









1.5 预测情形
1.5.1 波动率情形
客户端自主随机数生成器可以用于冲击具有特定模式的情况。比如,假定你想知道5天大约平均值的冲击会发生什么。在大多数情况下,此类冲击具有单位方差。但是,可以会产生4倍方差或两倍标准差的情况。
另外一种情形可能是特定冲击期间的样本导致。当使用标准自举方法(历史模拟过滤)时,冲击可以通过历史数据的正态分布刻画出来。当该方法符合实际情况时,可能比较适合描绘特定期间的情形。这可以通过使用客户自主随机数生成器来实现。当统一从全部历史数据中抽样时,这种策略可以精确的从内部展示出历史模拟过滤法是如何执行的。
首先配置一下前提条件:
import matplotlib
# %matplotlib inline
from arch.univariate import ConstantMean, GARCH, Normal
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn
import pandas_datareader as pdr
seaborn.set_style('darkgrid')
seaborn.mpl.rcParams['figure.figsize'] = (10.0, 6.0)
seaborn.mpl.rcParams['savefig.dpi'] = 90
seaborn.mpl.rcParams['font.family'] = 'serif'
seaborn.mpl.rcParams['font.size'] = 14 NASDAQCOM
DATE
2000-01-03 4131.15
2000-01-04 3901.69
2000-01-05 3877.54
2000-01-06 3727.13
2000-01-07 3882.62该例使用了NASDAQ指数收益率。这种自举情形使用2008年金融危机发生前至期间的数据。
下一步,计算收益率,并使用收益率数据来构建模型。该模型可用已有的程序模块构建。这是一种标准化模型,相当于使用如下方法构建:
mod = arch_model(rets, mean='constant', p=1, o=1, q=1)这种构建模型的优点之一,就是模型模拟所用的NumPy的 RandomState结果可以由外部决定。如果需要的话,这允许生成器种子很容易设定及重置状态。
注意:估计ARCH模型时,通常使用百分数表示比较方便。这有助于优化器进行转换,因为波动率截距大小更接近于模型中其他参数。
rets = 100 * nasdaq.pct_change().dropna()
# Build components to set the state for the distribution
random_state = np.random.RandomState(1)
dist = Normal(random_state=random_state)
volatility = GARCH(1, 1, 1)
mod = ConstantMean(rets, volatility=volatility, distribution=dist)res = mod.fit(disp='off')
res拟合结果为标准模型。
Constant Mean - GJR-GARCH Model Results
==============================================================================
Dep. Variable: NASDAQCOM R-squared: -0.000
Mean Model: Constant Mean Adj. R-squared: -0.000
Vol Model: GJR-GARCH Log-Likelihood: -7472.03
Distribution: Normal AIC: 14954.1
Method: Maximum Likelihood BIC: 14986.3
No. Observations: 4695
Date: Wed, Feb 13 2019 Df Residuals: 4690
Time: 10:01:54 Df Model: 5
Mean Model
============================================================================
coef std err t P>|t| 95.0% Conf. Int.
----------------------------------------------------------------------------
mu 0.0297 1.491e-02 1.992 4.643e-02 [4.704e-04,5.893e-02]
Volatility Model
=============================================================================
coef std err t P>|t| 95.0% Conf. Int.
-----------------------------------------------------------------------------
omega 0.0169 4.601e-03 3.670 2.424e-04 [7.868e-03,2.590e-02]
alpha[1] 7.0146e-16 7.140e-03 9.825e-14 1.000 [-1.399e-02,1.399e-02]
gamma[1] 0.1265 1.744e-02 7.251 4.137e-13 [9.228e-02, 0.161]
beta[1] 0.9256 1.244e-02 74.415 0.000 [ 0.901, 0.950]
=============================================================================
Covariance estimator: robust
ARCHModelResult, id: 0xefc5ac8GJR-GARCH模型默认支持解析预测,使用估计所得到的参数,预测2017年全部数据。
h.01 h.02 h.03 ... h.08 h.09 h.10
DATE ...
2017-01-02 0.580045 0.590476 0.600792 ... 0.650674 0.660320 0.669858
2017-01-03 0.553798 0.564522 0.575126 ... 0.626404 0.636320 0.646126
2017-01-04 0.529503 0.540497 0.551369 ... 0.603940 0.614105 0.624158
2017-01-05 0.507015 0.518259 0.529378 ... 0.583145 0.593543 0.603824
2017-01-06 0.486199 0.497675 0.509023 ... 0.563897 0.574509 0.585002
所有的GARCH 设定都是一致的,也就是说它们都表明了一种分布。这可以通过模型假定来模拟。forecast函数可以用来使用假定分布来产生模拟数据,具体方法为:method='simulation'.
这些预测与上述解析预测类似。随着模拟数值趋向无穷大,基于模拟的预测将会收敛于解析值。
h.01 h.02 h.03 ... h.08 h.09 h.10
DATE ...
2017-01-02 0.580045 0.590403 0.598096 ... 0.640617 0.647898 0.656073
2017-01-03 0.553798 0.567418 0.581017 ... 0.627658 0.633192 0.641493
2017-01-04 0.529503 0.541442 0.552064 ... 0.600379 0.612958 0.622361
2017-01-05 0.507015 0.516400 0.526907 ... 0.576138 0.587728 0.593812
2017-01-06 0.486199 0.495461 0.505577 ... 0.565625 0.574218 0.5886341.5.2 自主随机数生成器
forecast 方法可以将模型的残差分布修改为任何一种生成器。一种冲击生成器通常应该产生单一的方差。然而,在这个案例中,前五个冲击产生了2倍方差,然而其余的为标准方差。这种情形包含了一种持续变化的波动率,且因某种原因而发生了改变。
预测方差比前面提到的任何一种方差都要大,并且变化更快。这反映了在最初5天里波动率的增长。
i
import numpy as np
random_state = np.random.RandomState(1)
def scenario_rng(size):
shocks = random_state.standard_normal(size)
shocks[:, :5] *= np.sqrt(2)
return shocks
scenario_forecasts = res.forecast(start='1-1-2017', method='simulation', horizon=10, rng=scenario_rng)
print(scenario_forecasts.residual_variance.dropna().head()) h.01 h.02 h.03 ... h.08 h.09 h.10
DATE ...
2017-01-02 0.580045 0.627008 0.670593 ... 0.835040 0.839207 0.846161
2017-01-03 0.553798 0.605332 0.660221 ... 0.816872 0.818132 0.8239171.5.3 自举情形
forecast方法支持历史模拟过滤法(FHS) ,使用参数: method='bootstrap'. 这是一种有效的模拟方法,其产生的模拟冲击是采用正态分布方法,从历史去中心化和标准化的收益率数据中随机抽取。 自主自举法是rng方法的另一种应用。这里使用一种对象来表示冲击,该对象通过rng方法,类似于随机数生成器,不同的是它仅仅返回使用冲击参数产生的值。
FHS的内部运行采用的shocks包含全部历史数据,这与实际情况一致。
h.01 h.02 h.03 ... h.08 h.09 h.10
DATE ...
2017-01-02 0.580045 0.627731 0.671806 ... 0.916472 0.973876 1.038470
2017-01-03 0.553798 0.601034 0.643942 ... 0.876280 0.930863 0.984509
2017-01-04 0.529503 0.573559 0.615961 ... 0.870309 0.931131 0.988081
2017-01-05 0.507015 0.551867 0.598752 ... 0.833911 0.883571 0.947948
2017-01-06 0.486199 0.520973 0.557449 ... 0.814151 0.863551 0.909780
[5 rows x 10 columns]1.5.4 差异图形化
最终预测值可用来说明差别程度。解析法和标准模拟法本质上是 一致的。模拟情形中,差异在最初5个时期内快速增加,然后减慢。 自举情形下,差异快速上升,且与金融危机发生冲击的程度一致。
import pandas as pd
df = pd.concat([forecasts.residual_variance.iloc[-1],
sim_forecasts.residual_variance.iloc[-1],
scenario_forecasts.residual_variance.iloc[-1],
bs_forecasts.residual_variance.iloc[-1]], 1)
df.columns = ['Analytic','Simulation','Scenario Sim','Bootstrp Scenario']
# Plot annualized vol
subplot = np.sqrt(252 * df).plot(legend=False)
legend = subplot.legend(frameon=False)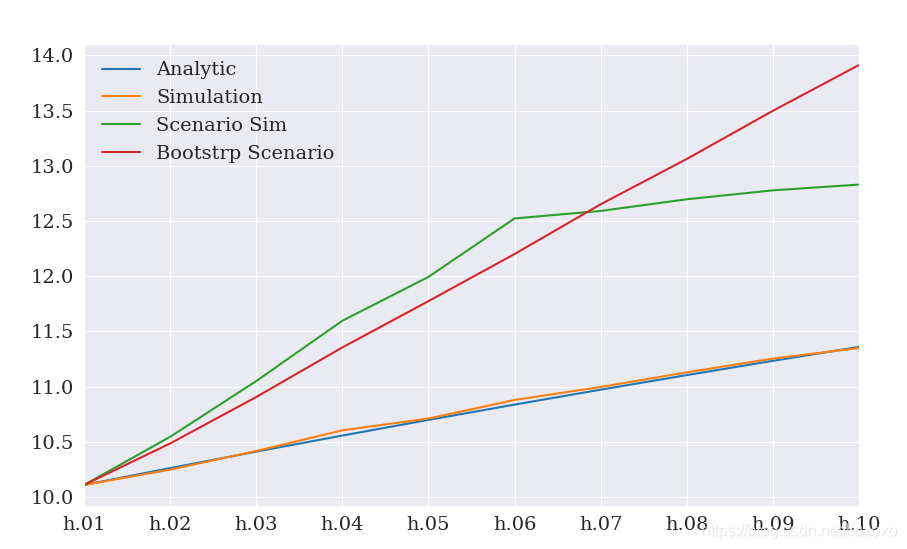
1.5.5 路径比较
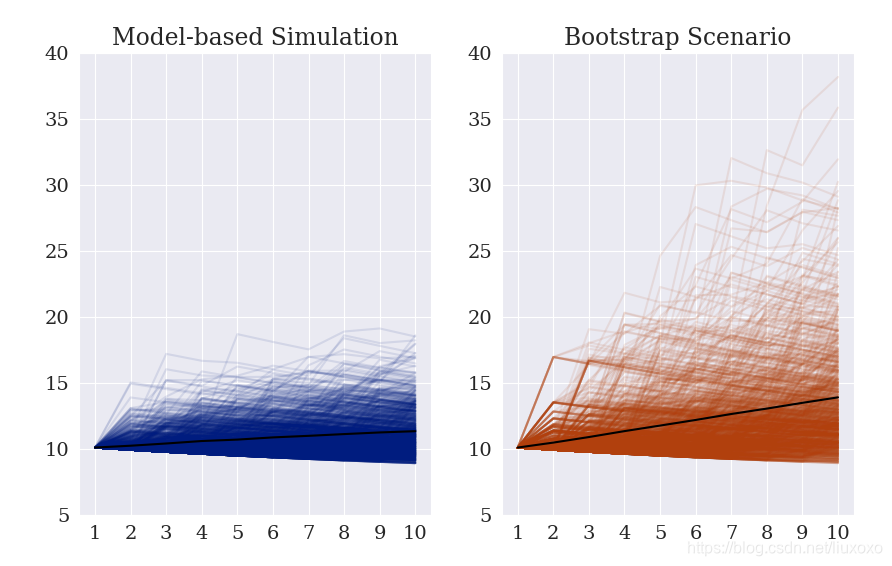
不同的路径可以通过 simulations属性来实现. 绘制路径可以将上图所示的两者之间超越平均差别的显著性变化表示出来。两者始于同一点:
fig, axes = plt.subplots(1, 2)
colors = seaborn.color_palette('dark')
# The paths for the final observation
sim_paths = sim_forecasts.simulations.residual_variances[-1].T
bs_paths = bs_forecasts.simulations.residual_variances[-1].T
# Plot the paths and the mean, set the axis to have the same limit
axes[0].plot(np.sqrt(252 * sim_paths), color=colors[0], alpha=0.1)
axes[0].plot(np.sqrt(252 * sim_forecasts.residual_variance.iloc[-1]),
color='k', alpha=1)
axes[0].set_title('Model-based Simulation')
axes[0].set_xticklabels(np.arange(1, 11))
axes[0].set_ylim(5, 40)
axes[1].plot(np.sqrt(252 * bs_paths), color=colors[1], alpha=0.1)
axes[1].plot(np.sqrt(252 * bs_forecasts.residual_variance.iloc[-1]),
color='k', alpha=1)
axes[1].set_xticklabels(np.arange(1, 11))
axes[1].set_ylim(5, 40)
title = axes[1].set_title('Bootstrap Scenario')
1.5.6 跨年比较
一种 hedgehog绘图方法在描绘这两种预测方法的跨年而非跨日差别时比较有用。
analytic = forecasts.residual_variance.dropna()
bs = bs_forecasts.residual_variance.dropna()
fig, ax = plt.subplots(1, 1)
vol = res.conditional_volatility['2017-1-1':'2018-1-1']
idx = vol.index
ax.plot(np.sqrt(252) * vol)
for i in range(0, len(vol), 22):
a = analytic.iloc[i]
b = bs.iloc[i]
loc = idx.get_loc(a.name)
new_idx = idx[loc + 1:loc + 11]
a.index = new_idx
b.index = new_idx
ax.plot(np.sqrt(252 * a), color=colors[1])
ax.plot(np.sqrt(252 * b), color=colors[2])
labels = ['Annualized Vol.', 'Analytic Forecast',
'Bootstrap Scenario Forecast']
legend = ax.legend(labels, frameon=False)














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









