己的信息判断满足哪些规则。这样很直接,有多少活动就遍历多少个数据。

这时候我们该思考一下,我们自己的信息是确定的,我们不妨把数据做成倒排结构,直接定位符合我们信息的活动规则不就行了,为啥要全部遍历呢,于是倒排索引登场。
方案2:索引倒排
这里这种方式你怎么设计存储都行,看你自己,肯定是比上面那种只有一张表要多个一两张表的。也是时间换空间。
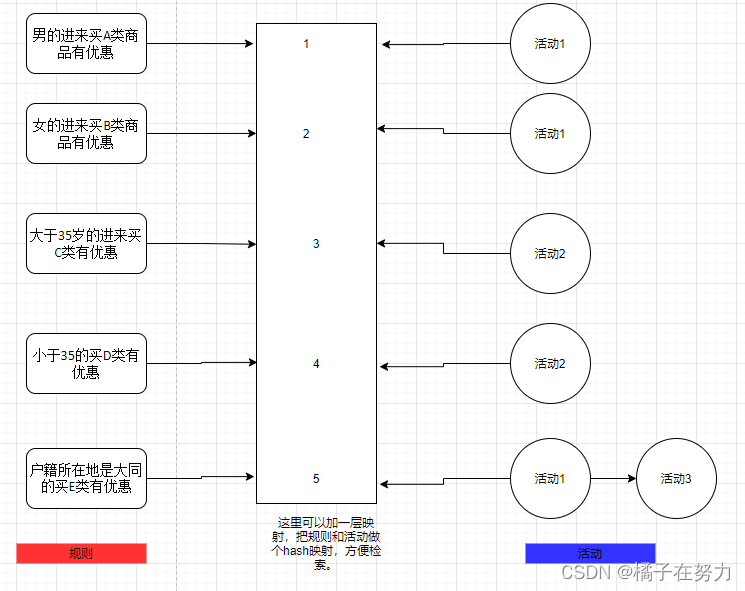
这样我们每个人进来支付的时候,自己的信息是确定的,也就是能直接定位到规则,比如你是个男的,26岁,大同人,你直接就定位到三个规则,进而找到三个活动,不需要你挨个遍历了。这种在于大型营销的时候,活动众多的时候还是能省不少开销的。你要是就两个活动也没必要设计了。
四、总结
倒排是一种思想,可以有各种实现。在ES中是为每个分词都做了倒排,所以还有分词的东西介入。所以后面我们在接入分词的知识后不断的加深对于倒排的理解,继续回来完善这里的知识。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









