







1、volatile简介
在嵌入式开发中关键字volatile经常被提及,其本质是说:被volatile修饰的变量每次都要到内存中获取后再使用,而不是直接使用寄存器中临时数据;
在单片机内核中存在多个寄存器,以Cortex-M3内核单片机为例,该类型单片机有R0~R15共16个寄存器,R0~R12为通用寄存器,R13为栈指针寄存器、R14为链接寄存器LR、R15为程序计数器PC。
在编译器编译代码时候,有时候为了优化代码空间或代码运行时间,在读取变量时直接使用寄存器中的变量,而不是从RAM中读取数据,代码举例:
uint8_t test = 1;
void main(void)
{
……
while(test < 1000);
……
}
// 中断代码
void xxx_Handle(void)
{
……
test++;
……
}由于变量test没有volatile修饰,如果开启了优化,main函数中可能会直接使用寄存器中存储的临时test值,而不再从变量地址处读取变量;这就导致,即使产生了相应中断并修改了test值,可main函数不知道,使得main函数陷入该死循环,进而死机;从下面是在MDK中设置优化等级为3时编译后的汇编代码:(本文使用的MDK版本为:5.36)

其中1000=0x3E8 ,
0x08000982:将test变量地址加载到寄存器R0中;
0x08000988:将test变量值加载到寄存器R0中;
0x0800098A:比较r0、r1,也就是比较寄存器中的test和1000,比较失败继续比较;显然,寄存器中存的test一直都是1,代码自此陷入死循环。
当然,如果没有开启优化,编译器编译出来的代码都会从RAM中读取变量值来进行比较,下面是同样的代码,只是将编译器优化等级改为了0,即不优化后生成的汇编代码:
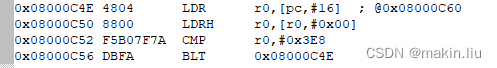
0x08000C4E:将test变量地址加载到寄存器R0中;
0x08000C50:将test变量值加载到寄存器R0中;
0x08000C52:比较r0、r1,也就是比较寄存器中的test和1000,比较失败代码跳转到0x08000C4E,重新读取test变量值到r中,然后再次比较。
2、volatile常见用法
2.1、硬件接口中的应用
我们在使用STM32的库时,经常会见到类似下面的结构体:
typedef struct
{
__IOM uint32_t CTRL; /*!< Offset: 0x000 (R/W) SysTick Control and Status Register */
__IOM uint32_t LOAD; /*!< Offset: 0x004 (R/W) SysTick Reload Value Register */
__IOM uint32_t VAL; /*!< Offset: 0x008 (R/W) SysTick Current Value Register */
__IM uint32_t CALIB; /*!< Offset: 0x00C (R/ ) SysTick Calibration Register */
} SysTick_Type;这些结构体的成员变量用_I、_IO、_IM、_IOM这样的宏定义修饰符修饰,将该宏定义展开后的代码为:
#ifdef __cplusplus
#define __I volatile /*!< Defines 'read only' permissions */
#else
#define __I volatile const /*!< Defines 'read only' permissions */
#endif
#define __O volatile /*!< Defines 'write only' permissions */
#define __IO volatile /*!< Defines 'read / write' permissions */
/* following defines should be used for structure members */
#define __IM volatile const /*! Defines 'read only' structure member permissions */
#define __OM volatile /*! Defines 'write only' structure member permissions */
#define __IOM volatile /*! Defines 'read / write' structure member permissions */使用volatile const修饰的寄存器为只读寄存器,仅用volatile修饰的寄存器可读、可写。如下表为systick寄存器列表,其中CALIB就为只读,所以ST在库中使用_IM关键字修饰该寄存器。

之所以要用volatile修饰,就是保证不论是否使用了优化,都能够从寄存器地址处读取;而使用volatile const修饰,只是表明该寄存器为只读,但不代表该寄存器值不会变,只是这种变是由芯片自身将其改变的。
2.2、软件延时函数中的应用
……
while(delay-- > 0);
……该延时函数在MDK中优化等级为0时编译的汇编代码:

下面是延时函数在MDK中优化等级为1或2时编译的汇编代码:(先将R0结果装载到delay变量地址处,然后再比较)

下面延时函数在MDK中优化等级为3时编译的汇编代码:(只对R0做比较,在R0比较成功后才将R0结果装载到delay变量地址处)

在变量被volatile修饰后,延时函数在MDK中优化等级为0时编译的汇编代码:(与没有被volatile修饰时的差别不是很大)

在变量被volatile修饰后,延时函数在MDK中优化等级为3时编译的汇编代码:(每次比较前都会重新获取delay变量地址处的值)
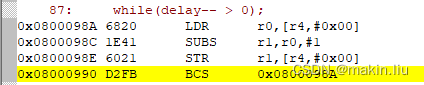
总结:在MDK中的软件延时函数中,不管有没有加volatile,优化后的延时时间都会变短;但加volatile修饰后,该变化相对较小一些。
当然,不同的编译器对代码的优化方式不一样,曾经见过一个资料:有的编译器会将类似while(delay-- >0); 这样的指令,如果没有加volatile修饰,会将其优化成一条指令,导致实际只延时了一条指令的时间;但我还没用到过这样的编译器,就不多介绍。
2.3、多任务/中断中的应用
中断完全可以看成是一种优先级比较高的任务,对比一下下面几个任务:
void TaskA(void const * argument)
{
while(test < 10000);
for(;;)
{
osDelay(1000);
SEGGER_RTT_printf(0, "test:%d\r\n", test);
}
}
void TaskB(void const * argument)
{
for(;;)
{
while(test < 10000);
osDelay(1000);
SEGGER_RTT_printf(0, "test:%d\r\n", test);
}
}
void funC(void)
{
while(test < 10000);
osDelay(1000);
SEGGER_RTT_printf(0, "test:%d\r\n", test);
}
void TaskC(void const * argument)
{
for(;;)
{
funC();
}
}
变量test在其他任务或中断中不断执行test++;如果test没有被volatile修饰,MDK中的优化等级设置为3,TaskA、TaskC都将会死机,而TaskB不会。直接放在for循环中,由于每个循环都会读取变量在RAM中的值,故而不会死机;但在TaskA、TaskC这两种情况就不会这么幸运了,他们都只会使用寄存器中的拷贝来做相关事情。
但是下面的代码将会被正确执行:
void funD(void)
{
if(test < 2000)
{
return;
}
osDelay(1000);
SEGGER_RTT_printf(0, "test:%d\r\n", test);
}
void TaskD(void const * argument)
{
for(;;)
{
funD();
}
}主要原因是:在每次进入函数funD后,都会重新从test变量地址处获取当前值,如果这里不是像TaskC中的funC一样多次读取test,就不存在被优化的说法。
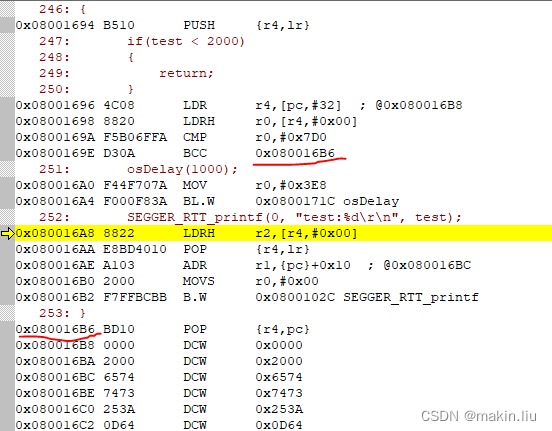
图中0x08001694/0x08001696就是每次进入funD后重新读取test变量地址处的值。
总结:在MDK编译器中,只有在连续多次读取某个变量时才存在没有加volatile修饰而被优化的说法。至于其它类型编译器的编译效果是个什么样子,就靠各位看官自己整理了。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









