







最近简单了解了下scrapy,这是一个python的爬虫框架,使用起来比较简单。我的学习时间比较短,所以就不深入,但也要做个记录,以后如果用到比较容易想起来。
安装
我的centos是6.5版本的,自带的python是2.6.6版本的,因为yum是python的脚本,所以不能直接升级成python3,那就在Windows下玩吧。
Windows下直接下载python3的安装包就行了,安装时勾选上将python加入环境变量,不然还得手动设置。然后执行
pip install pip -U升级pip,再执行pip install scrapy即可安装scrapy。
官方pypi被墙了,可以通过pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple来设置使用清华镜像。
有人用virtualenv来创建python的虚拟环境,在虚拟环境里安装scrapy,我嫌麻烦,直接全局安装了。
创建第一个项目
创建项目:
scrapy startproject projectname
scrapy会创建一个名为projectname的目录和一些文件。
进入projectname目录,创建一个爬虫:
scrapy genspider example example.com
example是爬虫的名字,example.com是要爬取网站的域名。
继续进入projectname目录,会看到一些py文件:
settings.py 项目设置相关
items.py 爬取的主要目标就是从非结构性的数据源提取结构性数据,使用 Item 类来描述结构性数据。
middlewares.py 用来实现一些个性化的需求。
pipelines.py 如果你想将爬取到的内容输出到数据库或其他地方,需要修改这个文件。
spiders目录下还有个example.py文件,它的内容如下:
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['example.com']
start_urls = ['http://example.com/']
def parse(self, response):
pass
这里的example是你创建爬虫时的名字。
最简单的工作流程是,从start_urls取到url,然后去爬取,得到内容后调用parse函数,parse函数会返回一个item,我们可以把它输出到文件。parse也可以返回request,跟进额外的url。
在工程目录下执行scrapy crawl example即可开始爬取,可以通过-o指定输出文件,支持csv,xml,json等格式。更多请参考Feed exports。
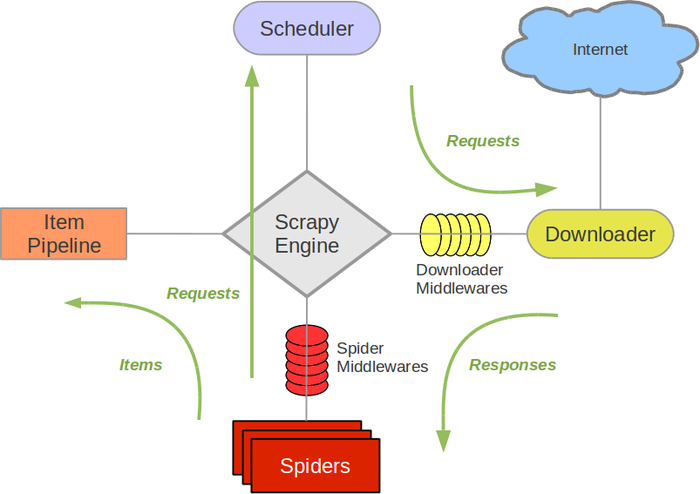
scrapy架构概览
接下来看一下scrapy的结构和数据流,就能对它整体有个认识。
图片来自scrapy-chs.readthedocs.io,绿色箭头描述数据流的概览。

下面的官网最新版本(2.0.1)文档中的结构图,它更详细一些:

Spiders
Spider是用户编写用于分析response并提取item或额外跟进URL的类。每个spider负责处理一个特定(或一些)网站。上面的ExampleSpider就是一个spider。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
Downloader middlewares
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider middlewares
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
更多内容参考架构概览。
Selector和xpath
Scrapy的Selector类用来对http文本进行解析,使用时先通过XPath或CSS选择器选中页面中需要提取的数据,然后进行提取。
当Selector对象的css方法时,在内部会先翻译成XPath表达式,然后调用Selector对象的xpath方法,所以我没去了解CSS选择器。
parse函数的response就是一个Selector对象。其他场景中我们需要对xml进行解析时,也可以使用scrapy.selector.Selector类。
关于XPpath简要说明几点:
nodename 选取此节点的所有子节点
/ 从根节点选取
//book 选取所有book子元素,而不管它们在文档中的位置
@ 选取属性
//@lang 选取名为lang的所有属性
text() 获取当前节点的内容
contains(str1,str2) 判断str1中是否包含str2
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
下面是带有谓语的一些路径表达式,以及表达式的结果:
/bookstore/book[1] 选取属于bookstore子元素的第一个book元素
/bookstore/book[last()-1] 选取属于bookstore子元素的倒数第二个book元素
/bookstore/book[position() < 3 ] 选取最前面的两个属于bookstore元素的子元素的book元素
//title[@lang] 选取所有拥有名为lang的属性的title元素
//title[@lang=‘eng’] 选取所有拥有值为eng的lang属性的title元素
更多内容参考Python Scrapy使用Selector、xpath、css选择器提取数据。
scrapy shell
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据,免去了每次修改后运行spider的麻烦。
Scrapy终端其实是一个普通的Python终端,但提供了一些额外的快捷方式。
启动终端:scrapy shell或scrapy shell <url>,后者会爬取url,并比前者多提供request、response等一些变量。
2meinv
尝试爬取爱美女上的图片。
它的文章url很有规律,都是https://www.2meinv.com/article-325.html这种,一个页面中只有一张图片,“下一页”,“上一篇”,“下一篇”这些按钮的也很有规律。所以,以这样的方式去爬取:从首篇文章开始,一直爬取“下一页”,到达最后一页后,再爬取“上一篇”,如此往复。
然后是图片如何下载的问题,是直接在爬取过程中下载,还是先爬到图片的url,再另行下载。尝试了下前者,但比较麻烦也出现了一些问题,于是采用后者。
详细流程:
$ scrapy startproject beauty
$ cd beauty
$ scrapy genspider meinv www.2meinv.com
$ cd beauty
# settings.py
ROBOTSTXT_OBEY = False
# items.py
class BeautyItem(scrapy.Item):
id = scrapy.Field()
baseurl = scrapy.Field()
topic = scrapy.Field()
tags = scrapy.Field()
intro = scrapy.Field()
num = scrapy.Field()
images = scrapy.Field()
pass
# spiders/meinv.py
# -*- coding: utf-8 -*-
import scrapy
import re
from beauty.items import BeautyItem
class MeinvSpider(scrapy.Spider):
name = 'meinv'
allowed_domains = ['2meinv.com']
start_urls = ['https://www.2meinv.com/article-3.html']
images = {}
endid = '9999'
def parse(self, response):
curnum = response.xpath("//h1/span").re("[0-9]+")[0]
maxnum = response.xpath("//h1/span").re("[0-9]+")[1]
if curnum == '1':
# 初始化
self.baseurl = response.url
self.id = re.match('.*-([0-9]+)\.html',response.url).group(1)
self.topic = response.xpath("//h1/text()").extract()[0]
self.tags = ','.join(response.xpath("/html/body/div[2]/div/div/span/a/text()").extract())
self.intro = ''.join([str(i) for i in response.xpath("/html/body/div[2]/div/p/text()").extract()[1:]])
self.images['No'+curnum] = response.xpath("//div[@class='pp hh']/a/img/@src").extract()[0]
if curnum != maxnum:
# 读取下一页
post_list = response.xpath("//div[@class='page-show']/a[contains(text(),'下一页')]/@href").extract()
yield scrapy.Request(post_list[0], callback=self.parse)
else:
# 本篇完成 读取上一篇
item = BeautyItem(id=self.id,baseurl=self.baseurl,topic=self.topic,\
tags=self.tags,intro=self.intro,num=maxnum,images=self.images)
yield item
pre_list = response.xpath("//div[@class='page-show']/a[contains(text(),'上一篇')]/@href").extract()
if len(pre_list) == 0:
return
else:
nexturl = pre_list[0]
nextid = re.match('.*-([0-9]+)\.html',nexturl).group(1)
if nextid == self.endid:
return
else:
self.images = {}
yield scrapy.Request(nexturl, callback=self.parse)
pass
pass
pass
pass
$ scrapy crawl meinv -o output.xml
图片
最终得到的是很多这种格式“https://i.yfi8.com:5262/a1503/2018img/2018-03-16/1521193191PEuh.jpg”的图片链接,但直接访问它得到一个“图片不见了”的默认图片,猜测是图床有防盗链的功能。
HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
用curl测试一下,curl --referer https://www.2meinv.com/ https://i.yfi8.com:5262/a1503/2018img/2018-03-16/1521193191PEuh.jpg -o test.jpg,OK了,接下来就是批量下载xml文件中的图片。
用xml.dom.minidom来解析xml文件,minidom是Simple implementation of the Level 1 DOM,基本能覆盖掉日常的xml操作。
下载图片用requests库,它是一个Python第三方库,处理URL资源特别方便,pip install requests即可安装。
源码如下:
# -*- coding: utf-8 -*-
import os
import sys
import time
import random
import requests
import xml.dom.minidom
from pathlib import Path
if len(sys.argv) == 1:
print('usage:', sys.argv[0], 'startid')
sys.exit(1)
start = int(sys.argv[1])
count = 100
xmlfile ='2000.xml'
def nowtime():
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
def download(url, headers):
for x in range(5):
try:
r = requests.get(url=url, headers=headers, timeout=x*8+4)
if r.status_code == 200:
return r
else:
time.sleep(3)
continue
except requests.exceptions.ConnectionError as e:
print(e)
time.sleep(3)
continue
except requests.exceptions.ConnectTimeout as e:
print(e)
time.sleep(3)
continue
except requests.exceptions.ReadTimeout as e:
print(e)
time.sleep(3)
continue
except requests.exceptions.RequestException as e:
print(type(e))
print(e)
break
domtree = xml.dom.minidom.parse(xmlfile)
root = domtree.documentElement
items = root.getElementsByTagName('item')
for item in items:
id = item.getElementsByTagName('id')[0].childNodes[0].data
if int(id) < start:
continue
topic = item.getElementsByTagName('topic')[0].childNodes[0].data
baseurl = item.getElementsByTagName('baseurl')[0].childNodes[0].data
num = item.getElementsByTagName('num')[0].childNodes[0].data
print(nowtime(), 'statistics: begin', id, topic, num, 'P')
images = item.getElementsByTagName('images')[0]
time1 = time.time()
# 创建目录
if not os.path.exists(id):
os.mkdir(id)
success = True
for image in images.childNodes:
imageurl = image.childNodes[0].data
filename = id + '/' + image.nodeName[2:] + '.jpg'
file = Path(filename)
if not file.is_file():
print('-------------getting', filename)
# 立即关闭连接,否则或许连接池会用光
r = download(imageurl, {'referer' : baseurl, 'Connection': 'close'})
if not r:
print(nowtime(), 'error: when downloading', filename)
success = False
sys.exit(2)
break
else:
with open(filename, 'wb') as f:
f.write(r.content)
time.sleep(random.randint(200,2000)/1000)
pass
# 重命名目录
if success == True:
os.rename(id, id + '-' + topic + '【' + num + 'P】')
time2 = time.time()
print(nowtime(), 'statistics: end', id, 'using', int(time2-time1+0.5), 'secondes')
count = count - 1
if count <= 0:
break
pass
selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。这个工具主要是用来自动化测试的,但也可用于强反爬虫的网站或爬取由js动态生成的页面。
通过md5查找重复图片
一个额外的小工具,查找当前目录下md5相同的jpg:
# -*- coding: utf-8 -*-
import os
import shutil,hashlib
dict = {}
list = os.listdir('.')
for i in range(0, len(list)):
if ".jpg" in list[i]:
md5str = hashlib.md5(open(list[i],'rb').read()).hexdigest()
if dict.get(md5str, 'x') == 'x':
dict[md5str] = list[i]
else:
shutil.move(list[i], os.path.join('..', list[i]))
参考
Scrapy 1.0 文档
【Python】requests 详解超时和重试
Python Requests中异常总结
python爬虫 requests异常
发现一个爬虫项目,可以搭建一个属于你自己的图片站,可以自动爬取美女图片并发布,项目地址:https://coding.net/u/zxy_coding/p/94imm/git,搜索94imm可找到安装教程。















 9676
9676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}