







https://arxiv.org/pdf/2004.10361.pdf
通过引用透明性测试机器翻译
Github:https://github.com/ReferentialTransparency/RTI(无代码)
由于神经网络的复杂性和难解性,现代机器翻译软件还远远不够健壮,因此作者引入一种简单而广泛用于验证机器翻译软件的方法 referentially transparent inputs (RTIs),它的输入是一段文本,在不同上下文中翻译结果不变,具体实现是使用纯度 Purity 检测这种翻译不变性什么时候被打破。对 Google Translate 和 Bing Microsoft Translator 使用 Purity 进行测试,200句中分别检测出123、142个错误翻译,准确率为 79.3%、78.3%,翻译错误包括欠翻译、过度翻译、词/短语误译、修饰错误、逻辑不清等。
1 INTRODUCTION
机器翻译软件的目标是将源语言的文本完全自动化地翻译成目标语言。近年来,由于神经机器翻译 NMT 模型的发展,机器翻译软件的性能得到了显著提高,特别是机器翻译软件(如 Google Translate 和 Bing Microsoft Translator)在人类评价方面正在接近人类水平。越来越多的人在日常生活中经常使用机器翻译,如阅读外文新闻和课本,出国旅游时的交流,以及进行国际贸易。2016年,谷歌翻译吸引了超过5亿用户,每天翻译超过1000亿字。此外,NMT 模型已经嵌入到各种软件应用程序中,如 Facebook 和 Twitter。与传统的软件(如Web服务器)类似,机器翻译软件的可靠性也是非常重要的,然而由于支持这些系统的神经网络非常复杂,现代翻译软件可能会返回错误的译文,从而导致误解、经济损失、对个人安全和健康的威胁以及政治冲突。最近的研究揭示了基于神经网络的系统的脆弱性,例如自动驾驶汽车软件、情绪分析工具和语音识别服务。NMT 模型也不例外,它们可能会被对抗性的例子(如源文本中的干扰字符)或自然噪声(如打字错误)所愚弄,这些方法生成的输入大部分是非法的,即它们包含词汇错误(如“bo0k”)或语法错误(如“he home went”)。然而,机器翻译软件的输入通常在词汇和语法上是正确的,腾讯公司称其嵌入的 NMT 模型可能会返回错误的翻译,即使输入没有词汇和语法错误。
机器翻译软件的自动化测试是一个有待解决的问题,而且非常具有挑战性。首先,与传统的软件相比,神经机翻译软件的逻辑很大程度上嵌入在后端模型的结构和参数中,因此现有的基于代码的测试技术不能直接用于测试 NMT;其次,现有的AI软件测试方法主要针对更简单的用例(如10-class分类),相比之下,测试机器翻译是一项更困难的任务:一个源文本可以有多个正确的翻译,并且输出空间要大得多;第三,现有的机器翻译测试技术通过语言模型替换一个句子中的一个单词来生成测试用例(即合成句子),因此它们的表现受到现有语言模型的熟练程度的限制。
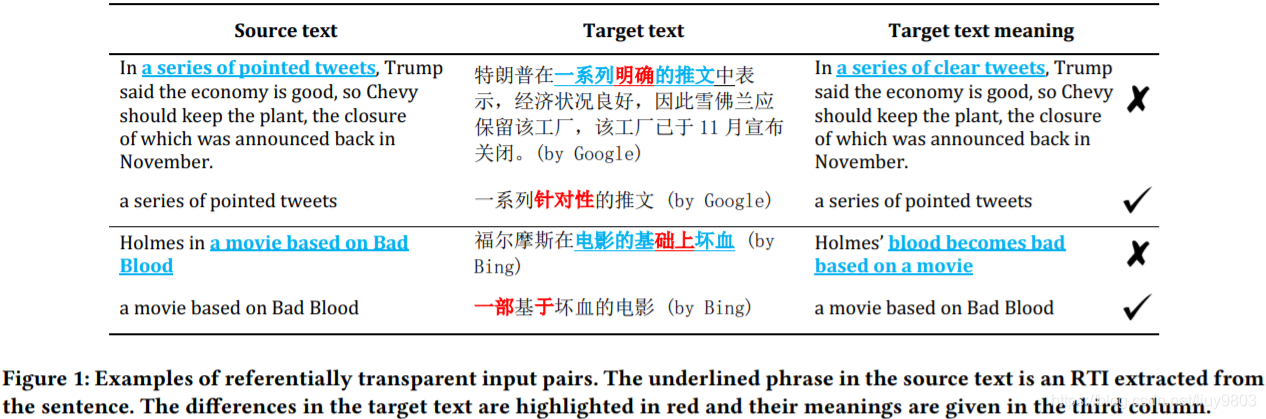
为了解决这个具有挑战性的问题,作者引入 RTIs(引用透明性输入),这是一个用于评价机器翻译软件的新颖而通用的概念。RTI 的核心思想来自于编程语言(尤其是函数式编程)中的一个概念,即引用透明性:方法应该总是为给定的参数返回相同的值。在本文中,将 RTI 定义为在不同上下文中具有固定翻译的文本。关键是生成包含相同 RTI 的一对文本,并检查这对文本的翻译是否不变。为了实现这个概念,作者实现了 Purity,一个从任意未标记的句子中提取短语的工具,具体是,给定一个源句,Purity 通过 constituency parser 提取短语,并通过将 RTI 与其包含的句子或短语分组来构造 RTI 对。如果同一 RTI 的译文之间差异很大,则将这对文本及其译文报告为一个可疑的问题。图1给出了 RTIs 和实际翻译错误的例子。本文的核心思想在概念上不同于现有的方法,现有方法的上下文是固定的,只替换了某个词,并假设翻译应该只有小的变化;相反,本文假设 RTI 的翻译在不同的句子/短语之间应该是不变的,上下文可变。
使用 Purity 测试 Google Translate 和 Bing Microsoft Translator,200个句子是 He et al. 从CNN抓取的,Purity 成功发现了谷歌翻译中154个错误翻译对,以及微软必应翻译中177个错误翻译对,准确率分别为79.3%和78.3%,分别揭露了123和142个错误翻译。所发现的翻译错误是多种多样的,包括翻译不足、过度翻译、词/短语误译、修饰错误和逻辑不清。与最先进的翻译技术相比,Purity 可以发现更多的错误译文,而且准确率更高。另外,由于概念上的差异,Purity 可以找出很多现有方法无法发现的错误,如图6所示。Purity 在谷歌翻译和微软必应翻译平均用时为12.74s和73.14s,达到了 sota 的效率。所有被发现的错误翻译都发布在了 Github 上以供独立验证,源代码也即将发布。
论文贡献:
• 引入一个新颖的、广泛适用的概念:引用透明性 RTI,用于机器翻译评价;
• 引入了 Purity,RTI 的一种实现方式,使用 constituency parser 提取短语,以及一个词袋 BoW 模型来表示翻译;
• 基于200个未标记句子,Purity 成功发现了谷歌翻译中的123个错误翻译,以及微软必应翻译中的142个错误翻译,准确率分别为79.3%和78.3%。
2 BACKGROUND
2.1 Referential Transparency
在编程语言领域,引用透明性是指在不改变程序结果的情况下,一个表达式可以被其在程序中的相应值所替换的能力。例如,数学函数(如平方根函数)是引用透明的,而打印时间戳的函数则不是。引用透明性是函数式编程的一个关键特性,因为它允许编译器推断程序行为,促进了 high-order functions(即一系列函数可以连在一起)和 lazy evaluation。
2.2 机器翻译软件
给定源语言的一个句子或文本 S = s1, s2, ..., sM,机器翻译软件的目标是返回目标语言的 T = t1, t2, ..., tN。现代机器翻译系统的核心是具有编码器-解码器架构的神经网络,编码器本质上是一个映射 S 为编码的函数:
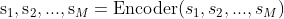
在推理过程中,使用源句的编码和之前的解码,通过模型计算下一个符号的概率分布:
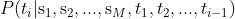
然后使用近似搜索算法,如 beam search,求出最高概率的 T' = t'1, t'2, ..., t'N' 作为模型的输出,链式法则计算:
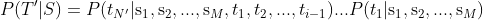
为了提高性能,现代机器翻译软件采用了各种相应的技术,如处理词汇表外单词 OOV 的字节对编码(byte pair encoding, BPE),为更好地解码而进行的不同的集束搜索,以及为加快模型训练而进行的数据/模型并行化处理。本文将机器翻译软件看作一个黑盒,提出了一种检测潜在翻译错误的方法。如果一个翻译是不正确的,称为 erroneous translation 错误的翻译,错误的翻译包含一个或多个翻译错误,翻译错误是指原文某些部分的误译。
3 RTI AND PURITY'S IMPLEMENTATION
RTI 定义为跨文本(句子和短语)翻译不变的一段文本。例如,图1中的“a movie based on Bad Blood”是一个 RTI。给定一个句子,找到它的 RTIs 构造测试输入。Purity 的输入是一个无标记的单语句子列表,输出是一个可疑问题列表,每个问题包含两对文本:一个基本短语即 RTI 和它的容器短语/句子,以及它们的翻译,Purity 可以检测到短语或容器的翻译错误。

图2为 Purity 的概览,主要包括以下四个步骤:
(1) Identifying referentially transparent inputs 分析每个句子的成分,提取短语列表作为 RTIs;
(2) Generating pairs in source language 将每个短语与包含它的短语或原句配对,形成 RTI 对。
(3) Collecting pairs in target language 将 RTI 对输入被测机器翻译软件,收集相应的译文。
(4) Detecting translation errors 比较每一对的 RTI 对的译文,如果 RTI 的翻译之间存在很大的差异,则认为这对翻译可能存在翻译错误。
算法1为 RTI 实现的伪代码:

3.1 Identifying RTIs
为了收集一个 RTIs 列表,需要找到具有独特意义的文本片段,这个意义应该在不同的上下文中都适用。为了保证 RTIs 在词汇和句法上的正确性,从已发表的文章中提取它们;为了简单和避免语法上的奇怪短语,本文只考虑名词短语。具体是从源语言的一组句子中提取名词短语,作为 RTIs。例如,在图2中,“chummy bilateral talks”一词将被提取出来,这个短语在不同的句子中应该有固定的翻译。
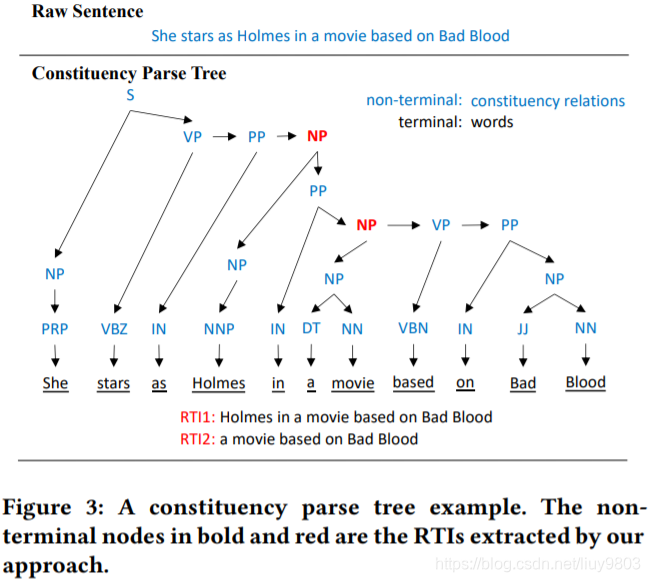
使用 NLP 工具 constituency parser 输出字符串的句法树结构,非叶结点是 constituency relations 成分结构关系,叶结点是单词,如图3所示。遍历成分树并提取所有 NP(noun phrase 名词短语)关系。
"""
Consituent 是语法分析的一个基本术语,指一个语言单位,可大可小,大到分句,小到语素,还有单词、词组等都属于该范畴。
Constituency relation 将一个句子解析为一系列成分结构,即对句子做层级结构分析,如主语+谓语,名词短语+动词短语等,这种结构又可进一步解析出各自的成分(例如名词短语可以分为限定词+名词),不断解析直到不能分出更小的成分为止。
Dependency relation 依存关系认为动词是句子中最重要的中心单位,且为名词短语所依附。这种语法在结构式的各成分之间建立各种类型的依存关系,用来解释各种语法关系。句法结构采用依存树表示,每棵树包含一个支配语和一组依附语,每个依附语与支配语有特定的关系。依存关系通常用弧线表示,弧线连接的是词(而不是结构成分)。
"""
通常一个 RTI 可以包含另一个较短的 RTI,例如图1中的第二对 RTI 包含两个 RTI:“Holmes in a movie based on Bad Blood”包含“a movie based on Bad Blood”,当名词短语用作 RTIs 时也是如此,因为名词短语可以包含其他名词短语。从一个句子中获得所有的名词短语后,根据经验过滤掉包含10个以上和3个以下的非停止词的词,停止词如 “is”, “this”, “an”等。这种过滤会集中在独特的短语,更有可能只携带单一的意义,可以大大减少 false positives;其余的名词短语可作为 RTIs。注意根据定义 Purity 的策略不能保证所有剩下的名词短语都是 RTIs。
3.2 Generating Pairs in Source Language
生成的 RTIs 列表必须与包含短语配对,这些短语将用于引用透明性验证。具体来说,每个 RTI 对应该有两个包含相同短语的不同文本片段。将 RTI 与发现它的全文(如图2所示)和同一个句子所有包含它的 RTI 配对,如图3所示,构建3对 RTI:(1) RTI1 和原句、(2) RTI2 和原句、(3) RTI1 和 RTI2。
3.3 Collecting Pairs in Target Language
一旦得到一组RTI对,下一步是将这些文本(以给定的源语言)输入到被测机器翻译软件中,并收集它们的翻译(以任何选定的目标语言)。使用谷歌和 Bing 提供的 api,这些 api 返回的结果与二者的 Web 接口返回的内容相同。
3.4 Detecting Translation Errors
最后,为了检测翻译错误,对前一步的翻译对进行 RTI 不变性检查。在翻译中检测 RTI 的错误同时避免假正例是非常重要的,例如图2中,第一对中的 RTI 是“chummy bilateral talks”,考虑到整个源句的中文翻译,很难确定哪些字符指的是 RTI。单词可以重新排序,同时保留其固有的含义,因此 RTI 和容器转换之间的精确匹配不能得到保证。NLP 的单词对齐技术,可以将源文本中的单词/短语映射到目标文本中的单词/短语,然而现有工具的性能很差,运行时可能非常慢。因此采用词袋 BoW 模型,只考虑文本中每个单词的 appearance 外观(注意,这个表征是一个 multiset 多集)。虽然 BoW 模型很简单,但已被证明在许多 NLP 任务中对文本建模非常有效。作者还尝试采用 n-gram 表示对目标文本进行预处理,这提供了类似的性能。

每对翻译都包含对 RTI、Tr 及其容器 Tc 的翻译,在得到两种译文(BoWr 和 BoWc)的 bow 表征后,计算它们之间的距离:
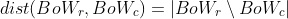
这个 metric 度量 Tr 中出现的单词数量,而不是 Tc 中的,例如,“we watch two movies and two basketball games”(Tc) 和“two interesting books”(Tr) 之间的距离是2。如果距离大于预先定义的阈值 d,翻译对及其源文本将被认为是可疑的,这表明至少有一个翻译可能包含错误。例如图2中的可疑翻译的距离是2,因为中文“亲切”未出现在容器翻译 Tc 中。从理论上说,这个实现不能检测 Tc 中过度翻译的错误,因为额外的词出现在 Tc 中不会改变距离的计算方程,但是这个问题并不经常发生,因为 Tc 的源文本通常是另一对 RTI 中的 RTI,这样就可以在那一对 RTI 中检测到过度翻译错误。
4 EVALUATION
将 Purity 应用到谷歌翻译和微软必应翻译来评估它的性能。具体旨在回答以下研究问题 research questions:
• RQ1: 寻找错误翻译的方法的准确性?
• RQ2: 本方法可以报告多少个独特的错误翻译?
• RQ3: 本方法可以发现哪些翻译错误?
• RQ4: 本方法有多有效?
4.1 Experimental Setup and Dataset
Experimental environments
所有的实验都在一个 Linux 工作站上运行,64-bit Ubuntu 18.04.02,Linux kernel 4.25.0,6核 Intel Core i7-8700 3.2GHz 处理器,16GB DDR4 2666MHz 内存,GeForce GTX 1070 GPU 和 1TB SATAIII 硬盘驱动器 7200rpm。句子解析使用 Zhu et al. 的 shift-reduce parser,该解析器是使用斯坦福的 CoreNLP 库实现的,每秒可以解析50个句子。
Comparison
将 Purity 与两种 sota 方法 SIT、TransRepair (ED) 进行比较,从作者那里获得了SIT的源代码,但由于行业机密性,TransRepair 的作者不能发布他们的源代码。TransRepair 使用0.9作为词向量余弦距离的阈值来生成词对,本实验使用0.8作为阈值,因为无法重现文章中使用0.9所报告的词对数量,且使用0.9作为阈值只会产生少量的单词对。此外,作者使用他们论文中介绍的策略对 SIT 和 TransRepair 的参数进行了 re-tune。
Dataset
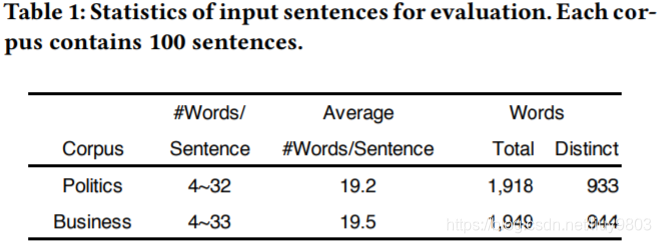
Purity 使用 CNN 文章中收集的数据集,详细信息如表1所示,这个数据集包含两个语料库:Politics 和 Business,使用两类语料是因为想要评估不同语境下句子的 Purity 性能。
4.2 Precision on Finding Erroneous Issues
准确率评估,即有多少报告的问题包含实际的翻译错误。评估谷歌翻译和必应翻译,两位作者分别手动检查所有可疑问题,然后共同决定:(1) 一个问题是否包含翻译错误;(2) 如果是,包含何种翻译错误。
4.2.1 Evaluation Metric
Purity 的输出是一个可疑问题列表,每个问题包含:(1) 一个 RTI,包括源语言的 Sr 及其翻译 Tr;(2) 一段文本,包含源语言 RTI、Sc 及其翻译 Tc。将准确率定义为 Tr 或 Tc 中存在翻译错误的对的百分比,即对于一个可疑的问题 p,如果 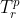 或
或 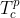 有翻译错误,将 error(p) 设为 true;否则将 error(p) 设为 false。给定可疑问题列表,计算准确率为:
有翻译错误,将 error(p) 设为 true;否则将 error(p) 设为 false。给定可疑问题列表,计算准确率为:
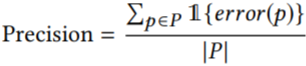
其中 |P| 是由 Purity 返回的可疑问题的数量。
4.2.2 Results
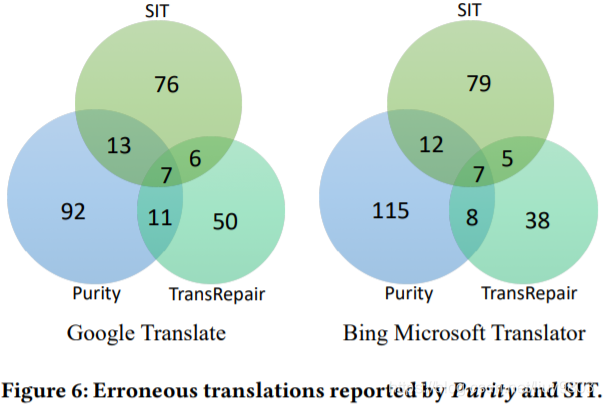
结果见表2,如果打算报告尽可能多的问题(即 d = 0),Purity 达到78% ~ 79.8%的准确率时报告了67 ~ 99个错误问题。如果想要更加精确,可以使用更大的距离阈值,例如当距离阈值为5时,Purity 在所有实验设置中都达到100%的准确率,注意,准确率不会随着阈值的增加而单调增加,对于“Bing-Politics”,将阈值从2改为3时,准确率下降了1.9%,这是因为虽然假正例的数量减少了,但真正例的数量也减少了。
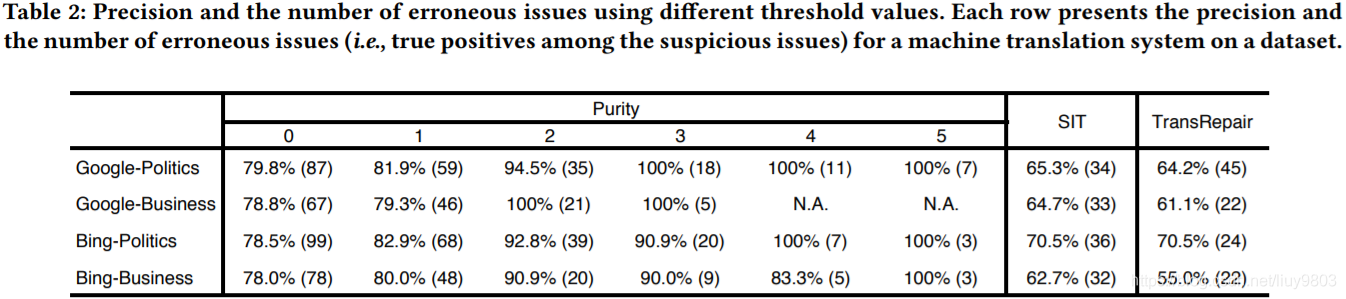
实验表明 Purity 发现的错误问题比 SIT 和 TransRepair 更多,而且准确率更高。Top-1 结果即最有可能包含错误的翻译,为了直接比较,认为 SIT 的 top-1 输出是一个可疑的问题,SIT 的 top-1 输出包含:(1) 源句及其翻译;(2) top-1 生成的句子及其翻译。TransRepair 报告一个可疑句子对列表,将每个句子对视为一个可疑问题。计算 SIT 和 TransRepair 的准确率,结果见表2右边的列,当距离阈值最低 d = 0 时,Purity发现的错误问题更多,准确率更高;当 d = 2 时,Purity检测到错误问题与后两者相近,但准确率要高得多。虽然准确率的比较不是 apples-to-apples 完全一致的,但结果能够体现 Purity 的优越性,原因在于:首先,现有的方法依赖于使用预训练模型(SIT 使用 BERT,TransRepair 使用 GloVe 和 spaCy)生成句子对,尽管 BERT 在这项任务上做得很好,但它可能会生成语义奇怪的句子,导致出现假正例,与此不同的是,Purity 直接从 real-world 句子中提取短语来构建 RTI 对,因此没有这种假正例;另外,SIT 依赖于目标句子表征和比较中的依存句法分析,可能返回错误的依存分析树,从而导致出现假正例。

4.2.3 False Positives
图5中给出了d = 0 时的误报例子,(1)一个短语可以有多个正确的翻译,如第一个示例所示,“parts”在上下文“other parts of the word”中有两个正确的翻译(地方、地区),但是当 d = 0 时,这会成为一个错误,这种类型占了大部分的误报。为了减少这种问题,可以调整距离阈值 d 或维护一个替代的翻译字典。(2)用来识别名词短语的成分分析器可能会返回非名词短语,在第二个例子中,“foreign makers thanks”被识别为名词短语,导致短语意义变化,实验时有6个假正例是由于成分分析器的错误造成的。(3)专有名称通常是音译的,可能会有不同的正确结果,在第三个例子中,名字“Ruth”有两个正确的音译,导致了一个假正例。
4.3 Unique Erroneous Translation
如果一个错误的翻译出现在多个错误问题中,将只被计算一次,与表2相同的实验设置下唯一错误翻译的数量见表3,可以看到,当 d = 0 时,Purity 发现了54个∼74个翻译错误,设置更大的距离阈值以获得更高的准确率,得到更少的错误翻译。例如,如果要达到100%的准确率,则会在谷歌翻译中获得32个错误翻译(d = 3)。
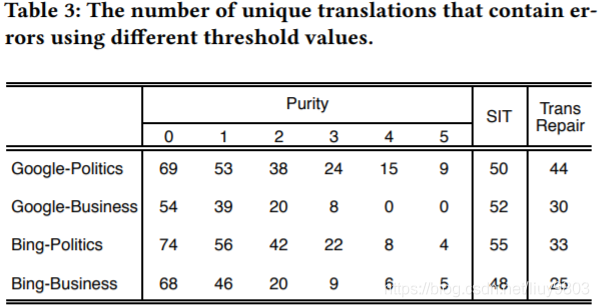
图6通过维恩图展示了 Purity, SIT 和 TransRepair 发现的错误翻译结果,这三种方法都可以检测到来自谷歌翻译和必应翻译的7个错误翻译,207个错误的翻译是 Purity 所独有的,155个错误的翻译是 SIT 所独有的,88个错误的翻译是 TransRepair 所独有的。在检查了所有的错误翻译后,发现 Purity 对发现短语翻译错误十分有效,SIT 的独特错误主要来自于一个名词或形容词之间的相似句,TransRepair 的独特错误主要来自于只有一个数字差别的相似句子(如“five”→“six”)。基于这些实验结果,作者确信他们的方法是 sota 方法的补充。
4.4 Translation Error Reported
Purity 能够发现各种各样的翻译错误,在实验中成功地发现了5种翻译错误:欠翻译、过度翻译、单词/短语误译、修饰错误和逻辑不清。表4给出了不同类型错误的翻译数量,可以看到,词/短语错译和逻辑不清是最常见的翻译错误。检测到的各种翻译错误可以表明 RTI 的有效性和广泛的适用性,将这些错误的定义与 Structure-Invariant Testing for Machine Translation 对齐,因为它是唯一发现并报告这5种翻译错误的现有工作。

4.1.1 Under-translation
如果源文本的某些部分没有被翻译,就是一个欠翻译错误。图7第一个示例是谷歌翻译没有翻译“magnitude of”;第二个示例是必应翻译没有翻译“their way”,欠翻译常导致语义和关键信息的缺失。

4.4.2 Over-translation
如果目标文本的某些部分不是从源文本翻译得来,或者源文本的某些部分被多次不必要地翻译,就是过度翻译错误。图8第一个示例的“was a honor”在目标文本中被谷歌翻译了两次,属于过度翻译错误;第二个示例的目标文本中的“is to build”不是从源目标中的任何单词/短语翻译得来的。过度翻译会带来不必要的信息,容易造成误解。

4.4.3 Word/phrase Mistranslation
如果源文本中的一些单词或短语在目标文本中被错误翻译,就是一个单词/短语误译错误。图9第一个示例的“creating housing”被翻译成“building houses”,这种错误是因一词多义造成的,“housing”一词的意思是“a general place for people to live in”或“a concrete building consisting of a ground floor and upper storeys”,在这个例子中,翻译器误以为“housing”指的是后一个意思,从而导致了翻译错误。除了一词多义的模糊性外,词/短语的误译也可能是由周围语义造成的。在第二个示例中,“plant”被翻译成“company”,作者认为这是因为在 NMT 模型的训练数据中,“General Motors”经常会被翻译成“General Motors company”,从而导致了这种单词/短语误译错误。

4.4.4 Incorrect Modification
如果某些修饰语修饰了错误的元素,就是一个修饰错误。图10第一个示例的“"underfunded and overcrowded”在源文本中修饰“open access colleges”,然而翻译认为修饰“bottom tier”;第二个示例的“better suited for a lot of business problems”应该修饰“more specific skill sets”,然而翻译认为它们是两个独立的子句。

4.4.5 Unclear Logic
如果所有的词都翻译正确,但逻辑是错误的,就是一个逻辑不清错误。图11的第二个示例中,必应正确地翻译了“approval”和“two separate occasions”,然而翻译成“approve two separate occasions”,而不是“approval on two separate occasions”,因为翻译器不理解它们之间的逻辑关系。现代机器翻译普遍存在逻辑不清的问题,这在一定程度上标志着翻译器是否真正理解了语义含义。

4.4.6 Text with Multiple Translation Errors
一些翻译错误包含多种翻译错误,如图12的第一个示例包含三种错误:(1)“top 1%”、“these institutions”和“the bottom fifth of earners”这些短语没有被翻译,所以这些都是欠翻译错误;(2)“top fifth of families”被翻译了两次,而在原文中只出现了一次,所以这是一个过度翻译错误;(3)“attend”、“children”和“parents”的单独翻译虽然正确,但合起来是“children attending parents”,逻辑关系不正确,所以这是一个逻辑不清错误。

4.5 Running Time
使用 Purity 测试谷歌翻译和必应翻译的两个数据集,每种实验运行10次,使用平均时间作为最终结果。表5给出了 Purity 的总运行时间、初始化、RTI对构造、翻译和检测违反引用透明性的详细运行时间。
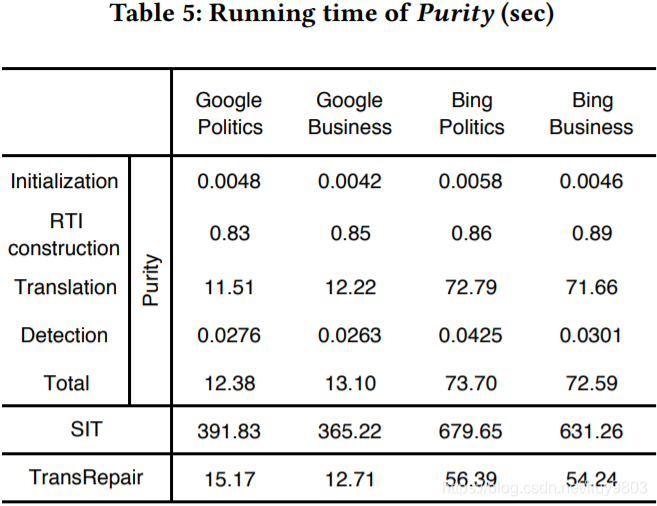
可以看到,Purity 测试谷歌翻译时用时不到15秒,测试必应翻译时用时约1分钟,超过90%的时间花费在使用 API 进行翻译上,实现时为每段源文本都调用一次 API,因此还包括了网络通信的时间。如果开发人员打算测试他们自己的机器翻译软件,这一步的运行时间将更少。表5还列出了使用相同实验设置的 SIT 和 TransRepair 的运行时间,SIT 花了超过6分钟来测试谷歌翻译,大约11分钟来测试微软翻译,这主要是因为 SIT 需要翻译44,414和41,897个单词,而 Purity 和 TransRepair 需要的翻译相对更少(Purity 为7,565和6,479,TransRepair 为4,271和4,087),因此得出的结论是,Purity 取得了 sota 效率。
4.6 Fine-tuning with Errors Reported by Purity
研究发现的错误翻译是否可以作为一个微调集,以提高 NMT 模型的健壮性并快速修复测试中发现的错误。微调在 NMT 中是一种常见的实践,因为目标数据(即运行时使用的数据)的域通常与训练数据的域不同。为了模拟这种情况,在 WMT’18 ZH-EN 语料库上训练了一个具有全局注意力的 Transformer——NMT模型的标准架构,其中包含约 20M 个句子对。为了便于与其他实验进行比较,倒转翻译的方向,使用 fairseq 框架创建模型。为了测试模型,在 CNN 网站的“Entertainment”类别下抓取10篇最新的文章,并随机抽取80个英语句子作为测试集,数据集与主要实验中使用的“Politices”和“Business”数据集保持一致,测试时成功发现了42个错误的翻译,使用正确的翻译对它们进行手动标记,并用这42个翻译对微调 NMT 模型8个 epochs——直到 WMT' 18 验证集上的损失停止减少。经过微调后,42个句子中有40个被正确翻译。两个没有被更正的翻译其中的一个可以归因于解析错误,而另一个(源文本:“"one for Best Director”)有一个“ambiguous reference”问题,使得没有上下文时的翻译很困难。WMT’18 验证集上的 BLEU 评分保持在标准偏差之内,这表明 Purity 报告的错误确实可以在不从头开始重新训练模型的情况下得到修复——一个资源和时间密集型过程。
5 DISCUSSIONS
5.1 RTI for Robust Machine Translation
与传统软件相比,机器翻译软件的 bug 修复过程更加困难,因为 NMT 模型的逻辑包含在一个复杂的模型结构及其参数中。即使可以识别出造成误译的计算之处,但往往不清楚如何改变模型以纠正错误且不引入新错误。虽然模型修正不是本文的主要研究重点,但作者发现,Purity 报告的翻译错误可以用来修正和改进机器翻译软件。对于在线翻译系统,修复误译的最快方法是对翻译对进行硬编码,因此 RTI 发现的翻译错误可以作为早期预警,帮助开发人员避免可能导致负面影响的关键错误,然而这并不能解决神经网络本身所犯的错误,以及由同一问题产生的类似错误,这些错误可能会出现在其他翻译中。更健壮的解决方案是将误译加入训练数据集,重新训练一个大型的神经网络可能需要几天的时间,而对几百个误译进行微调只需要几分钟,即使是对大型的 sota 模型也是如此。虽然这种方法并不能完全保证误译的修复,但是实验表明,这种方法在解决错误方面是相当有效的,而有效的 bug 修复将是未来工作的一个重要方向。
5.2 Change of Language
Purity 以英语为源语言,以汉语为目标语言,但是任何语言对都可以使用,只需要有一个可用的源语言的成分分析器(或者进行训练来创建这样一个分析器)。Stanford Parser (https://nlp.stanford.edu/software/lex-parser.html#Download)目前支持六种语言,或者按照 Zhu et al. 的方法训练一个。其他 Purity 模块保持不变,因此原则上很容易将 RTI 用于其他语言,使其适于各种语言的机器翻译。
6 RELATED WORK(略)
7 CONCLUSION
作者提出了一个简单、通用的概念——引用透明输入 RTI——用于测试机器翻译软件,不同于现有的——扰乱一个自然句中的词(上下文固定),并假设翻译应该只有小的变化——的方法,本文假设 RTIs 应该在不同的上下文中具有不变的翻译,因此 RTI 可以发现不同种类的翻译错误,从而补充现有的方法。测试谷歌翻译和微软必应翻译 ,分别发现了123和142个错误的翻译,且目前用时最短,证明了 Purity 测试机器翻译软件的能力。在未来的工作中,作者将继续细化一般方法,并将其扩展到其他 RTI 实现方式,例如将动词短语作为 RTIs 或将整个句子作为 RTIs,将它们与语义上不相关的句子相连配对,还将在翻译错误诊断和机器翻译系统的自动修复方面开展广泛的工作。

















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









