







Trust Region Based Adversarial Attack on Neural Networks
摘要
背景介绍
现有攻击的弱点:
调整超参数非常耗时;基于对抗攻击求解优化需要很多轮迭代
文章亮点
我们提出了一种新的基于信任区域的对抗攻击,旨在有效地计算对抗扰动。
我们提出了几种基于信任区域优化方法的攻击方法。
贡献
比CW可以产生更快的扰动,能快速降低准确度。
一、 Introduction
-
DNN不够鲁棒,提出了三个改进的方向
-
对抗攻击方法:白盒攻击、黑盒攻击
白盒攻击:
需要关于目标网络的信息,当我们尝试通过信息进行攻击,比如网络架构、我们传入图片的梯度、参数等等,所以我们知道关于目标模型非常完整的信息。
黑盒攻击 则不需要这些网络的信息
-
本文目的主要找到一个更有效的攻击方法,理想状况:需要更强的攻击和更小的扰动幅度,这样它可能无法检测。
-
信赖域方法TR
在优化范围中的当前点周围定义一个区域作为信赖域,其中使用一个(二次)模型近似来寻找下降/上升方向。
一阶TR方法:使用梯度信息。
好处:计算有效性,容易实现
-
作者提出自适应的TR方法
基于模型近似自适应地选择TR半径,以进一步加快攻击过程。最后,我们提出了如何将基本TR方法推广到二阶TR方法的公式,这对于具有显著非线性决策边界的情况很有用 -
主要贡献
① 作者提出一个基于信赖域优化方法的白盒有目标攻击,这个方法可以自适应地选择每个扰动幅度,迭代消除了昂贵的超参数训练,这是Carlini-Wagner信赖域的弱点之一。
② 信赖域也可以产生更快的扰动,比CW快了37.5倍,而且相比于Deepfool,幅度也比较小,
③ 也容易扩展到二阶信赖域攻击,这对非线性激活函数很有用。 -
这个方法的限制
二阶需要计算海森矩阵,开销大
二、Background
- 对这种扰动的解析计算没有封闭形式的解。现有的方法通过求解辅助优化或解析近似来解决扰动。
- 然而,神经网络的决策边界并不是线性的。甚至在softmax层之前,景观也是分段线性的,但这不能用一个简单的仿射变换来近似。因此,如果我们使用局部信息,我们可能会高估/低估欺骗网络所需的对抗性扰动。
- CW attack
问题:
min原始图和扰动图的距离
s.t 扰动图被NN误分类
这是一种直接解决∆x扰动的更复杂的方法。
缺点:调节超参数
-
另一个方向:对抗训练被当成防御方法,对抗对抗攻击。
这种对抗训练进一步扩展到集成对抗训练,目的是使模型对黑盒攻击的鲁棒性。 -
还提出了其他方法来检测/防御对抗性攻击。
但是,使用更强的攻击方法,可以打破蒸馏或模糊梯度等防御方案 -
对抗性攻击的最后一个重要应用是训练神经网络获得改进的泛化,即使在非对抗性环境中也是如此。
三、Trust Region Adversarial Attack
① 分析问题
DNN在softmax函数之前的输出:
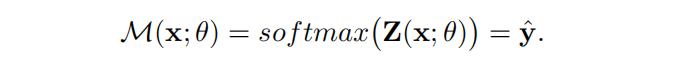
一个对抗性的攻击试图找到欺骗DNN的∆x:
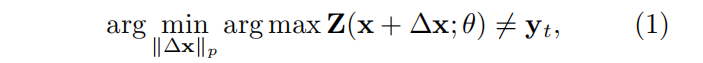
问题:
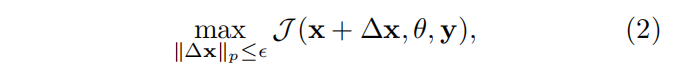
② 限制
可以通过用线性仿射变换逼近决策边界来解决这个问题。
但是对于神经网络来说,这种近似可能非常不准确,因为它可能导致对沿次优方向的扰动的高估/低估。最小的方向将与决策边界正交,因为决策边界是非线性的,所以这不能通过一个简单的仿射变换来计算。
③ TR算法

主要思想:迭代地选择信赖半径,以找到该区域内的对抗性扰动,使错误类的概率最大。
信赖域优化
信赖域方法是一类迭代的非线性优化算法,通常基于信赖域,在当前点周围进行二次模型来近似。首先先找到一个信赖域大小,基于这个信赖域和这里面的近似模型,我们将找到一个step direction,所以我们要在这找到一个最小值。
信赖域子问题
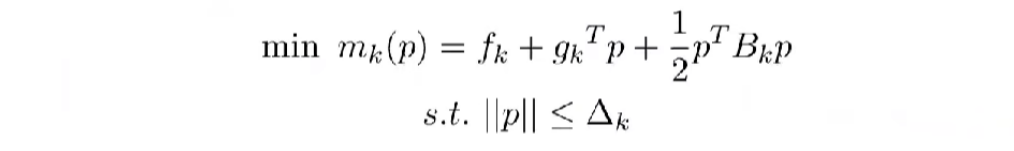
每个信赖域本身就是一个子问题,所以这个方程就是信赖域本身的二次近似,我们将在这个信赖域内找到这种近似值的最小值。
更新信赖域
这种信赖域方法的特殊之处在于 ,我们可以选择让他更大更小或者不变,如果我们不信任该模型,我们就把信赖域变大,模型为我们提供了良好的预测或者近似。因此要确定是否变大变小还是不变,我们在这里计算这个比率,然后根据这个比率,确定是否变大变小或者不变。
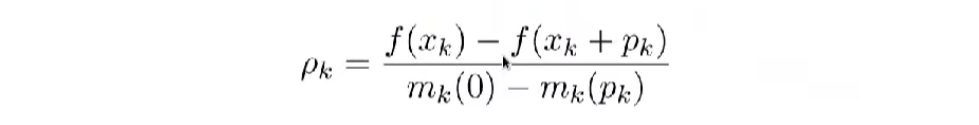
所以在这种情况下,我们定义两个阈值ρk、pk,这两个阈值代表这些点将决定是否变化信赖域大小。
提出的方法
使用TR找到对抗扰动:
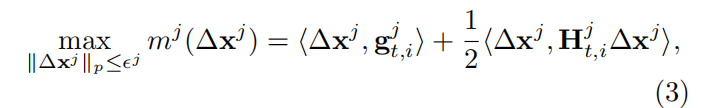
他们使用的近似值是这个函数,他涉及一阶,这里一阶有一个梯度和一个带有海森矩阵的二阶,所以问题是,如果我们使用常规的激活函数,这些海森矩阵很多地方都是0。我们可以简单的将它放在等式上,然后我们只需要第一个包含这一项,但是我们不适用这种激活函数,我们使用非线性激活函数,然后我们应该把这个海森矩阵保留在这里,计算这部分也是很贵的。所以将要展示的实验,主要是讨论一阶优化。
四、Performance of the method
① 评价指标
我们现在讨论实验结果,作者评估他们的指标包括2部分:时间,和扰动的大小。
1.所以为了评估时间,他们只是简单计算找到一个对抗图像所花费的秒数,
2.为了测量扰动,使用的是这个公式,
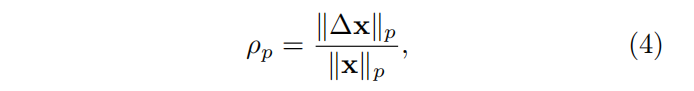
ΔX 是将模型分类精确度降低到0.1%时,为样本添加的perturbation(扰动)大小。这个比值越小,表示对一个样本的扰动幅度越小,他们使用的是相对扰动,所以他们会将得到的噪声的范数,除以图像的范数。这里使用了两个范数,L2,L无穷大-norm。
② 使用的攻击类型
这是untargeted attack。
对于best class attack,他们会选择最接近当前点的类别,所以他们将这个最好的类称为最好的类标签,所以这个表达式给出的最好的类在这里zt。
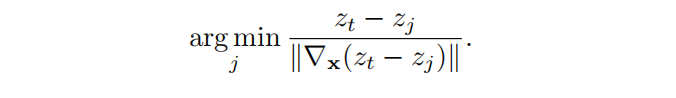
对于hardest class attack,他们将该类作为决定离当前点最远的部分。
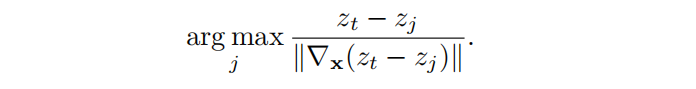
③ 实验设置Setup

这个是他们实验设置的快速总结。
在两个数据集上进行攻击实验,使用在背景中讨论的大多数方法,他们也尝试了对于信赖域攻击的方法,但是修复了信赖域的大小,称为TR Non-Adapt。
然后对于将要攻击的网络,AlexLike就是一个简单的CNN,这里就只是作为一个标准。AlexLike-S使用的是swiss激活,这是一个非线性激活函数。
④ 在时间上的表现
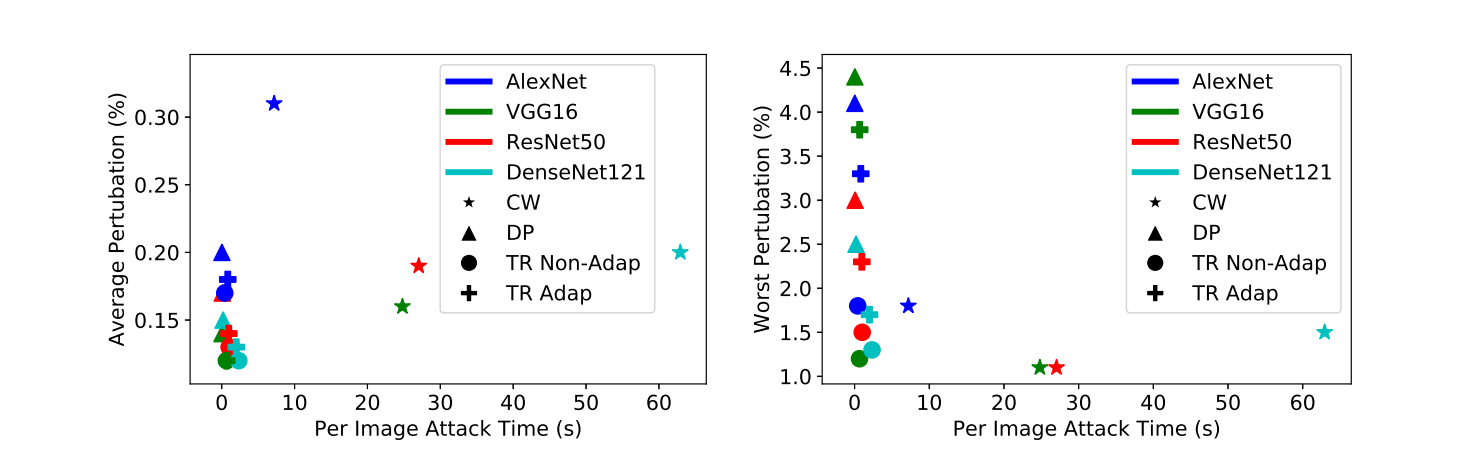
这是一些结果,所以这个图显示的是信赖域方法和TR Adapt产生类似于CW的扰动,实际上甚至更小的扰动,但是时间显著减少。
先看第一个图,这是平均扰动,所以这是他们找到扰动所需要的时间,所以这个星星标注的CW大部分都很高,就是他们所说的,它的速度要快得多。
再看看deep fool的表现,大部分都在圆圈和加号上方,说明这个方法会产生较小的扰动,产生的速度也很快,
然后这里第二个图主要是最坏的扰动,和第一个图也是类似的
⑤ CIFAR-10
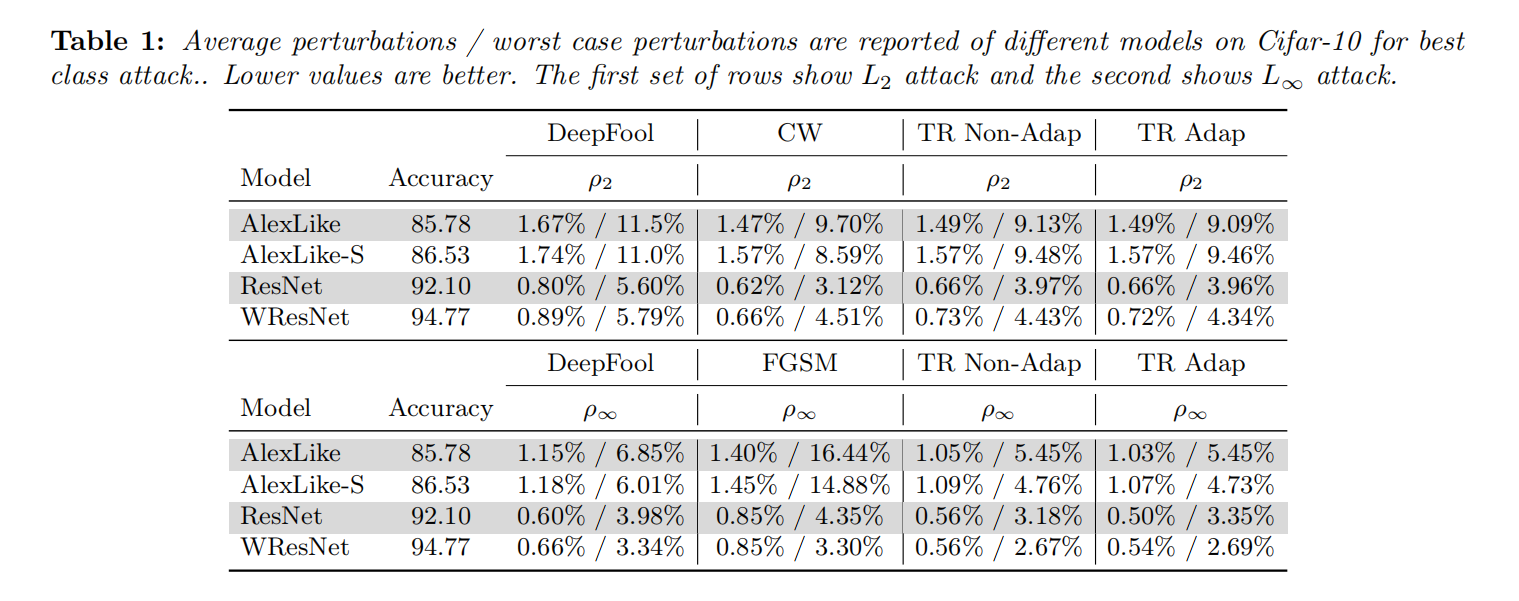
这个是他们对扰动的结果,所以对于所有这些表格和模型,选择的扰动是的目标模型的精度降低到低于0.1%。一般来说,对于TR的方法,他们产生的扰动比Deepfool小,但是与CW比较,他们是比较接近的,但并不是所有的都更小,有一些是比他们更大的扰动 。比如ResNet。这个表格是best class attack,所以这是对当前图像最接近的分类,所以这是更容易的情况。
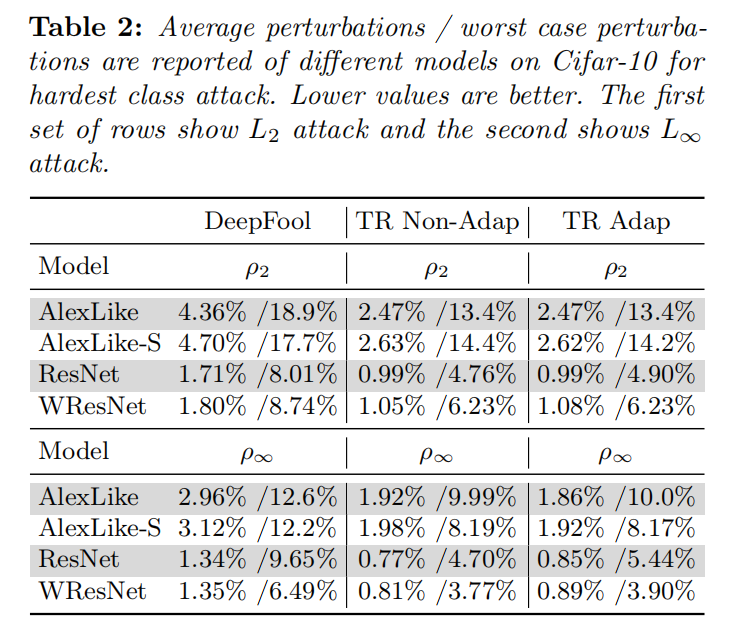
他们也进行了the hardest class attack,这些是结果,也和上一个分析差不多。 通常与deepfool相比,有更小的扰动。
⑥ ImageNet Result
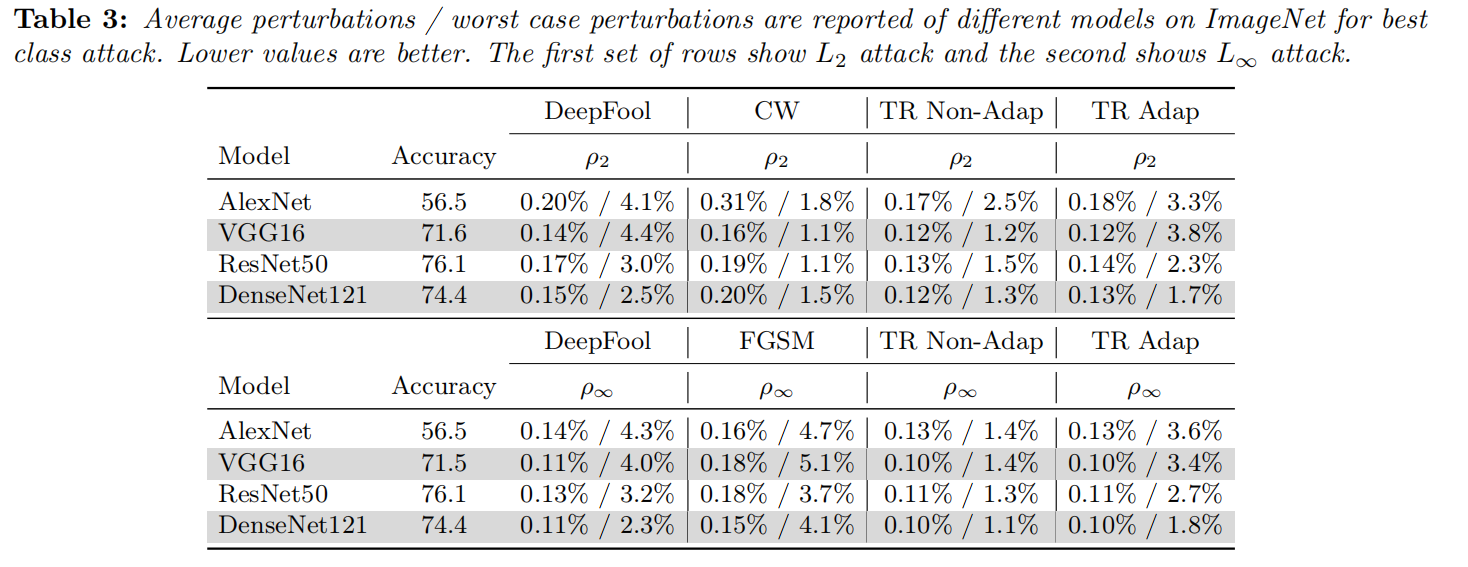
这是对于ImageNet、best class attack的过程,实际上对于这里L2范数,与这里的CW相比,信赖域有更小的扰动。都与之前的差不多。
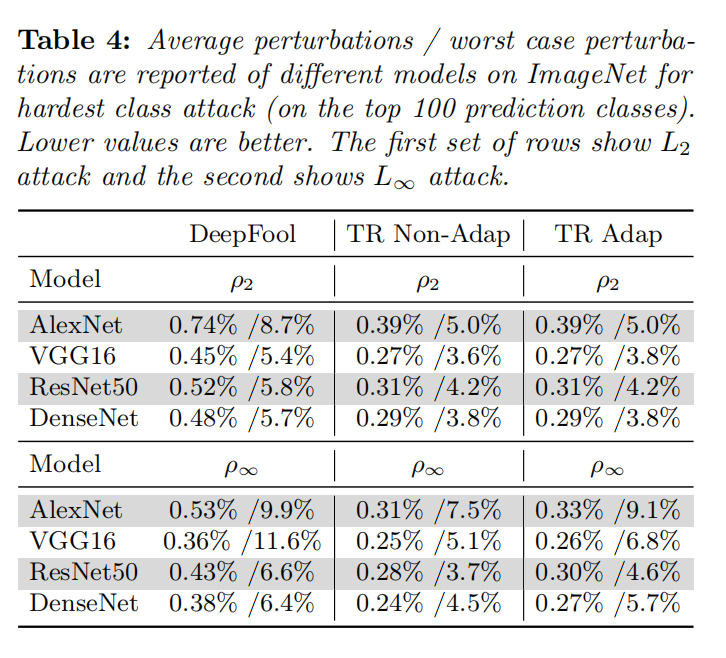
这是对于hardest class attack,分析也是类似的。
⑦ Second order method
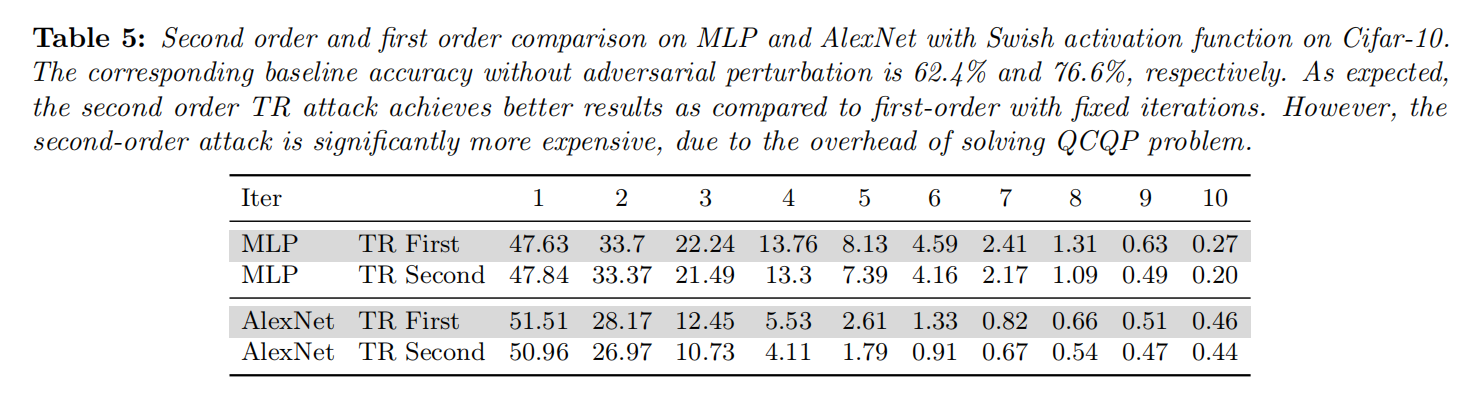
作者也使用了二阶攻击进行实验,所以他们在这里所做的是对于这些模型的多层感知器和alexnet,使用swiss激活函数,看这个迭代次数,最多迭代三次,二阶攻击将进一步降低目标模型的准确性,因此甚至大概高达1%多一点,比如alexnet在第三次迭代地时候。随着迭代次数的增加,他们最终使模型接近0,低于1%。这些攻击都是针对cifar的。
五、Conclusion
- 作者基于信赖域方法,提出了白盒目标攻击,成为TR攻击。
- 他们的方法可以非常快速地产生较小的对抗扰动。
- 可以在每次迭代中选择扰动的步长, 他们很容易扩展到二阶攻击。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









