







简介
和描述性统计分析相比,均值过程可以按指定条件分组计算均值和标准差等统计量,还可以执行单因素方差分析和相关分析
菜单
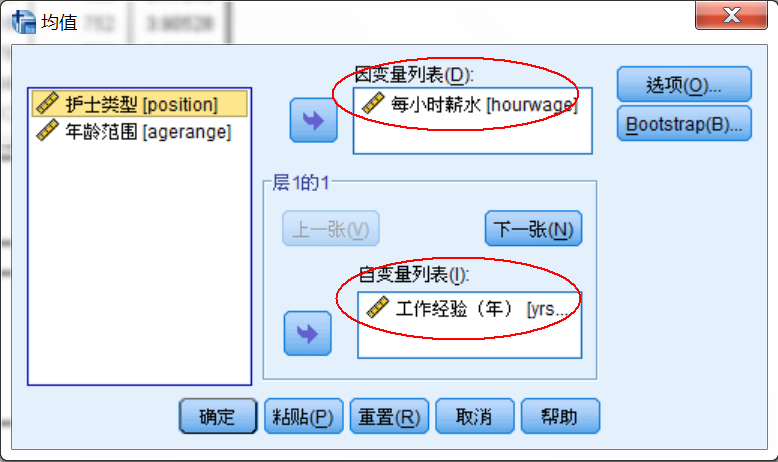
参数设置
数据源:hourlywagedata.sav
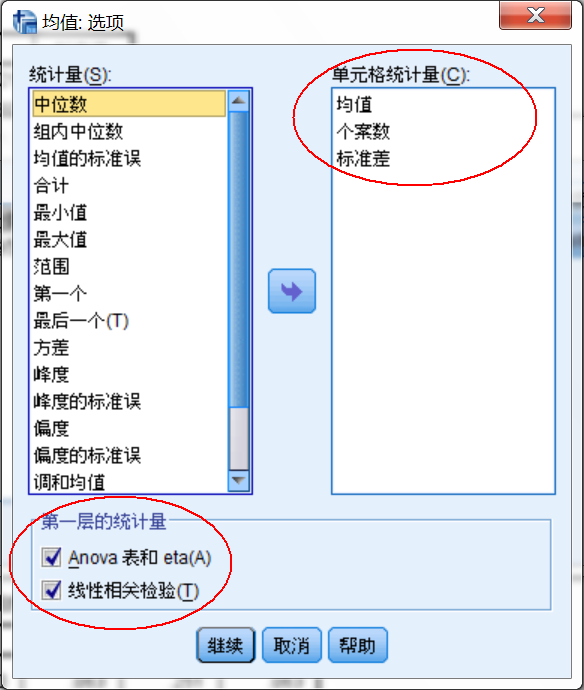
统计量
最大值 (Maximum). 数值变量的最大值。
平均值 (Mean). 集中趋势的测量。算术平均,总和除以个案个数。
中位数 (Median). 第 50 个百分位,大于该值和小于该值的个案数各占一半。如果个案个数为偶数,那么中位数是个案在以升序或降序排列的情况下最中间的两个个案的平均。中位数是集中趋势的测量,但对于远离中心的值不敏感(这与平均值不同,平均值容易受到少数多个非常大或非常小的值的影响)。
最小值 (Minimum). 数值变量的最小值。
N . 个案(观察值或记录)的数目。
合计 N % (Percent of total N). 每个类别中的个案总数的百分比。
总和的百分比 (Percent of total sum). 每个类别中的总和百分比。
范围 (Range). 数值变量最大值和最小值之间的差;最大值减去最小值。
偏度 (Skewness). 分布的不对称性测量。正态分布是对称的,偏度值为 0。具有显著的正偏度的分布有很长的右尾。具有显著的负偏度的分布有很长的左尾。作为一个指导,当偏度值超过标准误差的两倍时,那么认为不具有对称性。
标准差 (Standard Deviation). 对围绕平均值的离差的测量。在正态分布中,68% 的个案在平均值的一倍标准差范围内,95% 的个案在平均值的两倍标准差范围内。例如,在正态分布中,如果平均年龄为 45,标准差为 10,那么 95% 的个案将处于 25 到 65 之间。
峰度标准误差 (Standard Error of Kurtosis). 峰度与其标准误差的比可用作正态性检验(即,如果比值小于 -2 或大于 +2,就可以拒绝正态性)。大的正峰度值表示分布的尾部比正态分布的尾部要长一些;负峰度值表示比较短的尾部(变为像框状的均匀分布尾部)。
平均值的标准误差 (Standard Error of Mean). 取自同一分布的样本与样本之间的平均值之差的测量。它可以用来粗略地将观察到的平均值与假设值进行比较(即,如果差与标准误差的比值小于 -2 或大于 +2,那么可以断定两个值不同)。
偏度标准误差 (Standard Error of Skewness). 偏度与其标准误差的比可用作正态性检验(即,如果比值小于 -2 或大于 +2,就可以拒绝正态性)。大的正偏度值表示长右尾;极负值表示长左尾。
总和 (Sum). 所有带有非缺失值的个案的值的合计或总计。
方差 (Variance). 对围绕平均值的离差的测量,值等于与平均值的差的平方和除以个案数减一。度量方差的单位是变量本身的单位的平方。
结果分析
均值
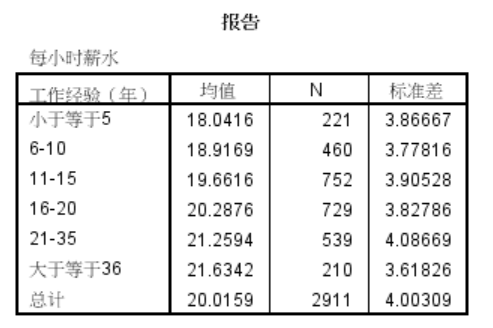
从均值可以看出:工作经验越长,时薪越高
方差分析
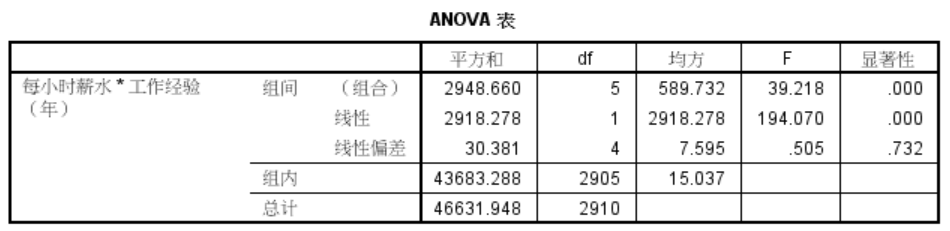
- 第一列:组间的、组内的、总的方差
- 第二列:平方和
- 第三列:自由度
- 第四列:均方
- 第五列:F统计量值
- 第六列:F统计量显著水平
具体含义:请参考单因素方差分析
组间显著性 sig=0.00 < 0.05,说明不同的工作经验,小时薪水有显著差异
线性相关分析

- R是因变量身高的观测值与预测值之间的的相 关系数,R值越接近1 表明回归方程的预测性越好,即相关性越大
- Eta统计量表明因变量和自变量之间相关的强度;即η值(0~1)说明因变量(时薪)与自变量(工作经验)之间的联系程度,越接近1 ,关系越密切
- Eta Squared:η2为组间偏差平方和与偏差平方和总和之比
具体含义:请参考相关分析
R=0.25,说明时薪和工作经验有一定关联,随着工作经验的增加时薪也会增加

















 7955
7955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









