







NNDL 实验五 前馈神经网络(3)鸢尾花分类
深入研究鸢尾花数据集
画出数据集中150个数据的前两个特征的散点分布图(顺便复习一下上学期的SVM):
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两维特征
y = iris.target
h = .02 # 网格中的步长
C = 1.0 # SVM正则化参数
svc = svm.SVC(kernel='linear', C=C).fit(X, y) # 线性核
rbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C).fit(X, y) # 径向基核
poly_svc = svm.SVC(kernel='poly', degree=3, C=C).fit(X, y) # 多项式核
lin_svc = svm.LinearSVC(C=C).fit(X, y) # 线性核
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
titles = ['SVC with linear kernel',
'LinearSVC (linear kernel)',
'SVC with RBF kernel',
'SVC with polynomial (degree 3) kernel']
for i, clf in enumerate((svc, lin_svc, rbf_svc, poly_svc)):
# 绘出决策边界,不同的区域分配不同的颜色
plt.subplot(2, 2, i + 1) # 创建一个2行2列的图,并以第i个图为当前图
plt.subplots_adjust(wspace=0.4, hspace=0.4) # 设置子图间隔
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) # 将xx和yy中的元素组成一对对坐标,作为支持向量机的输入,返回一个array
# 把分类结果绘制出来
Z = Z.reshape(xx.shape) # (220, 280)
plt.contourf(xx, yy, Z)
# 将训练数据以离散点的形式绘制出来
plt.scatter(X[:, 0], X[:, 1], c=y, cmap="brg")
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.title(titles[i])
plt.show()
运行结果:

4.5 实践:基于前馈神经网络完成鸢尾花分类
继续使用第三章中的鸢尾花分类任务,将Softmax分类器替换为前馈神经网络。
- 损失函数:交叉熵损失;
- 优化器:随机梯度下降法;
- 评价指标:准确率。
4.5.1 小批量梯度下降法
为了减少每次迭代的计算复杂度,我们可以在每次迭代时只采集一小部分样本,计算在这组样本上损失函数的梯度并更新参数,这种优化方式称为小批量梯度下降法(Mini-Batch Gradient Descent,Mini-Batch GD)。
为了小批量梯度下降法,我们需要对数据进行随机分组。
目前,机器学习中通常做法是构建一个数据迭代器,每个迭代过程中从全部数据集中获取一批指定数量的数据。
注:多扯一点关于小批量梯度下降法的内容:
梯度下降法有着三种不同的形式,分别是批量梯度下降、随机梯度下降和小批量梯度下降。
批量梯度下降:批量梯度下降法是最原始的形式。每一次迭代更新权值时,都使用所有样本来计算偏导数。采用这种方法由所有样本确定梯度方向,可以保证每一步都是准确地向着极值点的方向趋近,收敛的速度最快,所需要的迭代次数最少,当目标函数是凸函数时,一定能够收敛于全局最小值,如果目标函数是非凸函数,则会收敛到某个局部极小值点。(对所有样本的计算,可以利用向量运算进行并行计算来提升运算速度)
对于小规模数据集,通常采用这种批量梯度下降法进行训练,在前面的实验使用的都是这种方法,但是在神经网络和深度学习中,样本的数量往往非常大,每个样本中,属性的个数也可能非常的大,采用批量梯度下降法,在每一步迭代时,都需要用到所有的样本,计算量会非常大,即使使用向量运算,也需要花费大量的时间。
并且在大规模数据集中,通常会有大量冗余数据,也没有必要使用整个训练集来计算梯度,因此,批量梯度下降法并不适合大规模数据集。为了实现更快的计算,可以使用随机梯度下降法。
随机梯度下降法:在这种方法中,每次迭代时只使用一个样本来训练模型,也就是说每次只使用一个样本去计算代价函数的梯度并迭代更新模型的参数,使模型的输出值尽可能逼近这个样本真实的标签值。
当训练误差足够小时,结束本次训练,再输入下一个新的样本,显然使用前面样本训练出的网络参数,不一定能够使得后面的新样本误差最小,所以这个新样本需要再重新训练网络,这个样本训练结束之后,再输入下一个样本,再次训练网络,直到使用所有样本训练一遍为止,这个过程也被称为一轮。
采用随机梯度下降法,虽然每次训练只使用一个样本,单次迭代的速度很快,但是通过单个样本计算出的梯度不能够很好的体现全体样本的梯度。各个样本各自为政,横冲直撞,不同样本的训练结果,往往会互相抵消,导致参数更新非常的频繁,因此,可能会走很多的弯路,在最优点附近晃来晃去,却无法快速收敛,即使损失函数是凸函数,也无法做到线性收敛,而且采用这种方法,每次只使用一个样本,也不利于实现并行计算。
实际上这种方法很少使用,现在我们所说的随机梯度下降通常是指小批量梯度下降算法。
小批量梯度下降法:小批量梯度下降算法是前面两种的折中方案,也称为小批量随机梯度下降算法。这种算法把梯度称为若干个小批量,也叫做小批量。也就是每次迭代只使用其中一个小批量来训练模型。
在小批量梯度下降法中,每个批中的所有样本共同决定了本次迭代中梯度的方向,这样训练起来就不会跑偏,也就减少了随机性。
将所有的批次都执行一遍,就称之为一轮。因为各个批的样本之间也会存在训练结果互相抵消的问题,因此通常也需要经过多轮训练才能够收敛。
使用这种方法的好处是,无论整个训练集的样本数量有多少,每次迭代所使用的训练样本数量都是固定的。和批量梯度下降法相比,这样显然可以大大的加快训练速度,另外,和批量梯度下降法一样,这种方法也可以实现并行计算。因此。在训练大规模数据集时,通常首选小批量梯度下降算法。
4.5.2 数据处理
4.5.2. 1自定义加载数据集
import copy
import numpy as np
import torch
from sklearn.datasets import load_iris
#加载数据集
def load_data(shuffle=True):
#加载原始数据
X = np.array(load_iris().data, dtype=np.float32)
y = np.array(load_iris().target, dtype=np.int64)
X = torch.as_tensor(X)
y = torch.as_tensor(y)
#数据归一化
X_min = torch.min(X, dim=0)
X_max = torch.max(X, dim=0)
X = (X-X_min.values) / (X_max.values-X_min.values)
#如果shuffle为True,随机打乱数据
if shuffle:
idx = torch.randperm(X.shape[0])
X_new = copy.deepcopy(X)
y_new = copy.deepcopy(y)
for i in range(X.shape[0]):
X_new[i] = X[idx[i]]
y_new[i] = y[idx[i]]
X = X_new
y = y_new
return X, y
class IrisDataset(torch.utils.data.Dataset):
def __init__(self, mode='train', num_train=120, num_dev=15):
super(IrisDataset, self).__init__()
# 调用第三章中的数据读取函数,其中不需要将标签转成one-hot类型
X, y = load_data(shuffle=True)
if mode == 'train':
self.X, self.y = X[:num_train], y[:num_train]
elif mode == 'dev':
self.X, self.y = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
else:
self.X, self.y = X[num_train + num_dev:], y[num_train + num_dev:]
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
def __len__(self):
return len(self.y)
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')
4.5.2.2 用DataLoader进行封装
# 批量大小
batch_size = 16
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = torch.utils.data.DataLoader(dev_dataset, batch_size=batch_size)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
4.5.3 模型构建
# 实现一个两层前馈神经网络
class Model_MLP_L2_V3(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model_MLP_L2_V3, self).__init__()
self.fc1 = torch.nn.Linear(input_size, hidden_size)
w_ = torch.normal(0, 0.01, size=(hidden_size, input_size), requires_grad=True)
self.fc1.weight = torch.nn.Parameter(w_)
self.fc1.bias = torch.nn.init.constant_(self.fc1.bias, val=1.0)
self.fc2 = torch.nn.Linear(hidden_size, output_size )
w2 = torch.normal(0, 0.01, size=(output_size, hidden_size), requires_grad=True)
self.fc2.weight = nn.Parameter(w2)
self.fc2.bias = torch.nn.init.constant_(self.fc2.bias, val=1.0)
self.act = torch.sigmoid
def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs)
return outputs
ffnn_model =Model_MLP_L2_V3(input_size=4, hidden_size=6,output_size=3)
4.5.4 完善Runner类
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X)
loss = self.loss_fn(logits, y) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X)
# 计算损失函数
loss = self.loss_fn(logits, y).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x)
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
model_state_dict = torch.load(model_path)
self.model.load_state_dict(model_state_dict)
注:Accuracy类如下
class Accuracy(object):
def __init__(self, is_logist=True):
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, axis=-1)
if self.is_logist:
# logist判断是否大于0
preds = (outputs>=0).to(torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = (outputs>=0.5).to(torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).int()
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, axis=-1)
batch_correct = torch.sum(torch.tensor(preds==labels, dtype=torch.float32)).numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
4.5.5 模型训练
使用训练集和验证集进行模型训练,共训练150个epoch。在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.optim as opt
lr = 0.2
# 定义网络
model = fnn_model
# 定义优化器
optimizer = opt.SGD(model.parameters(),lr=lr)
# 定义损失函数。softmax+交叉熵
loss_fn = F.cross_entropy
# 定义评价指标
metric = Accuracy(is_logist=True)
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 100
eval_steps = 50
runner.train(train_loader, dev_loader,
num_epochs=150, log_steps=log_steps, eval_steps = eval_steps,
save_path="best_model.pdparams")
运行结果:
 可视化
可视化
import matplotlib.pyplot as plt
# 绘制训练集和验证集的损失变化以及验证集上的准确率变化曲线
def plot_training_loss_acc(runner, fig_name,
fig_size=(16, 6),
sample_step=20,
loss_legend_loc="upper right",
acc_legend_loc="lower right",
train_color="#e4007f",
dev_color='#f19ec2',
fontsize='large',
train_linestyle="-",
dev_linestyle='--'):
plt.figure(figsize=fig_size)
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::sample_step]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color=train_color, linestyle=train_linestyle, label="Train loss")
if len(runner.dev_losses) > 0:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color=dev_color, linestyle=dev_linestyle, label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize=fontsize)
plt.xlabel("step", fontsize=fontsize)
plt.legend(loc=loss_legend_loc, fontsize='x-large')
# 绘制评价准确率变化曲线
if len(runner.dev_scores) > 0:
plt.subplot(1, 2, 2)
plt.plot(dev_steps, runner.dev_scores,
color=dev_color, linestyle=dev_linestyle, label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize=fontsize)
plt.xlabel("step", fontsize=fontsize)
plt.legend(loc=acc_legend_loc, fontsize='x-large')
plt.savefig(fig_name)
plt.show()
plot_training_loss_acc(runner, 'fw-loss.pdf')
运行结果:
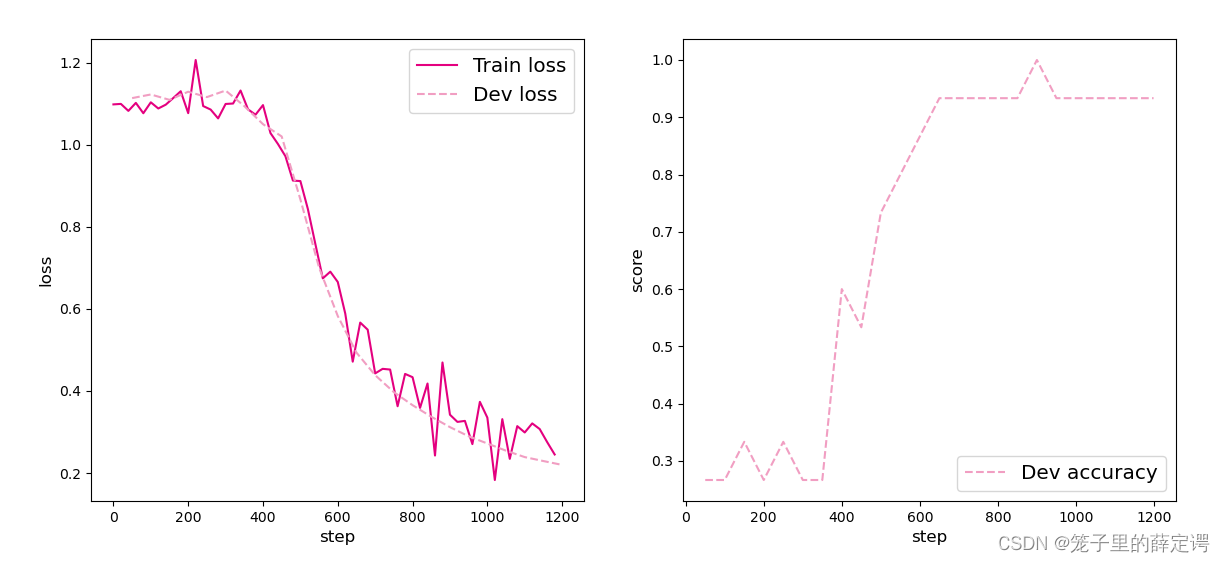 从输出结果可以看出准确率随着迭代次数增加逐渐上升直至收敛,损失函数则不断下降。
从输出结果可以看出准确率随着迭代次数增加逐渐上升直至收敛,损失函数则不断下降。
4.5.6 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果:

4.5.7 模型预测
# 获取测试集中第一条数据
X, label = train_dataset[0]
logits = runner.predict(X)
pred_class = torch.argmax(logits[0]).numpy()
label = label.numpy()
# 输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
运行结果:

思考题
对比Softmax分类和前馈神经网络分类
(自己从网上选了一些随机点,我将之称为进阶的弯月数据集):
N = 100 #每类有100个样本点
D = 2 #两个特征维度
K = 3 #三类
X = np.zeros((N * K, D))
y = np.zeros(N * K, dtype='uint8')
for j in range(K):
ix = range(N * j, N * (j + 1))
r = np.linspace(0.0, 1, N) # radius
t = np.linspace(j * 4, (j + 1) * 4, N) + np.random.randn(N) * 0.2 # theta
X[ix] = np.c_[r * np.sin(t), r * np.cos(t)]
y[ix] = j
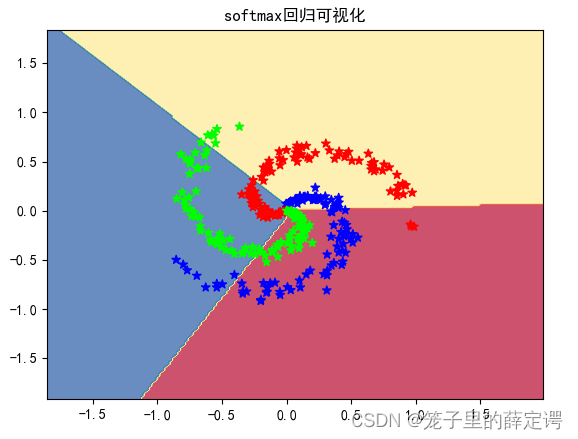
 输出结果为51%,很垃圾的一个准确率,追根溯源是因为softmax回归是一个线性分类器。而选定数据是进阶的弯月数据集,用一个线性分类器去分割显然是不合适的,这一点从可视化也可以看出来。
输出结果为51%,很垃圾的一个准确率,追根溯源是因为softmax回归是一个线性分类器。而选定数据是进阶的弯月数据集,用一个线性分类器去分割显然是不合适的,这一点从可视化也可以看出来。
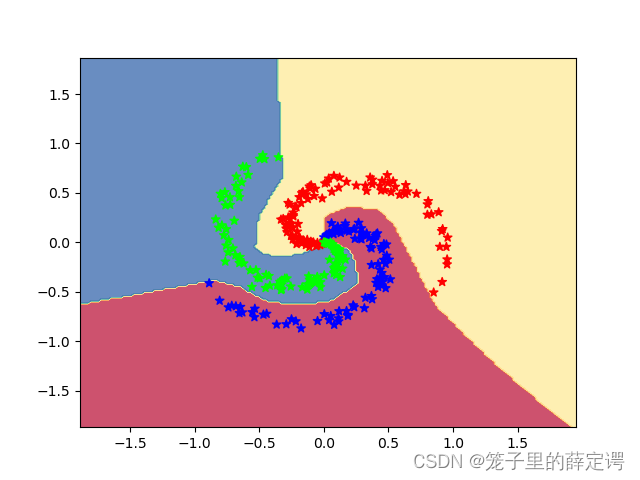
 准确率高达97%,说明用前馈神经网络可以很完美的拟合想要的效果,这一点从可视化也可以看出来。
准确率高达97%,说明用前馈神经网络可以很完美的拟合想要的效果,这一点从可视化也可以看出来。
自定义隐藏层层数和每个隐藏层中的神经元个数,尝试找到最优超参数完成多分类(lr=0.2,epochs=150)
一层隐藏层,6个隐藏层神经元

一层隐藏层,3个隐藏层神经元

一层隐藏层,10个隐藏层神经元


调参很多次以后,我发现别说调参了,这同一组超参数结果都很不相同(一开始在1层隐藏层,6个隐藏层神经元时我就发现闪过去了一个1,但是绝大多数都是0.933,就没在意,到进行第三组横向时,发现波动很大,所以也没再进行)。
查了很多博客,觉得解释的好的原因:
1.首先是初始化的时候,给权重矩阵 W(以及b )的初始值不一样。
2.如果我们固定初始值,结果仍有可能不一样,原因在于大部分算法训练时使用的是mini-batch SGD,也就是每次更新数据是基于一个batch里的样本。这时,许多算法会在每轮遍历时shuffle一遍数据集,那么得到的每个batch的数据也会不一样,这会导致学到的参数有细微不同。
3.进一步的,如果我们固定好每个batch的样本(或者使用批梯度下降,即每次都把全量训练集作为一个batch),那么训练出来的模型仍有可能有差异。这可能是收敛条件的判定不同,有的算法会固定epoch数,有的则会使用early-stop。
4.以上的讨论都是基于通用的神经网络模型进行的,即所有神经网络会具有的特性如此。此外,还有一些trick也可能会导致同一超参训练出的模型准确率不同,例如:使用随机的dropout。
结合到本题,我觉得主要是因为模型在保存的过程中保存的是性能最好的模型参数,出现一次便被保存下来(但是不清楚以前为啥没出现)。而我觉得上面解释都是关于准确率差别小的内容,并不是关于准确率差别大的内容,但也很有收获。
注:解释的不是很清楚,等同班佬的调参出来了,我再对比改一下。
对比SVM与FNN分类效果,谈谈自己看法
这两个都有现成得图,直接复制过来上面的图,如下:
- SVM=Support Vector Machine 是支持向量 机
- SVC=Support Vector Classification就是支持向量机用于分类,
- SVR=Support Vector Regression.就是支持向量机用于回归分析
因为本题是解释分类效果,所以使用的SVC。
SVC效果图
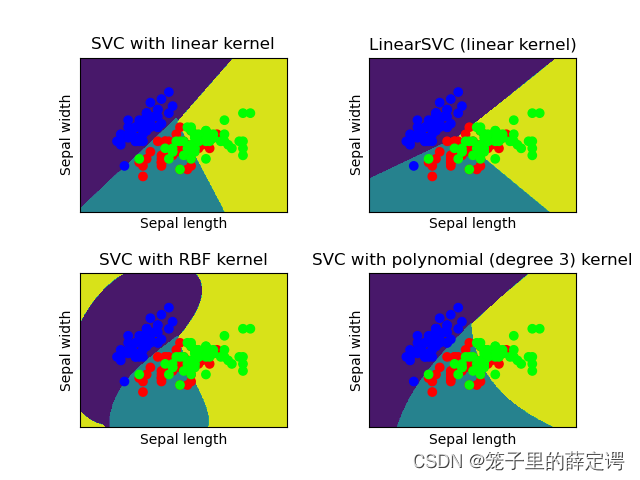
前馈神经网络效果图:

从上面可以看出,对于多类并且数据分布为曲线形状时,二者都能很好的拟合,下面通过这两学期的学习说说我个人的看法(仅代表个人观点):
个人觉得SVM要比神经网络的逻辑更严密一些,上学期跟着机器学习老师以及浙大胡浩基老师手推过好几遍SVM,同时这两个学期也手推了很多遍BP神经网络,但还是觉得SVM数学逻辑更严谨或者更优美一些,SVM直接根据数据分布来拟合分类边界,更关注数据的分布,出来的结果和心理预期相差不大;神经网络更像是把数据放进炉子里,更关注的是参数的调优以及优化器、激活函数的选择,出来的结果也很不可把控,沾点玄学。
对于特征维度少、数据量小的数据集SVM非常适用,对于特征维度多、数据量大的数据集神经网络适用(从数学建模的角度出发也是这样,数据量的多少影响选择机器学习算法或者是智能算法)。
尝试基于MNIST手写数字识别数据集,设计合适的前馈神经网络进行实验,并取得95%以上的准确率
代码实现:
import torch
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
import torchvision.datasets as dataset
import torchvision.transforms as transforms
batch_size = 100
# 加载数据集
train_dataset = dataset.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = dataset.MNIST(root='./data', train=False, transform=transforms.ToTensor(), download=True)
# 封装数据集
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
# 初始化超参数
input_size = 784
hidden_size = 500
num_classes = 10 # 类别数目
# 定义神经网络模型
class module(nn.Module):
def __init__(self, input_size, hidden_size, output_num):
super(module, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_num)
# 前向传播
def forward(self, x):
out = self.fc1(x)
out = torch.relu(out)
out = self.fc2(out)
return out
module = module(input_size, hidden_size, num_classes)
# 超参数初始化
lr = 1e-1
epochs = 5
# 定义损失函数及优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(module.parameters(), lr=lr)
# 模型开始训练
for epoch in range(epochs + 1):
print("==============第 {} 轮 训练开始==============".format(epoch + 1))
for i, (images, labels) in enumerate(train_loader):
images = Variable(images.view(-1, 28 * 28))
labels = Variable(labels)
outputs = module(images)
# 计算损失
loss = criterion(outputs, labels)
# 梯度清0
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step() # update parameters
#
if i % 100 == 0:
print("交叉熵损失为: %.5f" % loss.item())
# 利用训练好的模型进行预测
T = 0 # 总共测试集样本个数
CC = 0 # 测试集正确识别的个数
for images, labels in test_loader:
images = Variable(images.view(-1, 28 * 28))
labels = Variable(labels)
outputs = module(images)
_, predicts = torch.max(outputs.data, 1)
T += labels.size(0)
CC += (predicts == labels).sum()
print("识别准确率为:%.2f %%" % (100 * CC / T))
运行结果:

总结
1.做了这么多次前馈神经网络的实验,发现网络的搭建是有套路的:
- 加载、封装数据集
- 搭建网络结构(定义全连接层、卷积层、池化层以及激活函数)
- 前向传播(对输入根据定义的网络结构进行处理,要清楚每一层都干了什么、输入是什么样子的、处理后输出是什么样子的)
- 定义合适的优化器及损失函数(这里重点就是参数的调优(貌似现在好多模型都使用Adam优化器)以及清楚不同损失函数、优化器的区别和适用条件)
- 训练模型(计算损失、梯度清0、反向传播、参数更新)
- 模型评价(要清楚不同模型的评价指标,可视化(在本章实验主要就是拟合边界))
体会到的流程大致就是这些,本章大多都是采用类和算子的形式,便于代码的复用(具体类和算子优点见以前博客)
2.本次实验对比了softmax回归和前馈神经网络,这俩区别还是很明显的,softmax是线性分类器,对于螺旋状的数据集显然是不合适的,现实中线性的多分类数据集应该很少,所以这俩对比肯定是神经网络好一点。
3.本次实验复习了一下上学期的SVM,上学期学的SVM也手推了好几遍,所以印象还算深刻,我觉得SVM对这种特征少、数量少的数据集要优于神经网络,但是究竟特征多少个算少、数量多少算少也要结合问题具体分析,而且SVM优于神经网络只是代码跑出来的结果,根据理论和最近做的调参实验可以知道一个合理的超参数组合,神经网络可以拟合出绝大多数的曲线
4.根据做实验的体会和理论课的学习,绘制的思维导图如下:
 我也不清楚这叫不叫思维导图,我是按照代码的顺序来理前馈神经网络,更像是一个流程图。
我也不清楚这叫不叫思维导图,我是按照代码的顺序来理前馈神经网络,更像是一个流程图。
补充:之前学了卷积神经网络后,觉得前馈神经网络很过时,最近读了一些图像修复方向的论文、做了一些复现工作后,体会到了读书是在整理自己的偏见这句话,比如最原始的gan网络就是完全使用前馈神经网络搭配一些好的激活函数、优化器来实现(流程图中的GELU激活函数和BCELoss损失函数也是在读代码复现该论文的过程中发现好用),在cgan鉴别器模型中依然使用了Linear()层,直到dcgan后才完全使用卷积层替代,也就是下一章实验要做的内容。















 7251
7251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









