







① Segnet: A deep convolutional encoder-decoder architecture for image segmentation
② Learning Deconvolution Network for Semantic Segmentation
SegNet以DeconvNet为基础,DeconvNet写法更经典
文章目录
SegNet论文结构
摘要: 介绍论文的背景、核心观点、方法途径、最终成果
1. Introduction: 相关内容概述,本文内容简述
2. Literature Review: 详细描述其他文章的发展历程
3. Architecture: 介绍网络结构
4. Benchmarking: 基准测试,详细展示实验结果
5. Discussion and future work
6. Conclusion
7. References
一、摘要核心
① SegNet
介绍算法结构: 提出了SegNet网络,其核心的训练引擎包含一个encoder网络,和一个对称的decoder网络,并跟随一个用于pixel-wise的分类层。介绍网络构成分别有什么用。
文章的亮点: decoder进行上采样的方式,直接利用与之对应的encoder阶段中,在经过最大池化时保留的pooling index进行非线性上采样
好处:在上采样阶段不用进行学习了
问题:得到图片信息很稀疏
比较结果: 通过比较SegNet与FCN、DeepLab-LargeFOV、DeconvNet结构,统筹内存与准确率,SegNet实现了良好的分割效果
模型评估: 在 Camvid 和 SUN RGB-D indoor 数据集中都进行了评估
② DeconvNet
算法结构: 提出了深度反卷积网络,编码部分使用VGG16的卷积层进行学习,解码器部分使用反卷积与反池化进行上采样
文章亮点: 由反卷积和反池化层组成上采样,逐像素分类完成预测
特殊方法:
基于FCN方法的问题:对于太大的物体,如果感受野没那么大的话,可能会造成分割错误;对于太小的物体,感受野比较大,看到的背景信息比较多,可能造成分割错误。
所以使用edge box框起来,人为干预后把object proposal(edge box)送入训练后的网络。整幅图像是这些proposal分割结果的组合,这样就可以解决物体太大或者太小所带来的分割问题,改进了现存的基于FCN的方法。
模型评估: 算法能识别图像中的精细结构以及不同尺度大小的目标,在PASCAL VOC 2012数据集中去的72.5%的准确率
二、先验知识
① 编码器-解码器结构
编码器:
由普通卷积层和下采样层(池化)将特征图尺寸缩小,使其成为更低维的特征。
目的是尽可能的提取低级特征和高级特征,(局部特征和全局特征)
从而利用提取道德空间信息和全局信息精确分割。
解码器:
由普通卷积、上采样层和融合层组成。用来扩大特征图尺寸的,利用上采样操作逐步恢复空间维度,融合编码过程中提取到的特征,在尽可能减少信息损失的前提下完成同尺寸输入输出。
② Dropout 随机丢弃层
在每个训练批次中,通过忽略一般的特征检测器(让一半的隐层节点值为0),可以明显减少过拟合现象,减少特征检测器(隐层节点)间的相互作用。
③ Unpool 反池化 (一种上采样方式)
上采样方式:基于插值、反卷积、反池化
反池化用的不多
编码器中的每一个最大池化层的索引都存储了起来,用于之后在解码器中使用索引来对相应特征图进行池化操作。
有助于保持高频信息的完整性
对低分辨率的特征图进行反池化时,会忽略临近的信息
优点:
- 只存储索引,可以省空间,需要的内存很少,减少参数,提高效率。
- 对轮廓信息的保留比较好。

三、引言及相关工作
(1)引言

第一段:CNN的应用方向
第二段:CNN用于语义分割(FCN)
第三段:基于FCN的分割网络存在很多问题
- 感受野的不可变性会造成分割或者错误的标注
- 反卷积层输入的特征图,通过多次下采样后分辨率太低,精度太粗糙,细节会被丢失
本文主要贡献:
突破了反卷积
(2)相关工作
SegNet
- 介绍前FCN时代的深度学习分割方法
- 介绍FCN:
FCN架构中的每个解码器都对其输入的特征图进行上采样,并将其与相应的编码器特征图组合,以产生下一个解码器的输入。
该网络的整体大小使其难以在相关任务上进行端到端地进行训练(即原始的FCN32s效果很差)。因此作者使用了阶段性的训练过程,解码器网络中的每个解码器逐步添加到预训练好的网络中
网络生长直到没有进一步的性能提高,这种增长在三个解码器之后停止(FCN8s) - FCN弊端
忽略了高分辨率的特征图,会导致边缘信息的丢失
FCN编码器网络中有大量参数(134M),但解码器网络非常的小(0.5M)
DeconvNet
-
介绍CNN
-
一些传统分割方法
-
介绍FCN,一个想法:将插值滤波(双线性插值)作为反卷积的初始化,只有网络中的CNN进行微调,从而间接的学习反卷积。
-
弱监督(不太常用)
-
反卷积&反池化
都放在解码器中进行上采样
也被用来CNN可视化,可以直观的理解CNN的具体工作内容,经过每一步特征图进行的变化
四、算法架构
① SegNet
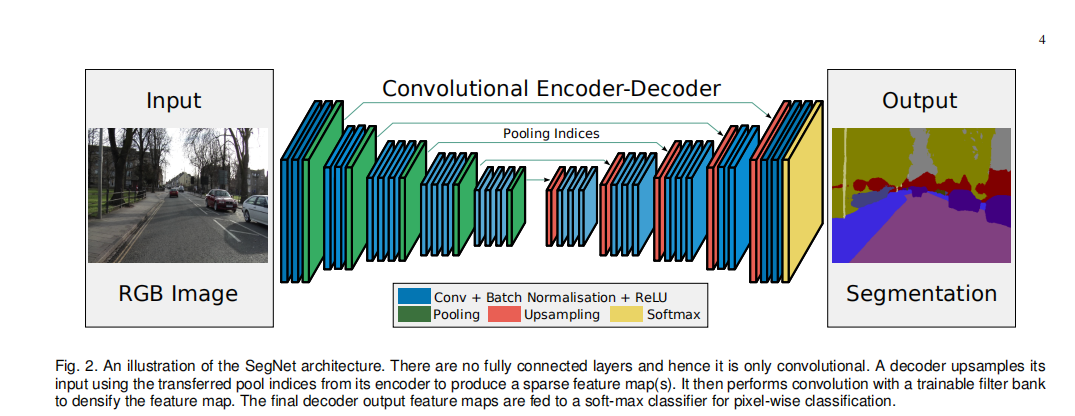
卷积卷积池化×5 编码块,pooling对索引做一个记录,在对应的上采样区域中做一个映射,
把存储的索引的值放到固定位置上,扩大尺寸,更多的保留固定信息,反池化+3个卷积块,最后两个是两个卷积块,softmax分类出结果。
编码器和解码器是完全对称的。
② DeconvNet
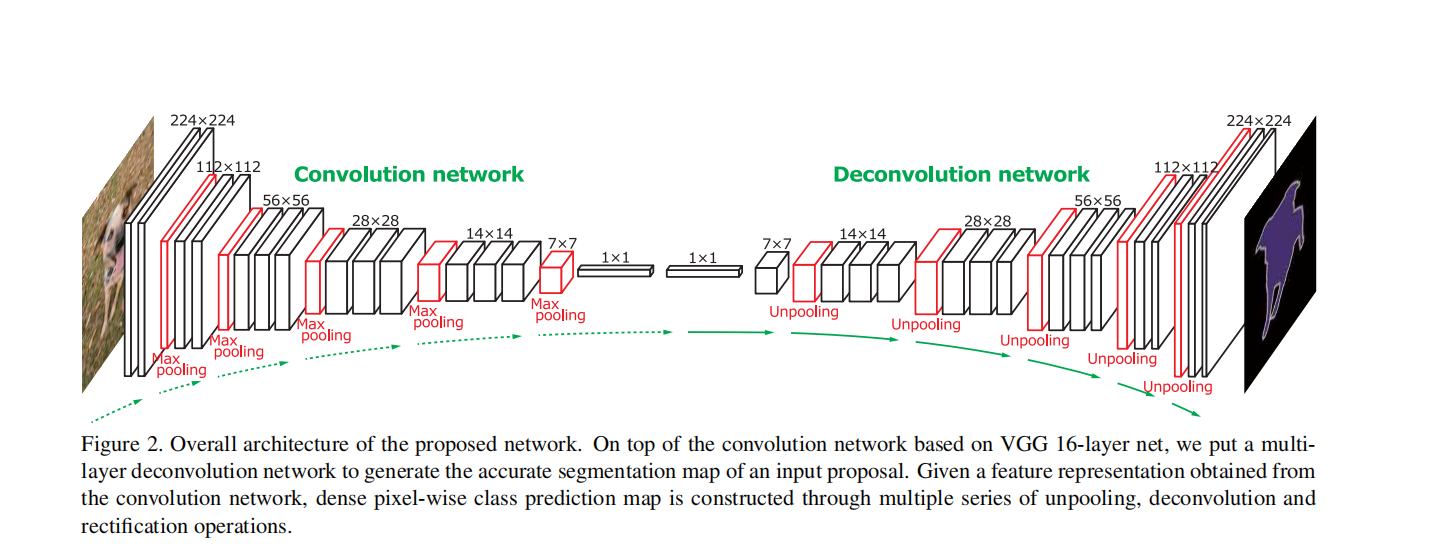
卷积卷积池化 下采样块,中间加了两个全连接,会引入大量的参数,二维的分割用一维的向量意义不大,不用提取特征。
pooling用的反池化+反卷积
创新点:
反卷积比卷积能生成更密集的预测图,因为通过反池化扩大特征图,特征图是很稀疏的,必须通过卷积层变成更加密集的映射。反卷积生成预测图的能力比卷积更强,所以池化之后接的反卷积,而不是卷积。
③ SegNet论文3.1中的Architecture
第一段: 介绍编码器和解码器各自的构成,
编码器和解码器严格堆成的。编码器使用的VGG16的前13个卷积层,伴有在ImageNet上的预训练;对应的解码器网络也一共有13层,第一层是反池化,后面都是卷积层。
第二段: 编码器的构成、max pooling和存储索引的作用
存储索引没有存储整个特征图准确率高,但是效率提升了一大截。仍然可以用于实际应用。
第三段: 分割的常识性知识
通过反池化进行上采样的特征图比较稀疏,SegNet通过卷积的方式变得更密集一点,分辨率变得高一点,之后进行上采样扩大倍数的时候,不至于准确度丧失的太厉害。DeconvNet用的反卷积,设置了一下参数,不至于让特征图扩大2倍。反卷积让特征图变密集的程度比卷积更强。
第四段: 与DeconvNet开始对比
DeconvNet使用了两个全连接,参数量大,先用小的数据集进行预训练,需要更多的计算资源,难以进行端到端的训练。
第五段: 跟U-Net比
U-Net没有重复使用池化索引,将整个特征图传到相应的解码器。以更多的内存为代价。网络比较浅。用到了预训练,收敛速度更快。
五、SegNet 算法模型细节
① SegNet解码器变体
选择FCN作为比较对象
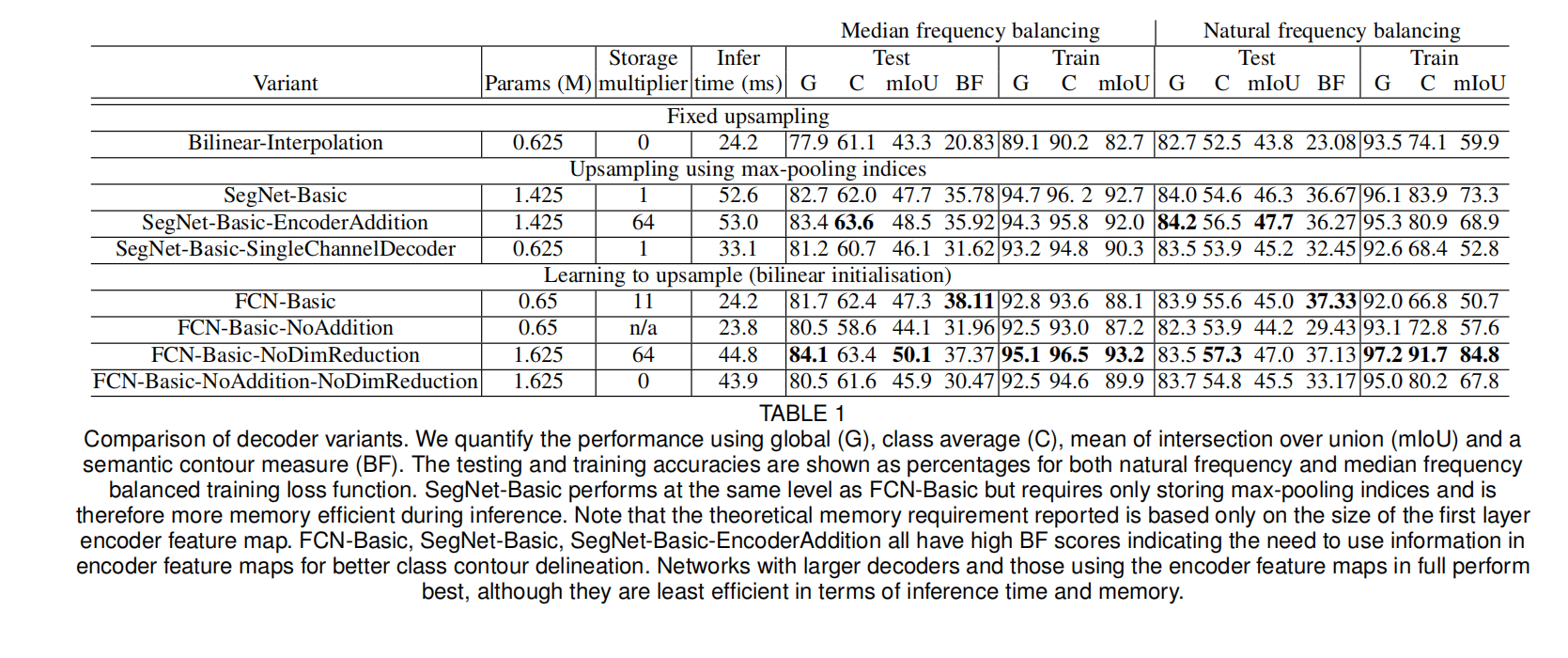
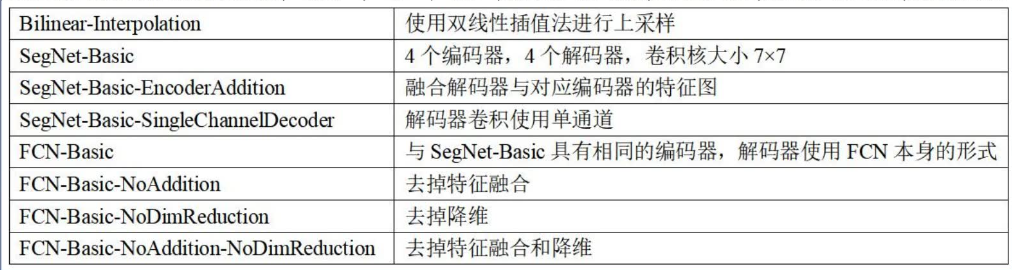
变体1:SegNet-Basic

它具有4个编码器和4个解码器,
SegNet-Basic也是使用最大池化的,也使用反池化来进行上采样,还把最大池化这个索引进行进行了一个保留,所以说它在解码器当中的一个主要思想是没怎么变的。然后有BN层。
解码器的变化:它使用了这个反池化。但是没有用到偏置和ReLU激活。
卷积核大小变化:它变成了7×7这样的一个大卷积核。为了保证这个感受野比较大106×106,保证4层网络的感受野和5层的差不多。。虽然vgg证明了几个小卷积核罗列在一起的性能是要比大卷积核要好的,但是也没有那么绝对。
变体2:FCN-Basic

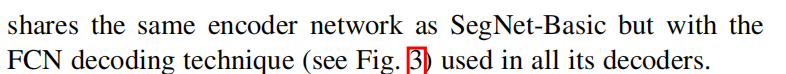
与SegNet-Basic共享相同的编码器网络,都使用VGG16的前几个编码器块。
但是所有解码器中还是使用的FCN原来的版本。
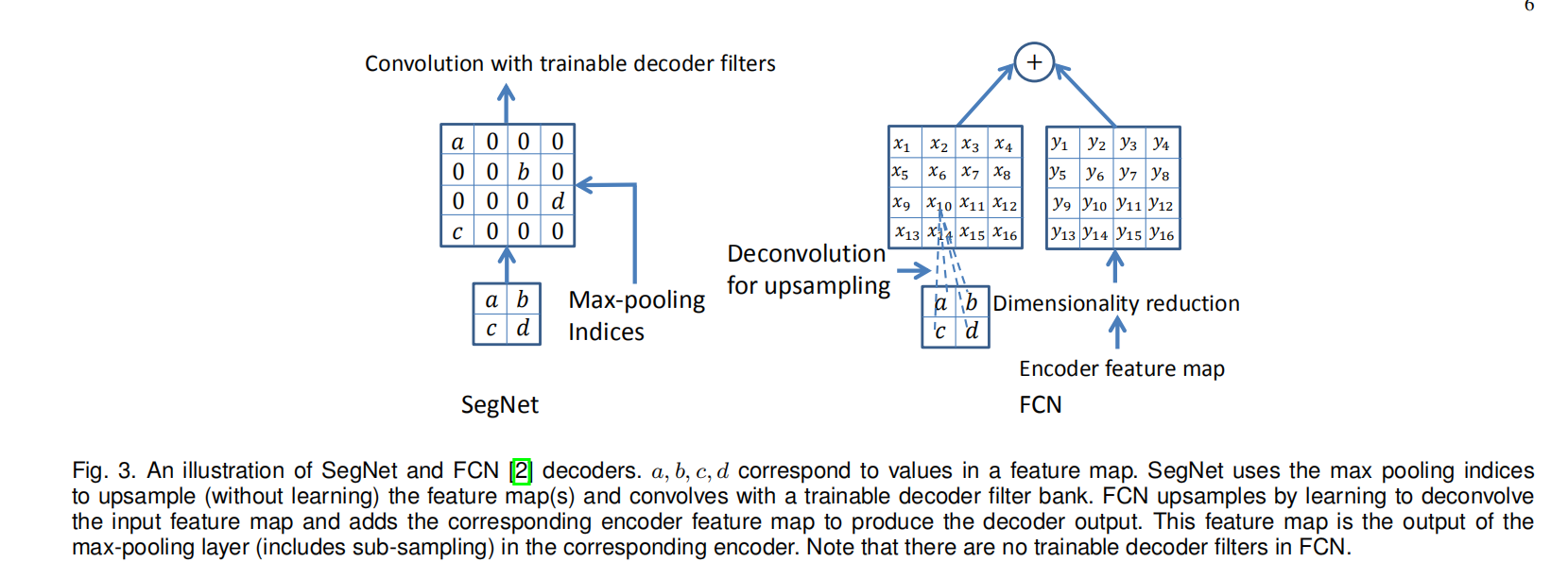
变体3:SegNet-Basic-SingleChannelDecoder
把解码器的卷积变成单通道。减少了训练的参数和推理时间。
变体4:FCN-Basic-NoAddition
没有特征融合,只单纯的进行上采样。可以减少存储的参数量
变体5:Bilinear-Interpolation
把上采样的方式反池化替换成双线性插值。那么这样的上采样是不需要学习的。
变体6:SegNet-Basic-EncoderAddition
另一方面,在SegNet解码器的每一层添加64个编码器当中的特征图,也就是。他在SegNet当中做了特征融合。相当于借鉴了FC的一个思想。看看稍微增加一点内存量做一个特征融合,是不是会得到更好的结果。
那么这个地方使用的上采样呢就还原了,还是max pooling index,也就是反池化的这样一个操作。那么随后还是紧跟着卷积来使稀疏的特征图变得更加密集了。
然后这些特征融合。也就是说之前解码器这些基本基本思想我是不变的。只不过就是把编码器的特征图拿过来放到解码器当中融合一下子,看一下结果就好了。
所以这块有两个变体,一个是替换上采样的方式,一个是让SegNet做特征融合。
变体7:FCN-Basic-NoDimReduction
没有降维。
FCN把64通道或者更多的通道数都降为成了分类数。让FCN变胖一点那他的这个结果会不会更好呢。
因为FCN本身是有特征融合。所以不改变通道数的特征融合,会不会比压缩之后的特征融合更好。
另一种和更多的这个这个需要耗费内存的方式(FCN-Basic),取消了对编码器特征的一个降维。那么这个就意味着它和FCN-Basic是不一样。因为在啊最终把编码器特征图送到解码器网络之前,它是不会进行K倍的一个压缩的。所以说每个解码器结尾处的通道数量与原始的相对应的编码器数量是相同的。
那按照FCN-Basic也就是原来的这样一个思想。我应该是把这个256先变成11。11+11。还是11的这样一个操作去做的,但是我现在把这个降维取消了。这块是256,然后我直接甩到后面去相加。他加到的结果还是256。所以他的这个相加之后的特征图的通道数还是跟对编码器位置的特征通道是一样的。
② 3.2训练参数设置

③ 3.3分析

④ 4基准测试
道路场景分割:CamVid数据集
SUN RGB-D室内场景数据集
六、DeconvNet 算法细节
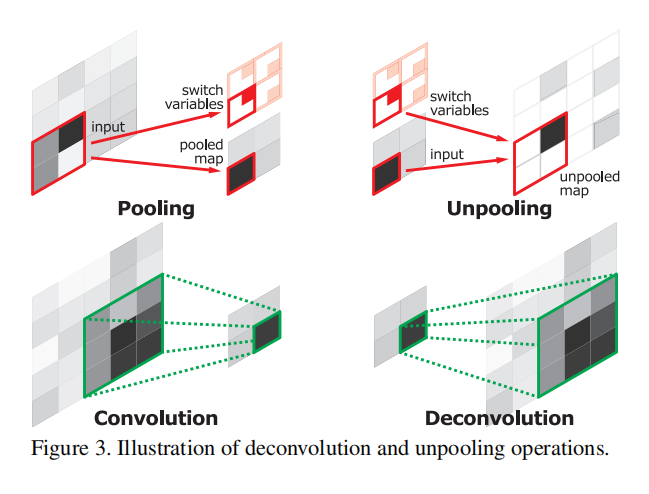
① 反池化
有利于重构输入对象的结构,因为记录了索引
② 反卷积
输出扩大了,像素变得更加密集了,能得到更多的更密集的预测图。通过裁剪,使输入输出的特征图大小是一致的。
针对某一个特定类的高层的信息提取,比卷积做的好。
③ 训练
Batch Normalization
Two-stage Training
七、总结两篇论文的关键点&创新点
① SegNet
- 核心的训练引擎包括一个 encoder 网络和一个对称的 decoder 网络,将编码解码结构普适化
- 选择反池化作为上采样方式。decoder 中直接利用与之对应的 encoder 阶段中最大池化时保留的 pooling index 来反池化
- 实验分析非常充分饱满
② DeconvNet
- 反池化+反卷积构成解码器,编码器使用vgg16卷积层
2. 论文写法逻辑经典
③ DeconvNet 与 SegNet 的不同之处主要在于
- 反池化与反卷积结合来形成 decoder
- encoder 和 decoder 之间加入了全连接
八、 研究成果及意义
- 在内存(参数)和准确率之间找到了很好的平衡点
- 将编码解码结构普适化
- 在多个场景数据集中均取得了很好的结果














 5758
5758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









