






特征工程
1.特征工程概述
什么是特征工程?
特征工程指的是最大程度上从原始数据中汲取特征和信息来使得模型和算法达到尽可能好的效果。
特征工程具体内容包括:
- 数据预处理
- 特征选择
- 特征变换与提取
- 特征组合
- 数据降维
特征工程的两个基本面:
- 基于数理和模型的考虑
- 基于业务的考虑(需要了解数据所属业务领域的专业知识)
几个重要观点:
- 在实际的特征工程实践中,这两个基本面都要考虑,尤其是业务层面,直接关乎到模型的表现。
- 在数据维度特别大、特征数量极多的情况下,找到数据中的 magic feature 至关重要。
- 总之,数据和特征决定了机器学习效果的上限,模型和算法只是不断地逼近这个上限而已。
- kaggle、天池等数据科学竞赛比模型吗?比算法吗?通通不是,比的是特征工程。
2.数据预处理
一些前期的数据清洗和预处理工作,是对原始数据的基本整理和重塑,详情参考我的博客
python数据清洗与预处理实战
3.特征选择
特征选择即选择与目标变量相关的自变量进行用于建模,也叫变量筛选。
特征选择基于两个基本面:
- 特征是否发散,即该特征对于模型是否有解释力,如果特征是一成不变的(0方差),这样的特征是无用的。
- 特征是否与目标变量有一定的相关性。这一点要充分基于业务层面去考虑。
特征选择柳叶三刀:
- Filter (飞刀):特征过滤
- Wrapper (弯刀):特征包装
- Embedded (电刀):特征嵌入
除了基于pandas和numpy的手动特征选择外,sklearn也有一套特征选择模块。
过滤法之方差筛选
from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)
第一列值为0的比例超过了80%,在结果中VarianceThreshold剔除这一列
过滤法之卡方检验
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X, y = iris.data, iris.target
X.shape
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
X_new.shape
(150, 2)
通过卡方检验筛选2个最好的特征。
包装法
# 选定一些算法,根据算法在数据上的表现来选择特征集合,一般选用的算法包括随机森林、支持向量机和k近邻等常用算法。
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=25, n_informative=3,n_redundant=2,
n_repeated=0, n_classes=8, n_clusters_per_class=1, random_state=0)
svc = SVC(kernel="linear")
rfecv = RFECV(estimator=svc, step=1, cv=StratifiedKFold(2), scoring='accuracy')
rfecv.fit(X, y)
print("Optimal number of features : %d" % rfecv.n_features_)
plt.figure()
plt.xlabel("Number of features selected")
plt.ylabel("Cross validation score (nb of correct classifications)")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show();

嵌入法之基于惩罚项的特征选择法
from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
print('原始数据特征维度:', X.shape)
lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y)
model = SelectFromModel(lsvc, prefit=True)
X_new = model.transform(X)
print('l1惩罚处理之后的数据维度:', X_new.shape)
原始数据特征维度: (150, 4)
l1惩罚处理之后的数据维度: (150, 3)
嵌入法之基于树模型的特征选择法
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
X, y = iris.data, iris.target
print('原始数据特征维度:', X.shape)
clf = ExtraTreesClassifier()
clf = clf.fit(X, y)
clf.feature_importances_
model = SelectFromModel(clf, prefit=True)
X_new = model.transform(X)
print('l1惩罚处理之后的数据维度:', X_new.shape)
原始数据特征维度: (150, 4)
l1惩罚处理之后的数据维度: (150, 2)
4.特征变换与特征提取
数据特征逐个处理
- 数据标准化:基于列
- 数据区间缩放
- 数据归一化:基于行
- 数值目标变量对数化处理(有必要的情况下)
- 定量特征二值化(有必要的情况下)
- 定性特征哑编码(one-hot)
- 大文本信息提取(效果类似于one-hot)
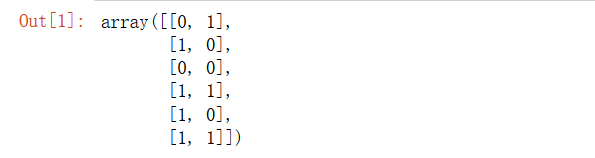
one-hot的两种方法
# sklearn onehotencoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.datasets import load_iris
iris = load_iris()
OneHotEncoder().fit_transform(iris.target.reshape((-1,1))).toarray()
# pandas dummies 方法
import pandas as pd
pd.get_dummies(iris.target)
5.特征组合
在单特征不能取得进一步效果的情况下可尝试不同特征之间的特征组合。
特别需要基于业务考量,而不是随意组合。
6.降维
适用于高维数据,成千上万的特征数量,但一般特征情况下不建议使用。
- PCA
- SVD
- LDA
- t-SNE















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









