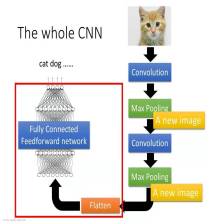
经典CNN网络结构
Le-Net5 网络结构
def inference(input_tensor,train,regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight',[5,5,1,6],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding='VALID')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight',[5,5,6,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding='VALID')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
with tf.variable_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1]*pool_shape[2]*pool_shape[3]
reshaped = tf.reshape(pool2,[-1,nodes])
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight',[nodes,120],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias',[120],initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1,0.5)
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight',[120,84],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias',[84],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2 = tf.nn.relu(tf.matmul(fc1,fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2,0.5)
with tf.variable_scope('layer7-fc3'):
fc3_weights = tf.get_variable('weight',[84,10],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc3_weights))
fc3_biases = tf.get_variable('bias',[10],initializer=tf.truncated_normal_initializer(stddev=0.1))
logit = tf.matmul(fc2,fc3_weights) + fc3_biases
return logit
AlexNet
def inference(images):
"""
构建一个AlexNet模型
"""
parameters = []
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 96], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[96], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
pool1 = tf.nn.max_pool(conv1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool1')
print_activations(pool1)
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 96, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
pool2 = tf.nn.max_pool(conv2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)
return pool5, parameters
Vgg
import tensorflow as tf
import numpy as np
from scipy.misc import imread, imresize
from imagenet_classes import class_names
class vgg16:
def __init__(self, imgs, weights=None, sess=None):
self.imgs = imgs
self.convlayers()
self.fc_layers()
self.probs = tf.nn.softmax(self.fc3l)
if weights is not None and sess is not None:
self.load_weights(weights, sess)
def convlayers(self):
self.parameters = []
with tf.name_scope('preprocess') as scope:
mean = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32, shape=[1, 1, 1, 3], name='img_mean')
images = self.imgs-mean
with tf.name_scope('conv1_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 3, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv1_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv1_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 64], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv1_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv1_2 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
self.pool1 = tf.nn.max_pool(self.conv1_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool1')
with tf.name_scope('conv2_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 64, 128], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv2_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv2_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 128, 128], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv2_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv2_2 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
self.pool2 = tf.nn.max_pool(self.conv2_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool2')
with tf.name_scope('conv3_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 128, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv3_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv3_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv3_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv3_2 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv3_3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv3_2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv3_3 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
self.pool3 = tf.nn.max_pool(self.conv3_3,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool3')
with tf.name_scope('conv4_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.pool3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv4_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv4_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv4_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv4_2 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv4_3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv4_2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv4_3 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
self.pool4 = tf.nn.max_pool(self.conv4_3,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool4')
with tf.name_scope('conv5_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.pool4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv5_1 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv5_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv5_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv5_2 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
with tf.name_scope('conv5_3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(self.conv5_2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases')
out = tf.nn.bias_add(conv, biases)
self.conv5_3 = tf.nn.relu(out, name=scope)
self.parameters += [kernel, biases]
self.pool5 = tf.nn.max_pool(self.conv5_3,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool4')
def fc_layers(self):
with tf.name_scope('fc1') as scope:
shape = int(np.prod(self.pool5.get_shape()[1:]))
fc1w = tf.Variable(tf.truncated_normal([shape, 4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
fc1b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
pool5_flat = tf.reshape(self.pool5, [-1, shape])
fc1l = tf.nn.bias_add(tf.matmul(pool5_flat, fc1w), fc1b)
self.fc1 = tf.nn.relu(fc1l)
self.parameters += [fc1w, fc1b]
with tf.name_scope('fc2') as scope:
fc2w = tf.Variable(tf.truncated_normal([4096, 4096],
dtype=tf.float32,
stddev=1e-1), name='weights')
fc2b = tf.Variable(tf.constant(1.0, shape=[4096], dtype=tf.float32),
trainable=True, name='biases')
fc2l = tf.nn.bias_add(tf.matmul(self.fc1, fc2w), fc2b)
self.fc2 = tf.nn.relu(fc2l)
self.parameters += [fc2w, fc2b]
with tf.name_scope('fc3') as scope:
fc3w = tf.Variable(tf.truncated_normal([4096, 1000],
dtype=tf.float32,
stddev=1e-1), name='weights')
fc3b = tf.Variable(tf.constant(1.0, shape=[1000], dtype=tf.float32),
trainable=True, name='biases')
self.fc3l = tf.nn.bias_add(tf.matmul(self.fc2, fc3w), fc3b)
self.parameters += [fc3w, fc3b]
def load_weights(self, weight_file, sess):
weights = np.load(weight_file)
keys = sorted(weights.keys())
for i, k in enumerate(keys):
print (i, k, np.shape(weights[k]))
sess.run(self.parameters[i].assign(weights[k]))
if __name__ == '__main__':
sess = tf.Session()
imgs = tf.placeholder(tf.float32, [None, 224, 224, 3])
vgg = vgg16(imgs, 'vgg16_weights.npz', sess)
img1 = imread('laska.png', mode='RGB')
img1 = imresize(img1, (224, 224))
prob = sess.run(vgg.probs, feed_dict={vgg.imgs: [img1]})[0]
preds = (np.argsort(prob)[::-1])[0:5]
for p in preds:
print( class_names[p], prob[p])
GoogLeNet
def inception_v3_arg_scope(weight_decay=0.00004,
stddev=0.1,
batch_norm_var_collection='moving_vars'):
batch_norm_params = {
'decay': 0.9997,
'epsilon': 0.001,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'variables_collections': {
'beta': None,
'gamma': None,
'moving_mean': [batch_norm_var_collection],
'moving_variance': [batch_norm_var_collection],
}
}
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay)):
with slim.arg_scope(
[slim.conv2d],
weights_initializer=trunc_normal(stddev),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as sc:
return sc
def inception_v3_base(inputs, scope=None):
'''
Args:
inputs:输入的tensor
scope:包含了函数默认参数的环境
'''
end_points = {}
with tf.variable_scope(scope, 'InceptionV3', [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='VALID'):
net = slim.conv2d(inputs, 32, [3, 3], stride=2, scope='Conv2d_1a_3x3')
'''
因为使用了slim以及slim.arg_scope,我们一行代码就可以定义好一个卷积层
相比AlexNet使用好几行代码定义一个卷积层,或是VGGNet中专门写一个函数定义卷积层,都更加方便
'''
net = slim.conv2d(net, 32, [3, 3], scope='Conv2d_2a_3x3')
net = slim.conv2d(net, 64, [3, 3], padding='SAME', scope='Conv2d_2b_3x3')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_3a_3x3')
net = slim.conv2d(net, 80, [1, 1], scope='Conv2d_3b_1x1')
net = slim.conv2d(net, 192, [3, 3], scope='Conv2d_4a_3x3')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='MaxPool_5a_3x3')
'''
三个连续的Inception模块组,三个Inception模块组中各自分别有多个Inception Module,这部分是Inception Module V3
的精华所在。每个Inception模块组内部的几个Inception Mdoule结构非常相似,但是存在一些细节的不同
'''
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope('Mixed_5b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 32, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
'''
因为这里所有层步长均为1,并且padding模式为SAME,所以图片尺寸不会缩小,但是通道数增加了。四个分支通道数之和
64+64+96+32=256,最终输出的tensor的图片尺寸为35*35*256。
第一个模块组所有Inception Module输出图片尺寸都是35*35,但是后两个输出通道数会发生变化。
'''
with tf.variable_scope('Mixed_5c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0b_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv_1_0c_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_5d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 48, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [5, 5], scope='Conv2d_0b_5x5')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 64, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_6a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 384, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_1x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3)
with tf.variable_scope('Mixed_6b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 128, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 128, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 128, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 128, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_6c'):
with tf.variable_scope('Branch_0'):
'''
我们的网络每经过一个inception module,即使输出尺寸不变,但是特征都相当于被重新精炼了一遍,
其中丰富的卷积和非线性化对提升网络性能帮助很大。
'''
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_6d'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 160, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 160, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 160, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 160, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_6e'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 192, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
end_points['Mixed_6e'] = net
with tf.variable_scope('Mixed_7a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 320, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 192, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 192, [7, 1], scope='Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 192, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
net = tf.concat([branch_0, branch_1, branch_2], 3)
with tf.variable_scope('Mixed_7b'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0b_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
with tf.variable_scope('Mixed_7c'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 320, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat([
slim.conv2d(branch_1, 384, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 384, [3, 1], scope='Conv2d_0c_3x1')], 3)
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(net, 448, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(
branch_2, 384, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = tf.concat([
slim.conv2d(branch_2, 384, [1, 3], scope='Conv2d_0c_1x3'),
slim.conv2d(branch_2, 384, [3, 1], scope='Conv2d_0d_3x1')], 3)
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(net, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(
branch_3, 192, [1, 1], scope='Conv2d_0b_1x1')
net = tf.concat([branch_0, branch_1, branch_2, branch_3], 3)
return net, end_points
'''
设计inception net的重要原则是图片尺寸不断缩小,inception模块组的目的都是将空间结构简化,同时将空间信息转化为
高阶抽象的特征信息,即将空间维度转为通道的维度。降低了计算量。Inception Module是通过组合比较简单的特征
抽象(分支1)、比较比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共四种不同程度的
特征抽象和变换来有选择地保留不同层次的高阶特征,这样最大程度地丰富网络的表达能力。
'''
def inception_v3(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.8,
prediction_fn=slim.softmax,
spatial_squeeze=True,
reuse=None,
scope='InceptionV3'):
with tf.variable_scope(scope, 'InceptionV3', [inputs, num_classes],
reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = inception_v3_base(inputs, scope=scope)
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
aux_logits = end_points['Mixed_6e']
with tf.variable_scope('AuxLogits'):
aux_logits = slim.avg_pool2d(
aux_logits, [5, 5], stride=3, padding='VALID',
scope='AvgPool_1a_5x5')
aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
scope='Conv2d_1b_1x1')
aux_logits = slim.conv2d(
aux_logits, 768, [5,5],
weights_initializer=trunc_normal(0.01),
padding='VALID', scope='Conv2d_2a_5x5')
aux_logits = slim.conv2d(
aux_logits, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, weights_initializer=trunc_normal(0.001),
scope='Conv2d_2b_1x1')
if spatial_squeeze:
aux_logits = tf.squeeze(aux_logits, [1, 2], name='SpatialSqueeze')
end_points['AuxLogits'] = aux_logits
with tf.variable_scope('Logits'):
net = slim.avg_pool2d(net, [8, 8], padding='VALID',
scope='AvgPool_1a_8x8')
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
end_points['PreLogits'] = net
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='Conv2d_1c_1x1')
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
ResNet
class ResNet(object):
def __init__(self, hps, images, labels, mode):
self.hps = hps
self._images = images
self.labels = labels
self.mode = mode
self._extra_train_ops = []
def build_graph(self):
self.global_step = tf.contrib.framework.get_or_create_global_step()
self._build_model()
if self.mode == 'train':
self._build_train_op()
self.summaries = tf.summary.merge_all()
def _build_model(self):
with tf.variable_scope('init'):
x = self._images
"""第一层卷积(3,3x3/1,16)"""
x = self._conv('init_conv', x, 3, 3, 16, self._stride_arr(1))
strides = [1, 2, 2]
activate_before_residual = [True, False, False]
if self.hps.use_bottleneck:
res_func = self._bottleneck_residual
filters = [16, 64, 128, 256]
else:
res_func = self._residual
filters = [16, 16, 32, 64]
with tf.variable_scope('unit_1_0'):
x = res_func(x, filters[0], filters[1],
self._stride_arr(strides[0]),
activate_before_residual[0])
for i in six.moves.range(1, self.hps.num_residual_units):
with tf.variable_scope('unit_1_%d' % i):
x = res_func(x, filters[1], filters[1], self._stride_arr(1), False)
with tf.variable_scope('unit_2_0'):
x = res_func(x, filters[1], filters[2],
self._stride_arr(strides[1]),
activate_before_residual[1])
for i in six.moves.range(1, self.hps.num_residual_units):
with tf.variable_scope('unit_2_%d' % i):
x = res_func(x, filters[2], filters[2], self._stride_arr(1), False)
with tf.variable_scope('unit_3_0'):
x = res_func(x, filters[2], filters[3], self._stride_arr(strides[2]),
activate_before_residual[2])
for i in six.moves.range(1, self.hps.num_residual_units):
with tf.variable_scope('unit_3_%d' % i):
x = res_func(x, filters[3], filters[3], self._stride_arr(1), False)
with tf.variable_scope('unit_last'):
x = self._batch_norm('final_bn', x)
x = self._relu(x, self.hps.relu_leakiness)
x = self._global_avg_pool(x)
with tf.variable_scope('logit'):
logits = self._fully_connected(x, self.hps.num_classes)
self.predictions = tf.nn.softmax(logits)
with tf.variable_scope('costs'):
xent = tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=self.labels)
self.cost = tf.reduce_mean(xent, name='xent')
self.cost += self._decay()
tf.summary.scalar('cost', self.cost)
def _build_train_op(self):
self.lrn_rate = tf.constant(self.hps.lrn_rate, tf.float32)
tf.summary.scalar('learning_rate', self.lrn_rate)
trainable_variables = tf.trainable_variables()
grads = tf.gradients(self.cost, trainable_variables)
if self.hps.optimizer == 'sgd':
optimizer = tf.train.GradientDescentOptimizer(self.lrn_rate)
elif self.hps.optimizer == 'mom':
optimizer = tf.train.MomentumOptimizer(self.lrn_rate, 0.9)
apply_op = optimizer.apply_gradients(
zip(grads, trainable_variables),
global_step=self.global_step,
name='train_step')
train_ops = [apply_op] + self._extra_train_ops
self.train_op = tf.group(*train_ops)
def _stride_arr(self, stride):
return [1, stride, stride, 1]
def _residual(self, x, in_filter, out_filter, stride, activate_before_residual=False):
if activate_before_residual:
with tf.variable_scope('shared_activation'):
x = self._batch_norm('init_bn', x)
x = self._relu(x, self.hps.relu_leakiness)
orig_x = x
else:
with tf.variable_scope('residual_only_activation'):
orig_x = x
x = self._batch_norm('init_bn', x)
x = self._relu(x, self.hps.relu_leakiness)
with tf.variable_scope('sub1'):
x = self._conv('conv1', x, 3, in_filter, out_filter, stride)
with tf.variable_scope('sub2'):
x = self._batch_norm('bn2', x)
x = self._relu(x, self.hps.relu_leakiness)
x = self._conv('conv2', x, 3, out_filter, out_filter, [1, 1, 1, 1])
with tf.variable_scope('sub_add'):
if in_filter != out_filter:
orig_x = tf.nn.avg_pool(orig_x, stride, stride, 'VALID')
orig_x = tf.pad(orig_x,
[[0, 0],
[0, 0],
[0, 0],
[(out_filter-in_filter)//2, (out_filter-in_filter)//2]
])
x += orig_x
tf.logging.debug('image after unit %s', x.get_shape())
return x
def _bottleneck_residual(self, x, in_filter, out_filter, stride,
activate_before_residual=False):
if activate_before_residual:
with tf.variable_scope('common_bn_relu'):
x = self._batch_norm('init_bn', x)
x = self._relu(x, self.hps.relu_leakiness)
orig_x = x
else:
with tf.variable_scope('residual_bn_relu'):
orig_x = x
x = self._batch_norm('init_bn', x)
x = self._relu(x, self.hps.relu_leakiness)
with tf.variable_scope('sub1'):
x = self._conv('conv1', x, 1, in_filter, out_filter/4, stride)
with tf.variable_scope('sub2'):
x = self._batch_norm('bn2', x)
x = self._relu(x, self.hps.relu_leakiness)
x = self._conv('conv2', x, 3, out_filter/4, out_filter/4, [1, 1, 1, 1])
with tf.variable_scope('sub3'):
x = self._batch_norm('bn3', x)
x = self._relu(x, self.hps.relu_leakiness)
x = self._conv('conv3', x, 1, out_filter/4, out_filter, [1, 1, 1, 1])
with tf.variable_scope('sub_add'):
if in_filter != out_filter:
orig_x = self._conv('project', orig_x, 1, in_filter, out_filter, stride)
x += orig_x
tf.logging.info('image after unit %s', x.get_shape())
return x
def _batch_norm(self, name, x):
with tf.variable_scope(name):
params_shape = [x.get_shape()[-1]]
beta = tf.get_variable('beta',
params_shape,
tf.float32,
initializer=tf.constant_initializer(0.0, tf.float32))
gamma = tf.get_variable('gamma',
params_shape,
tf.float32,
initializer=tf.constant_initializer(1.0, tf.float32))
if self.mode == 'train':
mean, variance = tf.nn.moments(x, [0, 1, 2], name='moments')
moving_mean = tf.get_variable('moving_mean',
params_shape, tf.float32,
initializer=tf.constant_initializer(0.0, tf.float32),
trainable=False)
moving_variance = tf.get_variable('moving_variance',
params_shape, tf.float32,
initializer=tf.constant_initializer(1.0, tf.float32),
trainable=False)
self._extra_train_ops.append(moving_averages.assign_moving_average(
moving_mean, mean, 0.9))
self._extra_train_ops.append(moving_averages.assign_moving_average(
moving_variance, variance, 0.9))
else:
mean = tf.get_variable('moving_mean',
params_shape, tf.float32,
initializer=tf.constant_initializer(0.0, tf.float32),
trainable=False)
variance = tf.get_variable('moving_variance',
params_shape, tf.float32,
initializer=tf.constant_initializer(1.0, tf.float32),
trainable=False)
tf.summary.histogram(mean.op.name, mean)
tf.summary.histogram(variance.op.name, variance)
y = tf.nn.batch_normalization(x, mean, variance, beta, gamma, 0.001)
y.set_shape(x.get_shape())
return y
def _decay(self):
costs = []
for var in tf.trainable_variables():
if var.op.name.find(r'DW') > 0:
costs.append(tf.nn.l2_loss(var))
return tf.multiply(self.hps.weight_decay_rate, tf.add_n(costs))
def _conv(self, name, x, filter_size, in_filters, out_filters, strides):
with tf.variable_scope(name):
n = filter_size * filter_size * out_filters
kernel = tf.get_variable(
'DW',
[filter_size, filter_size, in_filters, out_filters],
tf.float32,
initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0/n)))
return tf.nn.conv2d(x, kernel, strides, padding='SAME')
def _relu(self, x, leakiness=0.0):
return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
def _fully_connected(self, x, out_dim):
x = tf.reshape(x, [self.hps.batch_size, -1])
w = tf.get_variable('DW', [x.get_shape()[1], out_dim],
initializer=tf.uniform_unit_scaling_initializer(factor=1.0))
b = tf.get_variable('biases', [out_dim], initializer=tf.constant_initializer())
return tf.nn.xw_plus_b(x, w, b)
def _global_avg_pool(self, x):
assert x.get_shape().ndims == 4
return tf.reduce_mean(x, [1, 2])






















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









